Improving Speech Prosody of Audiobook Text-to-Speech Synthesis with Acoustic and Textual Contexts
오디오북을 들을 때, 각 캐릭터의 목소리가 상황에 맞게 전달되고, 장면의 분위기에 맞춰 목소리 톤이 자연스럽게 바뀌는 것을 상상해보고는 합니다. 이는 오디오북 애호가라면 누구나 바라는 장면입니다. 이제 텍스트-음성 변환(TTS) 기술의 발전 덕분에 이러한 꿈이 현실에 한 걸음 더 가까워지고 있습니다. 이번 글에서는 음향 문맥과 텍스트 문맥을 함께 활용해, 합성 음성의 자연스러움, 특히 억양(말의 높낮이와 리듬)을 크게 개선한 새로운 다중 화자 일본어 오디오북 TTS 시스템을 소개하고자 합니다.
1. 억양이 왜 중요한가?
사람이 대화를 나누거나 이야기를 읽을 때 억양은 매우 중요한 역할을 합니다. 억양은 말의 감정, 분위기, 그리고 의미를 전달하는 핵심 요소 중 하나입니다. 예를 들어, “정말 기뻐!”라는 문장을 억양에 따라 다르게 표현하면 진짜 기쁨을 전달할 수도 있고, 반대로 비꼬는 듯한 느낌을 줄 수도 있습니다. 하지만 기존의 TTS 시스템은 이런 억양을 자연스럽게 구현하는 데 한계가 있었습니다. 특히, 여러 캐릭터가 등장하고 감정 변화가 자주 발생하는 오디오북처럼 억양이 복잡한 음성을 합성하는 데 어려움을 겪었습니다.
2. 음향과 텍스트 문맥을 어떻게 활용하는가?
기존 TTS 시스템은 대개 단일 문장의 정보만을 사용하여 음성을 합성합니다. 하지만 오디오북처럼 여러 문장이 연속적으로 이어질 때는 문맥이 중요합니다. 예를 들어, 앞 문장에서 캐릭터가 기쁜 목소리로 말했다면, 다음 문장에서도 비슷한 감정이 유지되어야 합니다. 또한, 텍스트 문맥에서 “그가 화난 목소리로 말했다”라는 구절이 있다면, 이에 맞는 억양을 사용해야 자연스럽습니다.
이를 해결하기 위해 제안된 새로운 TTS 시스템에서는 음향 문맥과 텍스트 문맥을 모두 사용하여 더욱 자연스러운 억양을 생성합니다. 여기서 음향 문맥은 앞 문장의 음성 정보를 분석해 현재 문장에서 이어질 억양을 예측하고, 텍스트 문맥은 BERT라는 인공지능 모델을 사용해 앞뒤 텍스트의 맥락을 분석한 후 적절한 억양을 예측합니다.
ACE(음향 문맥 인코더)
음향 문맥 인코더(ACE)는 이전 문장에서 발화된 음성 정보를 분석하여, 현재 발화의 억양을 더욱 자연스럽게 연결해 주는 역할을 합니다. 예를 들어, 오디오북에서는 여러 문장이 연속되기 때문에, 앞 문장의 억양이 뒤 문장의 억양에도 영향을 미치는 경우가 많습니다. ACE는 이러한 이전 문장의 멜-스펙트로그램(음성의 시각적 표현)을 인코딩하여, 그 정보를 바탕으로 현재 문장에 적절한 억양을 부여합니다.
ACE는 학습 시 이전 문장의 실제 음성 데이터(즉, 실제 멜-스펙트로그램)를 사용하지만, 실제로 음성을 합성할 때는 이전에 합성된 음성을 사용해 문맥을 분석합니다. 이를 통해 연속된 문장 사이의 억양이 자연스럽게 이어질 수 있도록 돕습니다. 또한, ACE는 추가적인 학습을 통해 이전 문장과 현재 문장 사이의 관계를 학습합니다. 이 작업은 L1 손실 함수를 통해 ACE가 앞 문장의 음성 정보를 잘 반영할 수 있도록 하는 역할을 합니다.
TCE(텍스트 문맥 인코더)
텍스트 문맥 인코더(TCE)는 텍스트의 앞뒤 문맥을 분석해, 해당 문장에서 필요한 억양을 예측하는 중요한 역할을 합니다. 예를 들어, 문장 앞부분에서 “그는 화난 목소리로 말했다”라는 표현이 있다면, 그 뒤에 나오는 문장은 화난 억양을 가져야 합니다. 이처럼 텍스트 문맥을 통해 감정 표현이나 상황에 맞는 억양을 예측할 수 있습니다.
