FastSpeech 2 - Fast and High-Quality End-to-End Text to Speech
FastSpeech 2: Fast and High-Quality End-to-End Text to Speech
- arXiv 2020
- Yi Ren, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, Tie-Yan Liu
Abstract
FastSpeech2 모델은 음성 합성 기술의 발전을 목표로, FastSpeech1의 한계를 극복하기 위해 설계되었습니다. FastSpeech1이 자동 회귀(auto-regressive) 형태의 선생(teacher) 모델에 의존하여 음소의 지속 시간(duration)을 예측하는 구조를 채택했다면, FastSpeech2는 이러한 방식에서 한 걸음 더 나아가 선생 모델의 예측에 의존하지 않고 직접 정답 데이터로부터 지속 시간을 비롯한 추가 정보를 계산하는 방법을 도입했습니다.
FastSpeech1에서 지적된 주요 문제 중 하나는 선생 모델의 예측이 항상 정확하다는 보장이 없다는 것이었습니다. 이러한 문제는 모델의 복잡성과 학습 시간의 증가로 이어졌고, 결과적으로 모델의 효율성과 성능에 영향을 미쳤습니다. FastSpeech2는 이러한 문제를 해결하기 위해 선생 모델의 예측을 사용하는 대신, 정답 값 자체를 데이터로부터 직접 계산하여 사용합니다. 이 접근 방식은 모델의 정확도를 높이고, 학습 과정의 효율성을 개선하는 데 중요한 역할을 합니다.
FastSpeech2는 음성 합성의 자연스러움을 크게 향상시키는 몇 가지 주요 특징을 가지고 있습니다. 이 중에서도 특히 주목할 만한 것은, 모델이 지속 시간(duration)뿐만 아니라 음성의 높이(pitch)와 에너지(energy) 정보도 포함한다는 점입니다. 이 추가 정보는 음성을 합성할 때 보다 자연스러운 결과를 얻기 위해 도입되었습니다. 학습 과정 동안에는 정답 멜 스펙트로그램(mel-spectrogram)에서 이러한 특성들을 추출해내어, 모델이 예측한 값과의 차이를 손실(loss)로 계산합니다. 이렇게 계산된 손실을 바탕으로 모델을 학습시킴으로써, 예측 과정에서 모델이 이러한 특성들을 보다 정확하게 예측할 수 있게 되고, 이는 더욱 자연스럽고 정확한 음성 합성 결과로 이어집니다.
1. Introduction
음성 합성 분야에서 맞닥뜨리는 가장 큰 도전 중 하나는 ‘one-to-many’ 문제입니다. 같은 텍스트라도 발화자의 의도나 감정에 따라 다양한 방식으로 발음될 수 있으며, 이는 음성 합성 시스템에게 여러 가능성 중 어느 것을 선택해야 할지 결정하기 어렵게 만듭니다. FastSpeech1 모델은 이 문제를 해결하기 위해 두 가지 주요 전략을 사용했습니다.
첫 번째 전략은 입력 데이터의 변이성(variance)을 줄이는 것입니다. ‘변이성이 높다’는 말은 입력 데이터가 다양한 특성을 가지고 있고, 결과적으로 모델이 예측해야 할 출력도 여러 가지일 수 있다는 의미입니다. 지식 증류(Knowledge distillation) 과정에서, 선생(teacher) 모델에 의해 예측된 소프트 라벨(soft label) 정보를 활용하게 되는데 이 정보를 사용하면 학생(student) 모델은 보다 일관된 예측을 수행할 수 있게 됩니다. 즉, 모델이 다양한 가능성을 가진 출력 중에서 일관된 패턴을 파악하고 학습하도록 돕는 전략입니다.
두 번째 전략은 선생 모델의 attention map 정보를 사용해 음소의 지속 시간을 예측하는 것입니다. attention map을 활용하면 음소별 길이와 멜 스펙트로그램의 길이를 정확히 맞출 수 있습니다. 이는 음성의 자연스러움을 유지하면서도 텍스트를 음성으로 변환하는 과정에서 필요한 부가 정보를 제공합니다.
그럼에도 불구하고, FastSpeech 모델은 몇 가지 단점을 가지고 있었습니다. 가장 두드러진 단점은 지식 증류(knowledge distillation) 기법을 사용함으로써 모델의 복잡성이 증가한다는 점입니다. 또한, 선생 모델이 항상 정확한 예측을 하는 것은 아니기 때문에 정보 손실을 초래할 수 있으며, 이는 결국 학생 모델이 잘못된 정보를 학습하게 만들어 음성의 품질 저하를 일으킬 수 있습니다.
