Deep Interest Network
Deep Interest Network for Click-Through Rate Prediction
- ACM 2018
- Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, Kun Gai
Abstract
DIN 모델이 발표되기 이전, 추천시스템에서는 주어진 데이터 속에 존재하는 다양한 feature 정보들을 활용하기 위해 임베딩을 사용하였다. 아주 sparse한 데이터를 모두 고정된 길이의 임베딩 벡터로 변환하고 feature 사이의 상호작용을 포착하기 위해 벡터들에 대해 concatentation을 하고 MLP를 통과하도록 만들었다. 하지만 문제는 고정된 길이의 벡터를 사용하게 되면서 raw 데이터 자체가 내포하고 있는 충분한 정보를 다 담지 못하게 될 수 있다.
이에 DIN 모델은 고정된 길이의 벡터 안에서 유저의 흥미(선호도)를 충분히 반영할 수 있도록 하고 싶었고, 유저에게 보여진 광고와 그에 따른 행동정보를 사용하는 방안을 떠올렸다. 다시 말하자면, 관심을 보인 상품 카테고리에 대해 더 많은 정보를 반영하도록 모델링하는 것이다.
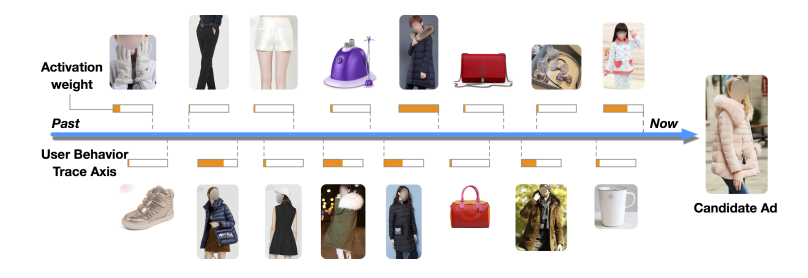
여기서 멈추지 않고, DIN에서는 mini-batch aware regularization과 data adaptive activation function이라는 2가지 기법을 활용하여 매우 큰 모델 파라미터의 효율적인 학습이 가능하도록 만드는 것에 성공하였다. 마지막으로 논문이 발표된 회사인 Alibaba의 20억개의 데이터를 사용하여 DIN의 뛰어난 성능을 증명해주었다.
1. Introduction
논문에서는 입력 데이터의 feature를 임베딩 벡터로 변환 후, concatentate하여 MLP를 통해 CTR을 예측하는 모델을 앞으로 Embedding&MLP 라고 부른다. Embedding&MLP 모델은 간단한 logistic regression 모델에 비해 feature engineering에 들어가는 노력을 크게 줄일 수 있고 비선형적 관계를 파악할 수 있기에 모델의 능력을 향상시키는 것이 가능했었다. 그러나, 임베딩 벡터로 변환하는 과정에서 고정된 길이의 벡터를 사용한다는 한계점이 존재하였고 이는 유저의 다양한 관심사를 모델링할 수 없어지는 문제를 초래하게 된다.
그렇다고 임베딩 벡터의 차원을 크게 늘리게 되면, 유저의 다양한 관심사를 모델링할 수는 있어도 계산해야하는 파라미터의 수를 늘려 모델 자체가 overfitting되기 쉽다는 위험성을 안게 된다. 모델의 복잡도 증가와 오버피팅사이의 관계는 아래 Dive in to deep learning 게시글에서 확인할 수 있다.
언더피팅과 오버피팅 - Dive in to deep learning
다른 방법으로 생각해보던 연구팀은 유저의 모든 관심사들이 동일하게 임베딩될 필요는 전혀없고, 유저가 관심을 많이 갖는 feature를 많이 반영하도록 임베딩시키면 되겠다는 생각을 한다. 마치 Transformer에서 attention score를 계산하는 것과 비슷하게 느껴졌으며 논문에서는 이를 activation unit을 통해 계산한다고 발표하였다. 이 아이디어로부터 출발하여 저자는 Deep Interest Network (DIN)이라는 모델을 발표한다.
2. Related work
- NNLM
- 각 단어에 대한 벡터의 표현을 학습하는 임베딩을 소개하였으며 덕분에 sparse한 데이터셋을 입력으로 다룰 수 있게 되었다.
