AutoRec
AutoRec: Autoencoders Meet Collaborative Filtering
- ACM 2015
- Suvash Sedhain, Aditya Krishna Menon, Scott Sanner, Lexing Xie
1. Introduction
추천시스템의 대표적인 적용 분야인 영화 평점예측에서 과거에는 Netflix prize 대회에서 우승한 방법론인 matrix factorization을 사용하거나 응용한 모델들이 주를 이루고 있었다. 하지만 이번 논문에서는 평점을 예측하는 새로운 패러다임인 AutoRec을 소개하며, auto encoder를 추천시스템에 적용시킨 방법에 대해서 소개한다. 저자들이 주장하기를, AutoRec 모델은 collaborative filtering 모델과 달리 모델 자체의 표현력과 추천 성능 또한 뛰어나다고 말한다.
2. The AutoRec Model
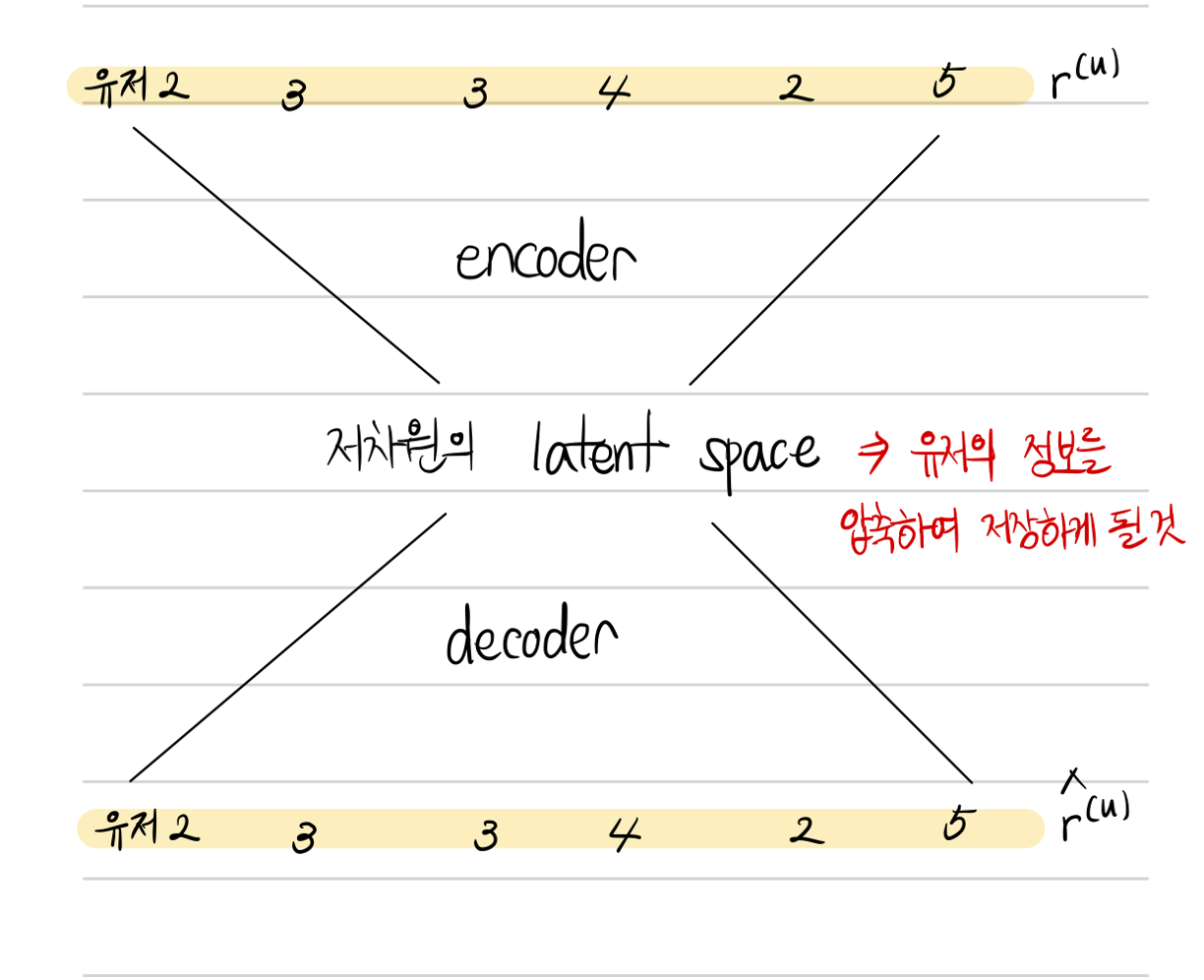
Rating 을 사용하는 협업 필터링 (collaborative filtering)은 입력 데이터셋으로 유저와 아이템을 행과 열로 하는 평점 행렬 $\mathbb{R}^{m \times n}$을 사용한다. 전체 유저의 수를 $m$이라고 하고, $n$은 전체 아이템 (영화)의 수를 나타낸다. AutoRec 모델은 위의 행렬에서 하나의 행 (유저의 정보) 또는 하나의 열 (영화의 정보)을 사용하여 저차원의 잠재공간에 임베딩시키고, 임베딩된 정보를 사용하여 다시 원래의 벡터를 복원시키는 것을 목표로 한다.