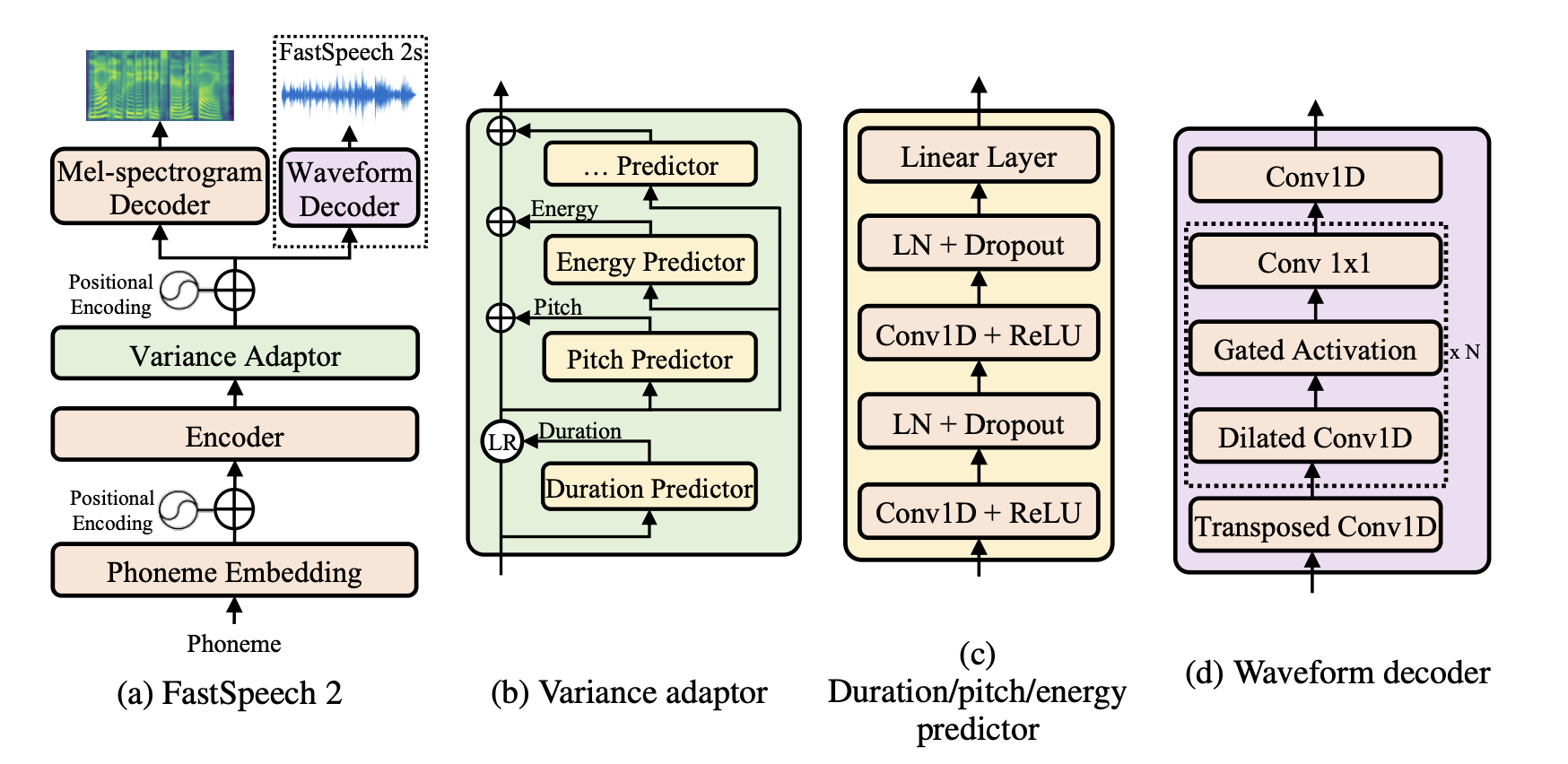
이러한 문제를 해결하기 위해 FastSpeech2는 knowledge distillation을 버리고 실제 정답 데이터를 직접 사용하기로 결정했습니다. 이는 모델이 더 정확하고 신뢰할 수 있는 정보를 기반으로 학습할 수 있게 만들기 위함입니다. 또한, 텍스트만으로는 음성을 합성하는 데 필요한 정보가 충분하지 않다고 판단하여, 지속 시간(duration) 정보뿐만 아니라 에너지(energy)와 음높이(pitch) 정보까지 활용함으로써 모델이 보다 풍부한 정보를 바탕으로 음성을 합성할 수 있도록 했습니다. 이러한 접근 방식은 FastSpeech2를 더욱 강력하고 정확한 음성 합성 도구로 만들어주었습니다.