- LS-PLM & FM
- 임베딩을 사용하여 처음으로 CTR 예측을 했던 모델로, feature 간의 관계를 파악하기 위해 1개의 hidden layer가 존재하는 transformation function을 사용하였다.
- Deep crossing & Wide and Deep & YouTube Recommendation
- LS-PLM과 FM에서 transformation function을 복잡한 MLP로 대체하여 모델의 성능을 개선시키려고 노력하였다.
- PNN
- feature 사이의 high-order connectivity를 학습하기 위해 임베딩 이후, production layer를 두었다.
- DeepFM
- 별도의 feature engineering 과정을 두지 않는 Wide & Deep 에서 FM모델을 Wide 파트로 두어 구성한 모델이다.
전반적으로 위의 방법 모두 임베딩 레이어와 MLP 레이어를 거치게 하여 모델을 구성하였고, 앞서 말했듯이 데이터가 내포한 충분한 정보를 반영하지 못할 수 있다는 문제가 발생하게 된다. 여기에 저자는 NMT에서 발표한 attention 메커니즘을 소개하며 이를 광고와 유저의 행동 사이에 적용해 둘 사이에 얼마나 관련이 있는지 계산하는 local activation unit을 고안하였다고 말했다.
3. Deep Interest Network
3.1 Feature representation
CTR 예측을 위해 산업에서 사용하고 있는 데이터들은 주로 multi-group category 형식을 띄고 있다. 예를 들자면 아래와 같다.
[weekday=Friday, gender=Female, visited_cate_ids={Bag,Book}, ad_cate_id=Book]