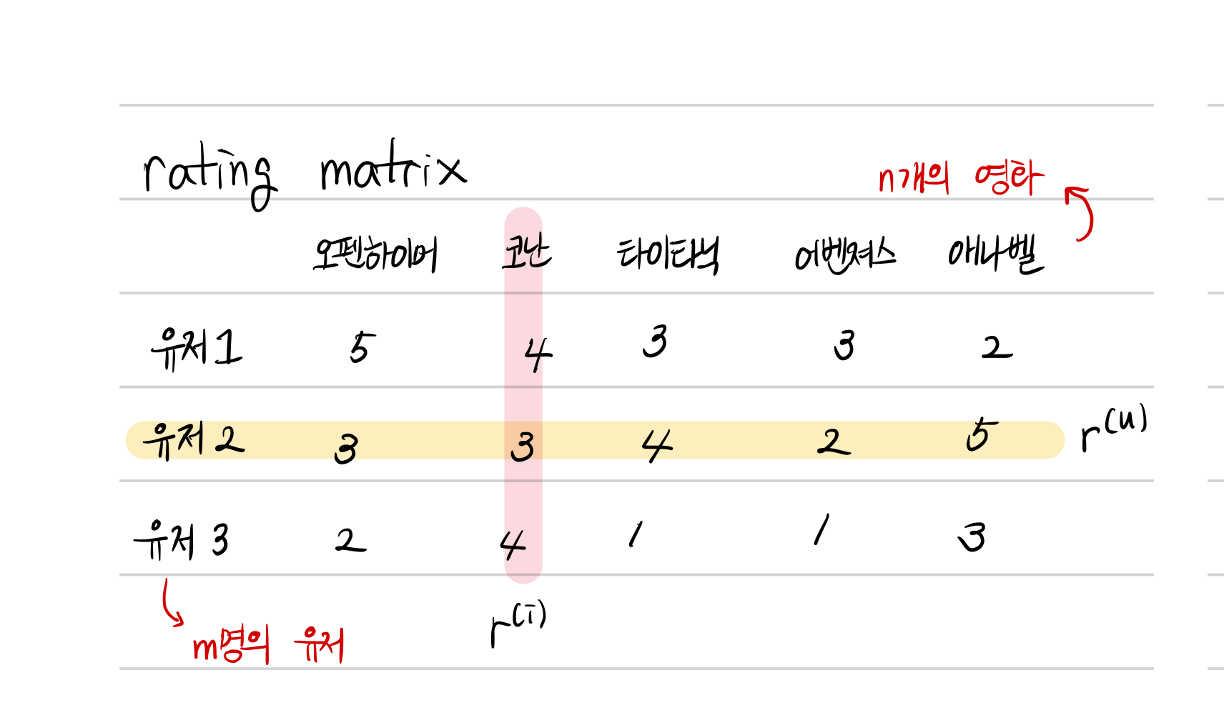
위의 평점 행렬에서 하나의 행 또는 하나의 열을 기준으로 하여 데이터를 하나씩 추출하고, autorec 모델의 입력을 준비한다. Autorec모델은 입력을 받아 다시 입력을 복원시키는 구조를 갖고 있고, 중간의 저차원의 잠재벡터가 입력 데이터의 특징들을 요약하고 있을 것이라는 목표를 세우고 학습을 시작한다. 학습의 목적함수는 입력과 출력의 차이를 줄이도록 진행된다.