2. FastSpeech2
2.1. Motivation
- One-to-many 문제를 해결하기 위해 지식증류를 사용한 모델 구조자체가 복잡하다!
- 부모 모델을 사용함에 있어서 발생할 수 있는 정답 멜 스펙트로그램의 정보 손실!
- 예측한 멜 스펙트로그램이 그다지 정확하지 않다!
2.2. Model Overview

이제부터는 논문에서 설명하는 내용과는 조금 다른 방식으로, 실제 모델의 학습 과정을 따라가 보려고 합니다. 우리가 먼저 할 일은 텍스트를 입력 받아 그로부터 임베딩을 생성하는 것입니다. 이 과정을 거친 후, 모델은 순서대로 인코더, 변이량 조정기(variance adaptor), 그리고 디코더를 통과하게 됩니다. 아키텍처를 전체적으로 캡처한 이미지는 글자가 선명하게 보이지 않을 수도 있지만, svg 파일로 업로드했으니 필요하다면 확대해 볼 수 있습니다.
Phoneme emebedding
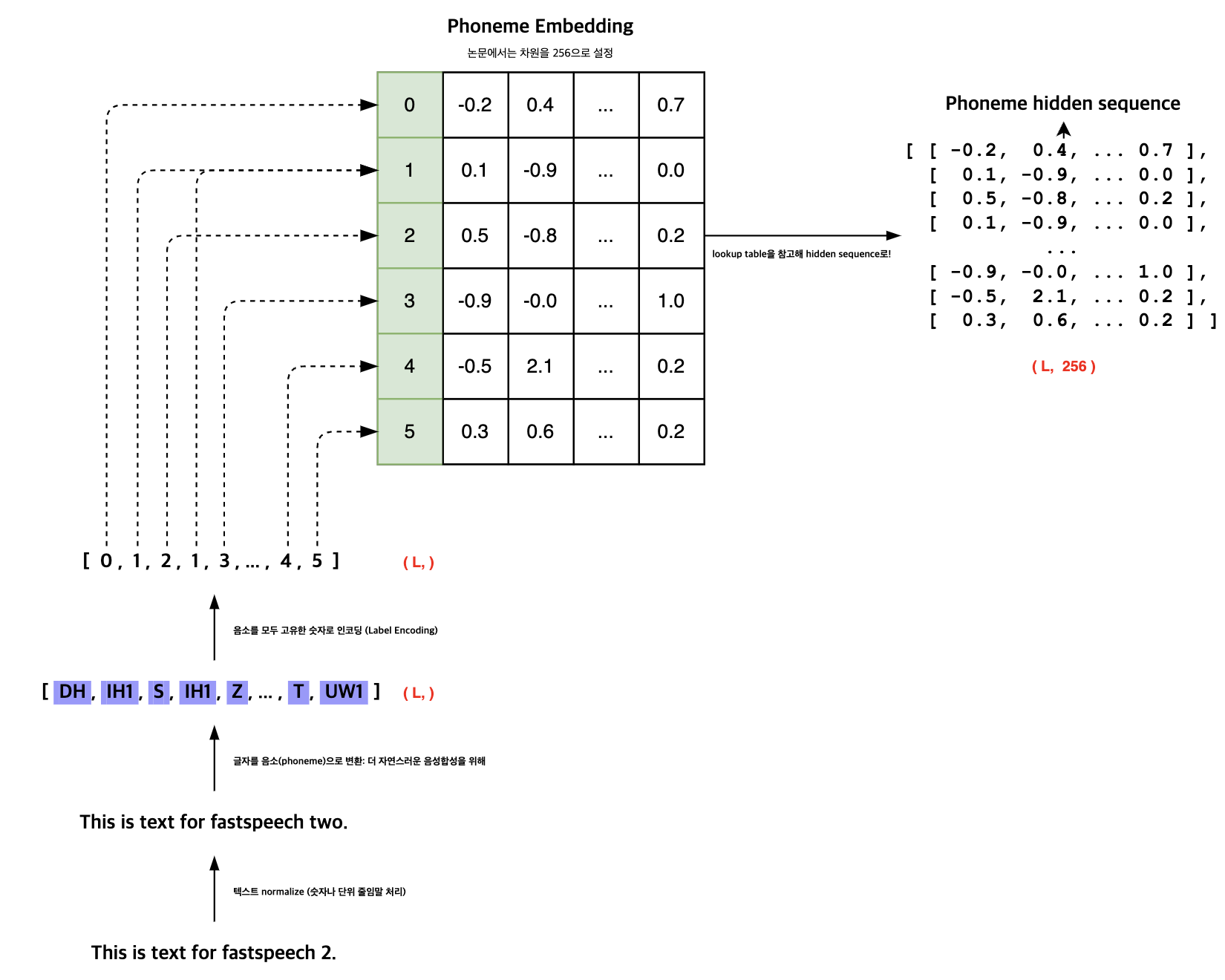