각각의 feature들은 먼저 숫자형식으로 표현하기 위해 고차원의 원핫 벡터 또는 멀티핫 벡터로 변환된다. 이를 논문의 표현을 빌려 수식으로 나타내면, $\mathbf{t}_{i} \in \mathbb{R}^{K_{i}}$로 작성하고, $K_{i}$ 는 feature $i$ 의 차원을 말한다. 만약 $\sum_{j=1}^{K_i} \mathbf{t}_{i}[j]= 1$ 이라면 원핫벡터를, $\sum_{j=1}^{K_{i}} \mathbf{t}_{i}[j] > 1$ 이라면 멀티핫 벡터이다. 이로서 아래와 같이 하나의 데이터 행을 숫자로 변환하는데 성공하였다.
\[\mathbf{x} = [\mathbf{t}_1^\top, \mathbf{t}_2^\top, \dots, \mathbf{t}_M^\top]^\top\] \[\underbrace{[0, 0, 0, 0, 1, 0, 0] }_{\text{weekday=Friday}} \underbrace{[0, 1]}_{\text{gender=Female}} \;\underbrace{[0, .., 1, ..., 1, ...0]}_{\text{visited_cate_ids=\{Bag, Book\}}} \; \underbrace{[0, .., 1, ..., 0]}_{\text{ad_cate_id=Book}}\]3.2 Base model (Embedding & MLP)
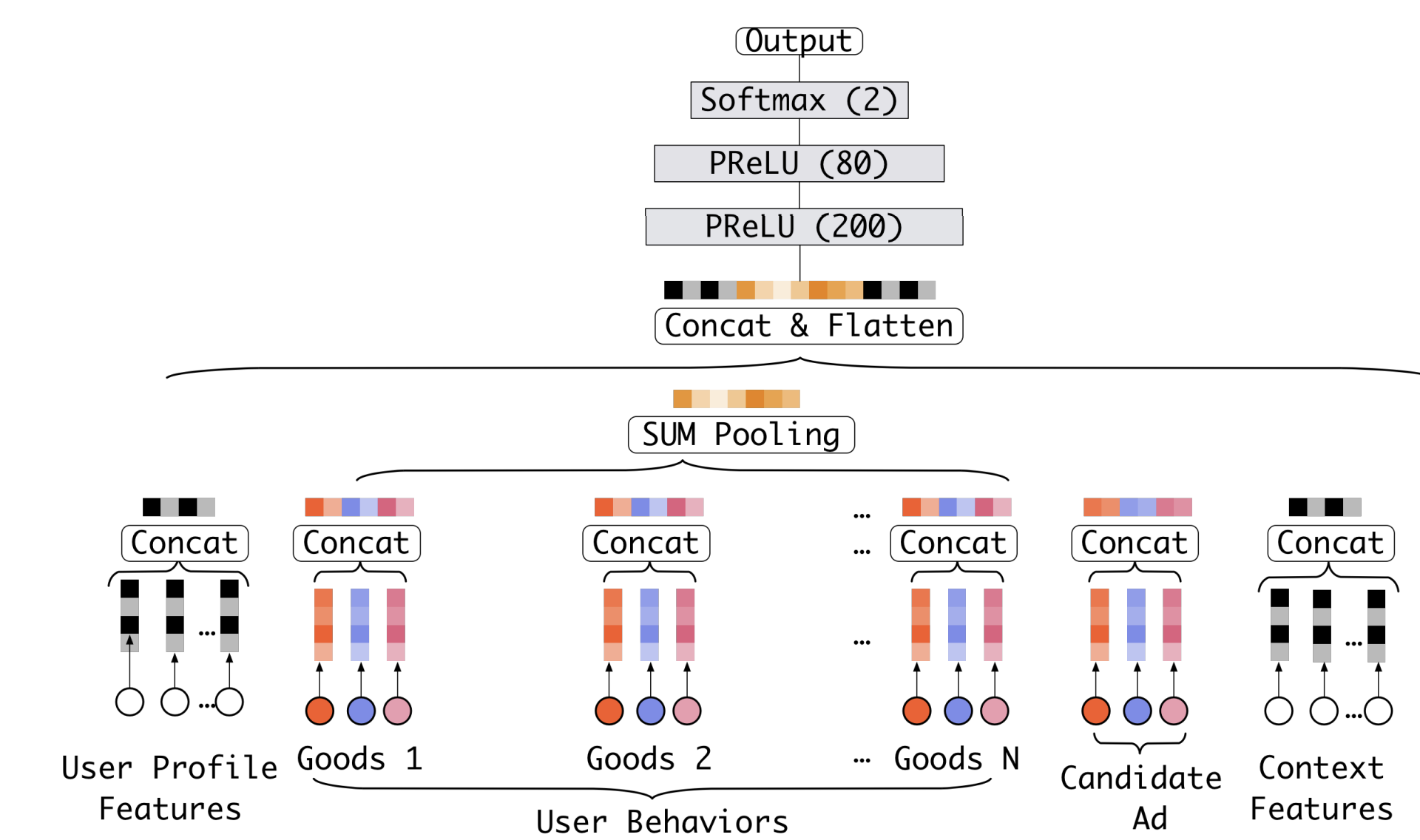
대부분의 base model은 위처럼 embedding&MLP로 구성되어 있고, 이번에는 더 상세하게 어떤 연산을 수행하는지 살펴보려고 한다.
- Embedding layer
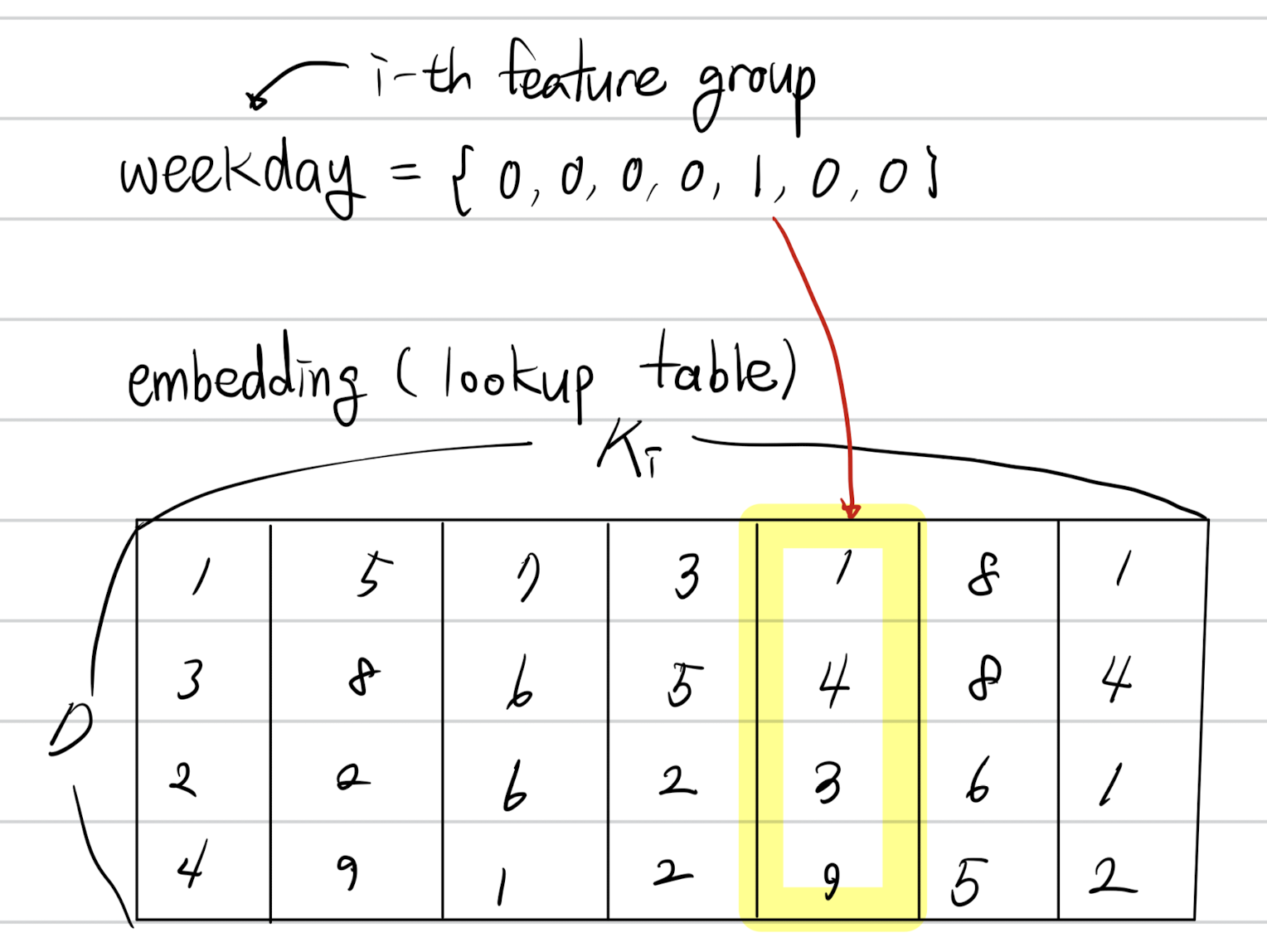