- $\mathbf{r}$ : $d$ 차원을 갖는 입력 벡터
- $\mathbf{S}$ : 입력 벡터 $\mathbf{r}$의 집합
- $f(\cdot), g(\cdot)$ : 활성 함수
- $\mathbf{W}$ : $d \times k$ 차원의 transformation 행렬 (decoder)
- $\mathbf{V}$: $k \times d$ 차원의 transformation 행렬 (encoder)
- $\mathbf{\mu} \in \mathbb{R}^k, \mathbf{b} \in \mathbb{R}^d$ : bias
위의 전체 과정을 수식으로 나타내면, 입력 벡터에 대해 저차원 공간으로 투영시키는 행렬 $\mathbf{V}$와 저차원 공간에서 원래의 공간으로 투영시키는 행렬 $\mathbf{W}$가 사용된다. 논문에서 소개되는 그림에 의하면, transformation에 사용되는 행렬에 필요한 bias 값까지 표현된 것을 확인할 수 있다.
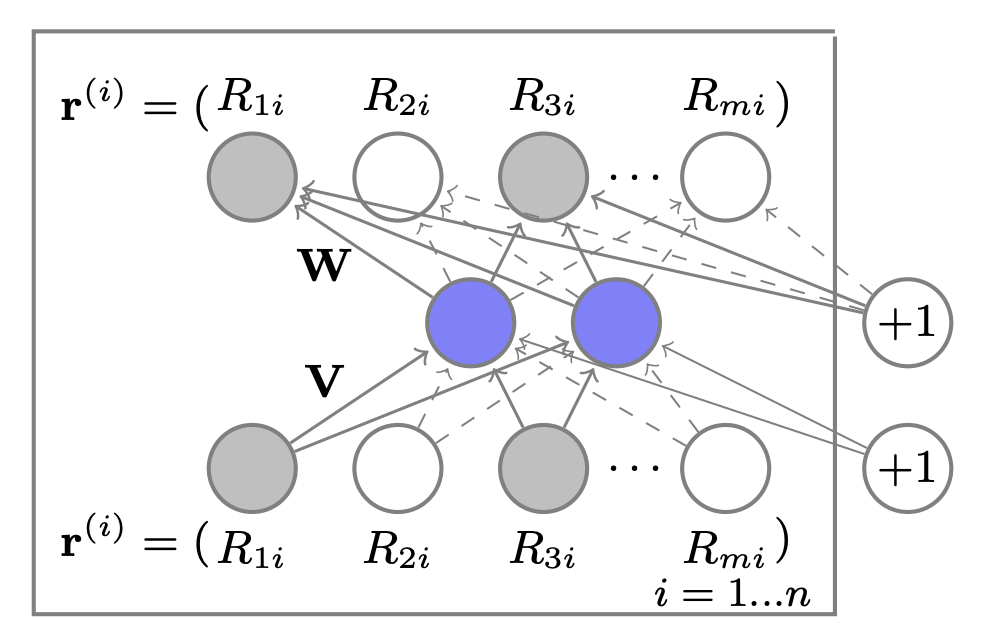
위 사진은 아이템 (영화)를 기준으로 구성한 데이터셋을 입력으로 하는 모델 구조이다. 입력으로 들어가는 벡터는 $[ \mathbf{r}^{(i)} ]_{i=1}^n$ 이며, autoencoder를 적용할 때 2가지 주요한 변화가 있다고 말한다.
Matrix factorization 모델이나 RBM과 같이 파라미터를 업데이트 할 때 평점 데이터가 존재하는 입력에 대한 가중치만 업데이를 진행한다. (입력 벡터의 rating 값이 존재하는 index에 대해서만 업데이트를 진행)
학습 파라미터에 $\ell_2$ regularization을 적용하여 관측된 평점에 대해서만 과적합 되는 현상을 방지한다.