FastSpeech 2 모델에 ‘This is text for fastspeech 2.’라는 문장을 입력한다고 가정해 보겠습니다. 이 과정의 첫 단계는 텍스트 전처리입니다. 이 단계에서는 통화 단위, 특수 문자, 숫자 등을 알파벳으로 변환하는 작업을 주로 수행합니다. 예를 들어, ‘e.g.’와 같은 표현은 ‘for example’로 바뀌게 됩니다. 이어서 더욱 자연스러운 음성 합성을 위해서는 대부분의 모델이 텍스트를 음소로 변환합니다. 음소란 소리 나는 대로 작성된 문자로, 발음 기호와 유사하다고 볼 수 있습니다. 예를 들어, ‘This’는 ‘DH’, ‘IH1’, ‘S’와 같이 변환됩니다.
음소로 변환된 이후, 모델 입력으로 사용될 수 있도록 각 음소를 고유한 숫자로 매핑합니다. 이 과정을 라벨 인코딩이라고 하며, 이후 모델이 더 풍부한 표현을 포착할 수 있도록 고차원 공간으로 매핑합니다. 이때 사용되는 것이 음소 임베딩으로, 논문에 따르면 256차원으로 설정됩니다. 각 인덱스에 해당하는 임베딩을 참조하여 음소는 256차원의 벡터로 변환되며, 이 벡터들이 모여서 결국 길이가 L이고 256차원을 가지는 행렬이 만들어지게 됩니다. 이 행렬은 모델의 다음 단계로 전달되어 음성 합성 과정을 계속 진행하게 됩니다.