- 임베딩 레이어에서는 입력으로 들어오는 매우 sparse한 고차원의 원핫벡터 또는 멀티핫벡터를 저차원의 dense representation으로 변환해주는 작업을 한다. 현재 데이터의 $i$번째 feature인 $\mathbf{t}_i$에 대해서 $\mathbf{W}^i = [w_1^i, w_2^i, \dots, w_{K_i}^i] \in \mathbb{R}^{D \times K_i}$ 는 각 값에 맞는 벡터 값을 가져오는 lookup table로 간주한다. (임베딩 벡터의 크기는 $D$로 설정)
원핫 벡터인 경우 $j$ 번째의 원소 값이 1이라면 $w_j^i$ 의 값을 임베딩 벡터로 사용한다. 반면, 멀티핫 벡터인 경우 원소 값이 1인 모든 벡터를 가져와 묶음을 임베딩 벡터로 사용한다.
- Pooling layer and Concat layer
- 위에서 한가지 의문이 드는 것은 멀티핫 벡터인 경우, 임베딩 벡터의 개수가 가변적이기 때문에 길이를 어떻게 맞춰줄지 궁금하였다. 이에 논문에서는 일반적인 방법과 같이 pooling layer를 두어 고정된 길이의 벡터로 만들어 fully connected networks로 전달하였다. 멀티핫 벡터의 수가 $k$ 이라면, 아래의 수식처럼 표현한다. \[\tag{1} \mathbf{e}_i = \text{pooling}(\mathbf{e}_{i_1}, \mathbf{e}_{i_2}, \dots, \mathbf{e}_{i_k})\]
pooling에 사용하는 주요 기법은 sum pooling과 average pooling 이다. Feature group 내에서 element-wise 하게 연산이 진행되고, 모든 연산 이후 임베딩 벡터들은 모두 concatenation 되며 데이터 준비가 마무리 된다.