위의 2가지 변화를 모두 반영하여 AutoRec의 목적함수를 수식으로 작성하면 다음과 같다.
\[\tag{2} \min_\theta \sum_{i=1}^n \|\mathbf{r}^{(i)} - h(\mathbf{r}^{(i)}; \theta) \|_{\mathcal{O}}^2 + \frac{\lambda}{2} \cdot (\| \mathbf{W} \|_F^2 + \|\mathbf{V}\|_F^2)\]결과적으로, 모델에 필요한 전체 파라미터의 수는 bias 벡터를 포함하여 $2mk + m + k$개 이다. 논문에서 제공한 이미지에서 점선으로 표현된 화살표는 관측된 데이터를 말하며, 실선으로 표시된 화살표는 입력 $\mathbf{r}^{(i)}$에 의해 가중치가 업데이트 되는 것을 의미한다.
3. Experimental Evaluation
이번에는 모델의 성능을 평가한 방법과 그 결과에 대해 소개하는 파트이며 데이터셋으로는 유명한 movielens dataset과 netflix dataset을 사용하였다. 추가로, 모델에 생기는 몇 가지 궁금증들을 실험을 통해 풀어낸 결과까지 함께 설명한다. AutoRec 모델의 성능 평가를 위해 비교군으로 사용된 모델은 RBM-CF, BiasedMF, LLORMA이다.

주로 수정한 하이퍼파라미터는 $\ell_2$ regularization의 정도를 조절하는 $\lambda$값과 저차원 잠재 벡터의 차원인 $k$를 조절하였다. 모델의 결과로 평가하면, 아이템을 기준으로 AutoRec 모델을 돌렸을 때, 다른 RBM 기반 모델들보다 더 우월한 결과를 보여주었다. 또한, 활성함수의 사용이 실제 모델의 성능을 증가시키는데 크게 기여를 하고 있음을 위의 표 (b)에서 알려준다.
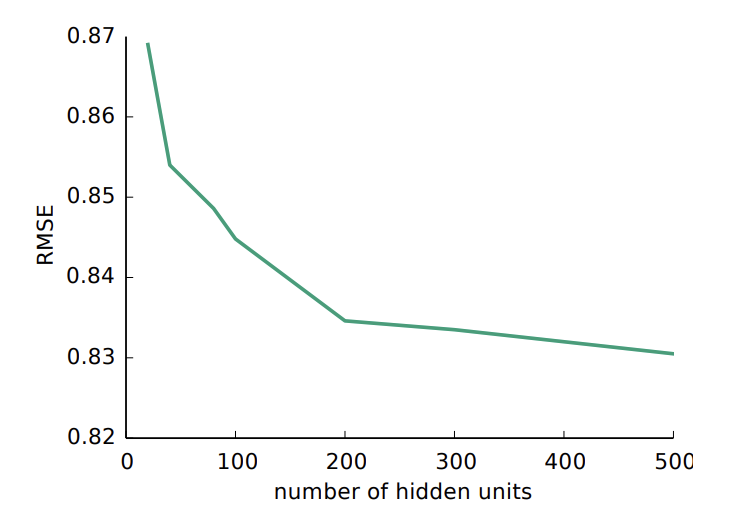
가장 궁금했던 부분 중 하나인, 잠재벡터의 차원을 몇 으로 가져갈지에 대한 질문도 논문에서 실험을 통해 결과를 알려주었다. 여러가지 차원으로 실험해본 결과, $k$의 값이 증가할 수록 성능이 증가함을 보여주었지만, 500이 넘어가는 순간부터는 유의미한 차이가 없었다고 밝혔다. 따라서 다른 모든 실험에서도 저차원 벡터의 차원을 500으로 설정하여 실험했다고 기술하였다.
4. References
Suvash Sedhain, Aditya Krishna Menon, Scott Sanner, and Lexing Xie. 2015. AutoRec: Autoencoders Meet Collaborative Filtering. In Proceedings of the 24th International Conference on World Wide Web (WWW ‘15 Companion). Association for Computing Machinery, New York, NY, USA, 111–112. https://doi.org/10.1145/2740908.2742726
Weisstein, Eric W. “Frobenius Norm.” From MathWorld–A Wolfram Web Resource. https://mathworld.wolfram.com/FrobeniusNorm.html