2.2.1. Positional Encoding
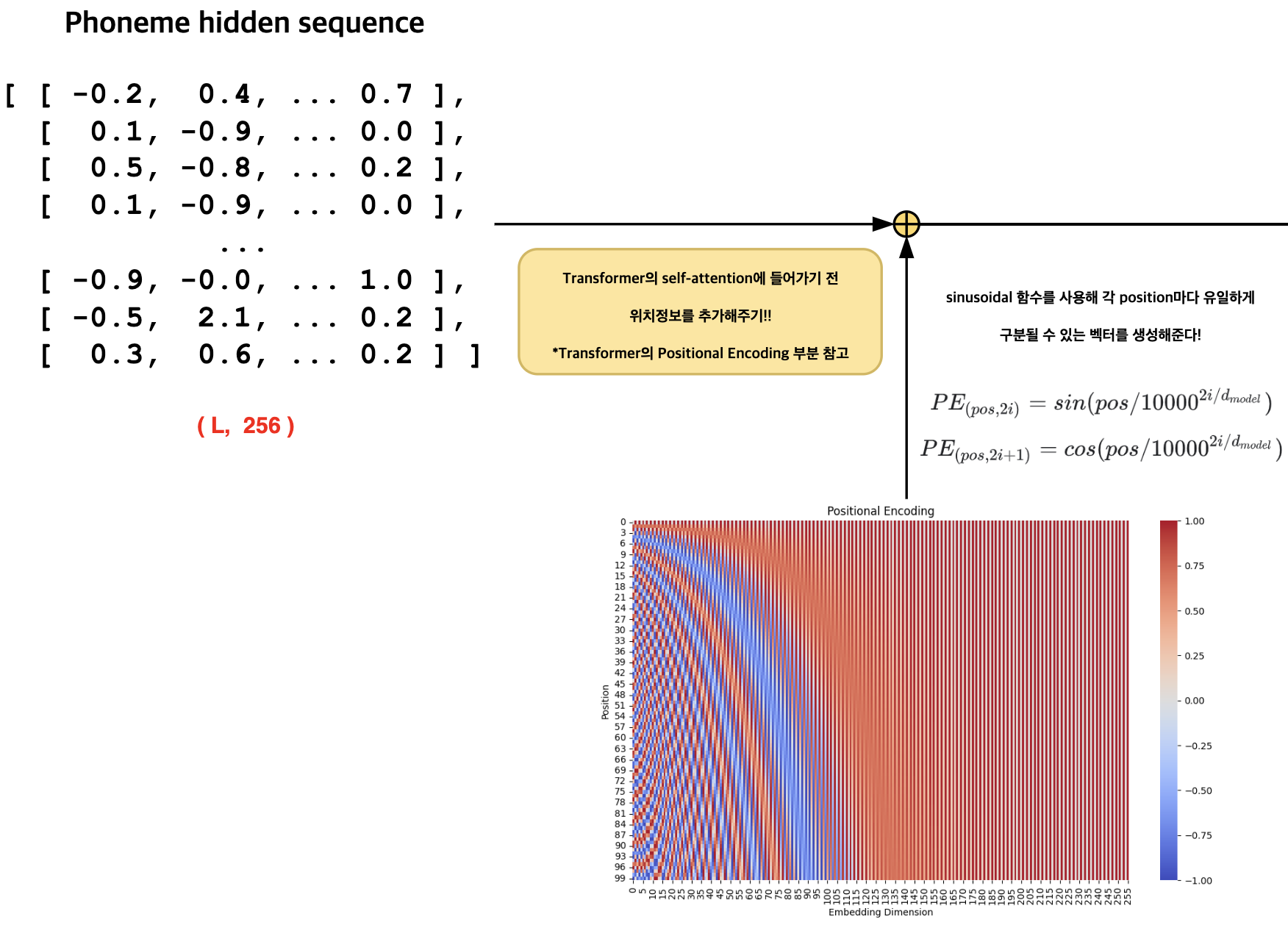
음소 임베딩 행렬이 준비되면, 모델은 입력 데이터를 처리할 준비가 완료됩니다. 그러나 트랜스포머(Transformer) 모델의 멀티 헤드 어텐션(Multi-Head Attention) 구조를 사용할 때는, 음소 시퀀스 간의 순서 정보를 직접적으로 고려할 수 없습니다. 이를 보완하기 위해, 시퀀스의 각 요소에 고유한 순서 정보를 추가하는 과정이 필요합니다. 이는 “Transformer: Attention is All You Need” 논문에서 소개된 바로, 2가지 삼각함수를 사용해 고유한 위치 정보를 시퀀스에 할당하는 기법입니다. 이 방법에서는 특히 사인(Sinusoidal) 함수를 사용하는데, 이는 위치 정보를 담은 값들이 -1과 1 사이의 값을 가진다는 중요한 특성 때문입니다. 이런 방식으로 위치 정보를 부여함으로써, 모델은 시퀀스의 순서를 고려하여 보다 효과적으로 학습하고, 결과적으로 자연스러운 음성 합성을 달성할 수 있게 됩니다.