- MLP
- Fully connected layer에서는 feature 사이의 조합을 파악하는 역할을 하며, 최근에는 더 효과적인 정보추출을 위한 연구들이 진행되고 있다.
- Loss
- 모델에서 사용되는 목적함수는 negative log-likelihood 함수이다. 아래의 식에서 $p(x)$는 광고가 실제로 유저에게 전달되었을 때, 클릭될 확률을 말하며 $y$의 값은 0 또는 1로서 실제 정답을 의미한다. 데이터의 수는 전체 $N$개 이다. \[\tag{2} \mathcal{L} = -\frac{1}{N} \sum_{(\mathcal{x}, y) \in \mathcal{S}} (y \log p(\mathcal{x}) + (1-y)\log (1 - p(\mathcal{x}))\]
3.3 The structure of Deep Interest Network
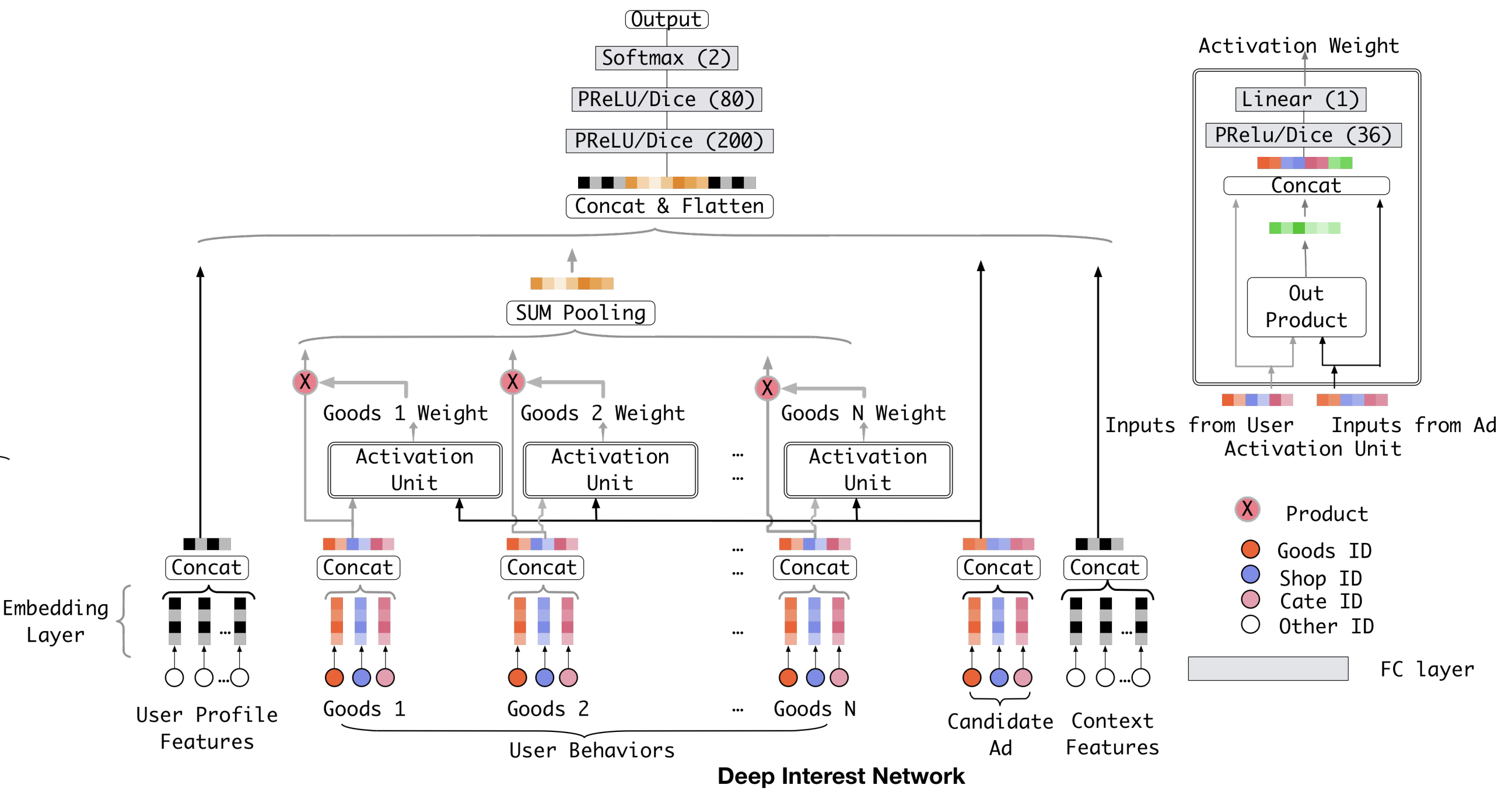
Embedding & MLP의 패러다임에서 벗어나, 고정길이 벡터의 representation을 개선시키는 방법을 모색하려고 DIN팀은 연구하였고, 그 결과로 local activation unit 을 발표하였다. 단순히 모든 임베딩 벡터들을 concatenation 시키기 보다는 후보 광고와 유저의 행동사이의 관련도를 구하고, 그 값을 가중합을 통해 하나로 합쳐준다.