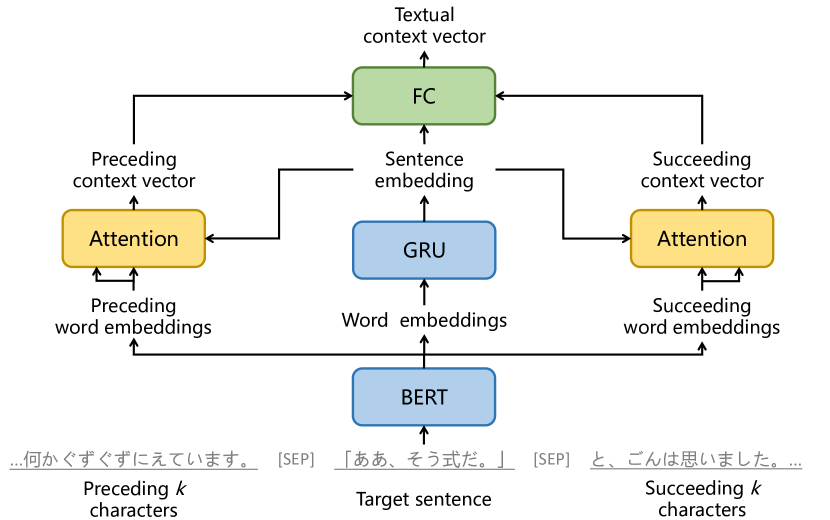
TCE는 BERT라는 인공지능 모델을 사용하여 양방향 텍스트 문맥을 인코딩합니다. 양방향 문맥이란, 앞 문장뿐만 아니라 다음에 나올 문장까지 고려하여 현재 문장의 억양을 결정하는 것입니다. 이를 통해 더욱 정확하고 자연스러운 억양을 구현할 수 있습니다. 예를 들어, 앞 문장에서 즐거운 감정을 표현하고, 뒤 문장에서 긴장감을 유발하는 내용이 등장할 경우, 현재 문장은 그 두 감정을 적절히 반영하는 억양을 가지게 됩니다.
TCE는 또한 문장의 단어 임베딩을 분석한 후, 문장의 앞뒤 문맥에서 얻은 정보를 바탕으로 어텐션 메커니즘을 적용해 문맥 간의 관계를 학습합니다. 이를 통해 텍스트의 맥락을 고려한 자연스러운 음성을 생성할 수 있습니다.
3. 제안된 시스템의 구성

이 시스템은 크게 세 가지 핵심 요소로 구성되어 있습니다:
- 음향 문맥 인코더(ACE): 이전에 발화된 음성 데이터를 분석하여 연속된 발화 사이의 일관성을 유지하는 역할을 합니다.
- 텍스트 문맥 인코더(TCE): 텍스트의 앞뒤 문맥을 분석하여 적절한 억양을 예측합니다. 특히, 텍스트에서 “화난 목소리로”, “기쁘게” 같은 단서들을 찾아 억양을 결정하는 데 중요한 정보를 제공합니다.
- FastSpeech2 기반 TTS 모델: 이 모델은 음소(발음 단위)를 인코딩하고, 문맥 정보를 바탕으로 멜-스펙트로그램(음성을 시각적으로 표현한 그래프)을 생성해 최종적으로 음성을 합성합니다.
4. 실험 결과
이번 연구에서 제안된 시스템을 통해 더 자연스럽고 문맥에 맞는 억양을 가진 음성을 합성할 수 있다는 점을 확인했습니다. 다양한 실험을 통해 음향 문맥과 텍스트 문맥을 모두 활용했을 때, 기존 방식보다 훨씬 자연스러운 억양을 구현할 수 있었습니다.
텍스트 문맥의 길이와 억양의 관계
특히, 텍스트 문맥의 길이가 억양 예측에 중요한 영향을 미친다는 사실을 발견했습니다. 텍스트 문맥이 너무 짧으면 충분한 정보를 제공하지 못하지만, 문맥이 지나치게 길면 오히려 성능이 떨어졌습니다. 실험 결과, 앞뒤로 2~3문장 정도의 텍스트 문맥을 활용했을 때 가장 적절한 억양을 예측할 수 있었습니다. 이는 오디오북에서 연속된 문장이 서로 자연스럽게 이어지기 위해서는 적정한 문맥 길이가 필요하다는 사실을 보여줍니다.
후속 문맥의 효과
또한 흥미롭게도, 후속 텍스트 문맥이 억양을 예측하는 데 중요한 역할을 한다는 점도 확인했습니다. 앞 문장의 정보뿐만 아니라 다음에 나올 문장의 정보도 억양을 결정하는 데 영향을 미쳤습니다. 예를 들어, 앞 문장에서 화난 목소리를 사용했더라도, 뒤 문장에서 분위기가 달라진다면 현재 문장의 억양이 그에 맞춰 바뀌어야 합니다. 이처럼 앞뒤 문맥을 모두 활용하는 것이 억양을 자연스럽게 만드는 데 매우 효과적임을 알 수 있었습니다.
다양한 문맥 정보의 결합
제안된 시스템에서는 음향 문맥과 텍스트 문맥을 결합하여 더 정확한 억양을 예측할 수 있었습니다. 기존 연구들은 주로 한 가지 정보만을 활용하거나, 제한된 문맥 길이로 억양을 예측했지만, 이번 연구에서는 다양한 문맥 정보를 함께 사용하여 더 자연스러운 음성을 합성하는 데 성공했습니다. 특히, 텍스트 문맥과 음향 문맥을 동시에 활용했을 때, 억양이 더욱 일관되게 유지되었습니다.
5. 결론
이번 연구에서는 음향 문맥과 텍스트 문맥을 결합해 오디오북 TTS 시스템의 억양을 자연스럽게 개선하는 방법을 제안했습니다. 실험 결과, 제안된 시스템은 기존 방식보다 객관적 및 주관적 평가에서 뛰어난 성능을 보였으며, 특히 후속 문맥이 억양 예측에 중요한 역할을 한다는 점을 확인했습니다. 최적의 텍스트 문맥 길이는 2~3문장으로 나타났으며, 이를 통해 문맥 정보를 적절히 활용하는 것이 TTS 성능을 크게 향상시킬 수 있음을 입증했습니다.