\[\tag{3} \mathbf{v}_U(A) = f(\mathbf{v}_A, \mathbf{e}_1, \mathbf{e}_2, \dots, \mathbf{e}_H) = \sum_{j=1}^H a(\mathbf{e}_j, \mathbf{v}_A) \mathbf{e}_j = \sum_{j=1}^H \mathbf{w}_j \mathbf{e}_j\]- ${\mathbf{e}_1, \mathbf{e}_2, \dots, \mathbf{e}_H}$ : 유저 $U$의 길이 $H$인 행동 임베딩 벡터
- $\mathbf{v}_A$ : 광고 A에 대한 임베딩 벡터로서, $\mathbf{v}_U(A)$의 값이 서로 다른 광고에 대해 유동적임
- $a(\cdot)$ : feed forward network로서 activation weight를 출력으로 함
Local activation unit은 NMT 분야에서 발표된 attention 방법과 유사한 아이디어를 공유한다. 그러나 attention과의 차이점이 있다면, attention 가중치의 합이 1이 될 필요가 없다는 것이다. 이는 출력에 대해 softmax를 적용시킬 필요가 없음을 말한다. 대신 $\sum_i w_i$의 값이 유저가 특정 주제에 얼마나 큰 흥미가 있는지를 보여주는 지표로서 사용한다. softmax와 같은 normalization 과정이 존재하지 않기에 직접적인 관련도 값을 사용할 수 있게 된다.
4. Training Techniques
4.1 Mini-batch aware regularization
대용량 데이터셋 그리고 sparse한 데이터셋에서 학습할 때 과적합을 피하는 것도 매우 중요한 일 중 하나이다. sparse한 데이터 속에서 0이 아닌 값들에 대한 파라미터들이 업데이트 되어야하는데, 이는 regularization이 없는 SGD 최적화 방법에서 가능하다. 하지만 과적합을 피하기 위해 regularization을 넣게 되면 모든 파라미터에 대해 L2-norm을 계산해줘야하기 때문에 계산이 매우 어려워지게 된다.
논문에서는 L2-norm을 적용하더라도 sparse한 feature에 대해서만 값이 업데이트 되는 방법을 고안하였으며 임베딩 lookup table 파라미터 $\mathbf{W} \in \mathbb{R}^{D\times K}$의 loss는 아래와 같이 계산한다.
\[\tag{4} L_2(W) = \|W\|_2^2 = \sum_{j=1}^K \|w_j\|_2^2 = \sum_{(x, y) \in \mathcal{S}}\sum_{j=1}^K \frac{I(x_j \neq 0)}{n_j} \|w_j\|_2^2\]- $w_j \in \mathbb{R}^D$ : $j$ 번째 임베딩 벡터 (weekday의 임베딩 벡터)
- $I(x_j \neq 0)$ : $x$가 feature id j를 포함하는지 확인 (어떤 요일을 포함하는지 확인)
- $n_j$ : 모든 데이터에 대해 feature id j가 등장하는 횟수 (금요일 한번만 등장했다면 1)

만약 mini-batch를 사용한다면 아래와 같이 변형된다.
\[\tag{5} L_2(\mathbf{W}) = \sum_{j=1}^{K} \sum_{m=1}^B \sum_{(x, y) \in \mathcal{B}_m} \frac{I(x_j \neq 0)}{n_j} \|w_j \|_2^2\]- $B$ : 미니배치의 수
- $\mathcal{B}_m$ : $m$ 번째 미니 배치
좀 더 나아가, $a_{mj} = \max_{(x, y) \in \mathcal{B}_m} I(x_j \neq 0) $ 가 미니배치 속에서 적어도 하나 이상의 feature id j를 갖는지 확인하는 것으로 나타낸다면, 위의 수식 (5)를 근사시킬 수 있다.
\[\tag{6} L_2(\mathbf{W}) \approx \sum_{j=1}^K \sum_{m=1}^B \frac{\alpha_{mj}}{n_j} \| \mathbf{w}_j \|_2^2\]이제 위의 근사시킨 수식 (6)을 사용하여 임베딩 행렬의 가중치 $\mathbf{w}_j$ 를 아래의 수식처럼 경사하강법으로 업데이트하게 된다. 이렇게 함으로서 모든 파라미터에 대한 업데이트를 하지 않고, 입력 feature의 값이 1인 것에 대해서만 업데이트가 진행되는 결과를 얻을 수 있다. 추가로 해당 feature의 값이 몇 번 등장했는지를 나타내는 $n_j$로 나누어주어 결과에 미치는 영향을 균등하게 나누는 것도 인상깊었다.
\[\tag{7} \mathbf{w}_j \leftarrow \mathbf{w}_j - \eta \left[ \frac{1}{\vert \mathcal{B}_m \vert} \sum_{(\mathbf{x}, y) \in \mathcal{B}_m} \frac{\partial L(p(\mathbf{x}), y)}{\partial \mathbf{w}_j} + \lambda \frac{\alpha_{mj}}{n_j} \mathbf{w}_j \right]\]- $\mathcal{B}_m$ : $m$ 번째 미니배치
4.2 Data adaptive activation function
PReLU라는 활성함수는 ReLU의 변형 함수로서, 0이하의 값을 모두 0으로 내보내는 ReLU와는 달리 0이하의 값은 입력값에 $\alpha$를 곱하여 출력을 내보낸다. 여기서 사용되는 $\alpha$ 는 파라미터로 학습되며 PReLU의 모습은 아래와 같다.
- $p(x)$ : 제어 함수(control function)로, 0 또는 1의 값을 출력으로 갖는다.
PReLU에서 제어함수 $p(x)$는 0에서 나누어지는 계단함수로 표현되는데, 저자는 여기서 입력으로 들어가는 $x$의 분포가 일정하지 못하다면 이 제어함수가 적합하지 못하다는 것을 꼬집는다. 이에 새로운 제어함수인 $Dice$를 선보인다.
\[\tag{9} p(x) = \frac{1}{1 + e^{-\frac{x - \mathbb{E}[x]}{Var[x] + \epsilon}}}\]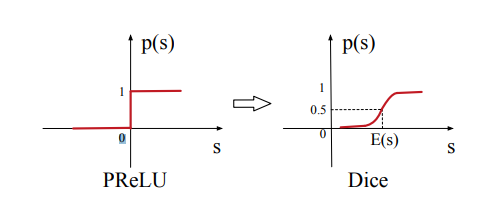
입력 값의 기댓값과 분산은 학습단계에서 미니-배치마다 계산되어지고 추론단계에서는 전체 데이터에 대해 이동평균을 구하며 계산된다. 정리하자면, 저자들이 말하는 “데이터에 적응하는 activation function”은 입력 데이터 분포를 고려하여 작용하는 활성함수를 말하는 것이다.
5. References
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep Interest Network for Click-Through Rate Prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ‘18). Association for Computing Machinery, New York, NY, USA, 1059–1068. https://doi.org/10.1145/3219819.3219823
PReLU (Parametric ReLU), 이든Eden, Eden 블로그 - Tisotry, 2020.04.11, https://i-am-eden.tistory.com/12