2.2.2. Encoder & Decoder
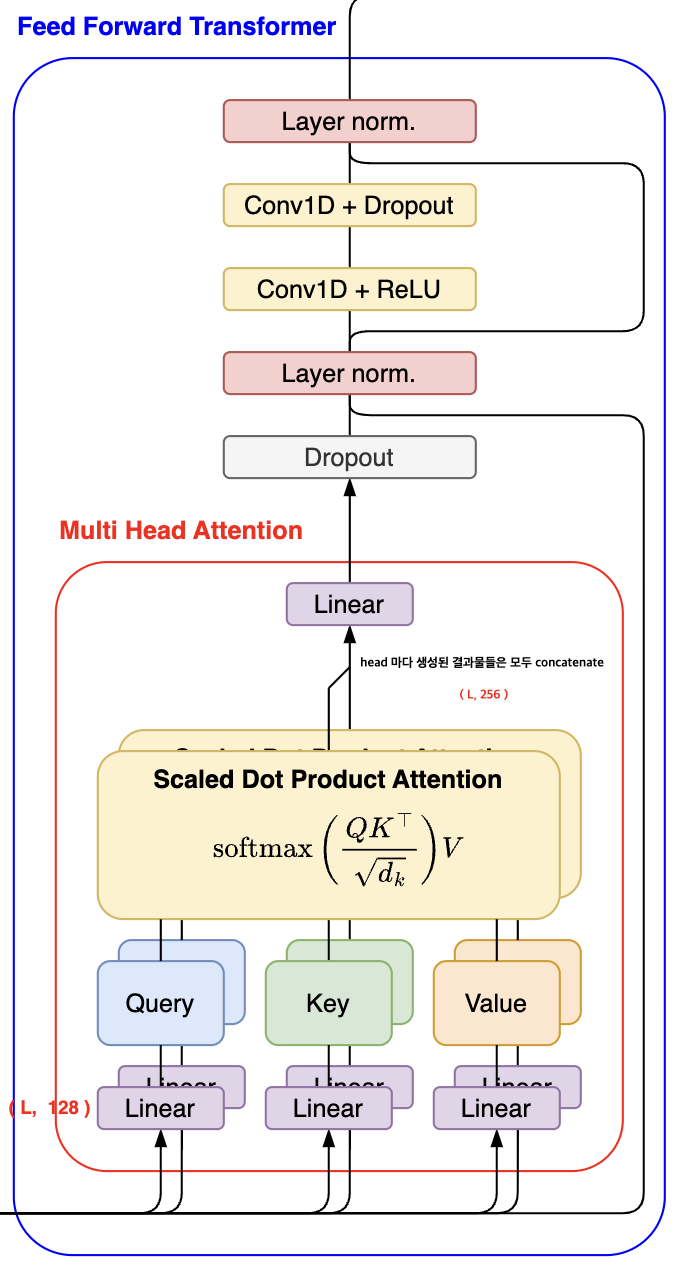
FastSpeech2 모델의 핵심 구성 요소 중 하나는 인코더와 디코더로, 둘 다 4개의 Feed Forward Transformer(FFT) 블록으로 구성되어 있습니다. 이 구조는 FastSpeech 모델에서 처음 도입되었으며, 각 FFT 블록 내에는 멀티 헤드 어텐션(Multi-Head Attention, MHA) 모듈과 두 개의 1D 컨볼루션(1D Convolution) 레이어가 포함되어 있습니다.
멀티 헤드 어텐션(MHA)
멀티 헤드 어텐션은 입력된 음소 시퀀스의 차원을 여러 ‘헤드(head)’로 나누어 처리하는 과정에서 시작합니다. 각 헤드는 입력 차원을 헤드의 개수로 나눈 만큼의 차원을 갖는 선형 레이어를 거쳐 차원이 축소됩니다. 이후, 각 헤드에서는 쿼리(query), 키(key), 값(value) 벡터를 생성하고, 이를 사용해 자기 자신에 대한 어텐션(self-attention) 연산을 수행합니다. 이 과정을 통해, 모델은 현재 음소와 가장 관련이 높은 다른 음소들을 찾아내게 됩니다. 멀티 헤드 어텐션을 사용함으로써, 모델은 다양한 관점에서 음소 간의 관계를 포착할 수 있게 됩니다.
1D 컨볼루션 레이어
각 헤드에서 생성된 벡터들은 이후 모두 연결(concatenated)되고, 최종적으로 하나의 선형 레이어를 통과합니다. 이 과정은 MHA 모듈의 결과를 다시 한번 집약하여 더 다양한 패턴을 포착하기 위함입니다. 결과적으로 얻어진 벡터는 드롭아웃(dropout) 처리를 거친 후, 두 개의 1D 컨볼루션 연산을 진행합니다. 음성 합성에서는 음소가 주변 음소의 영향을 크게 받기 때문에, 이러한 1D 컨볼루션 레이어의 역할은 매우 중요합니다. 이는 트랜스포머 모델의 Feed Forward Network (FFN)를 대체하는 것으로, 주변 음소의 영향을 효과적으로 포착하기 위해 도입되었습니다.
이렇게 FFT 블록은 FastSpeech2 모델이 입력된 텍스트를 자연스러운 음성으로 변환하는 과정에서 중요한 역할을 합니다. 각 단계는 음성의 자연스러움과 정확성을 향상시키기 위해 세심하게 설계되었습니다.
2.3. Variance Adaptor
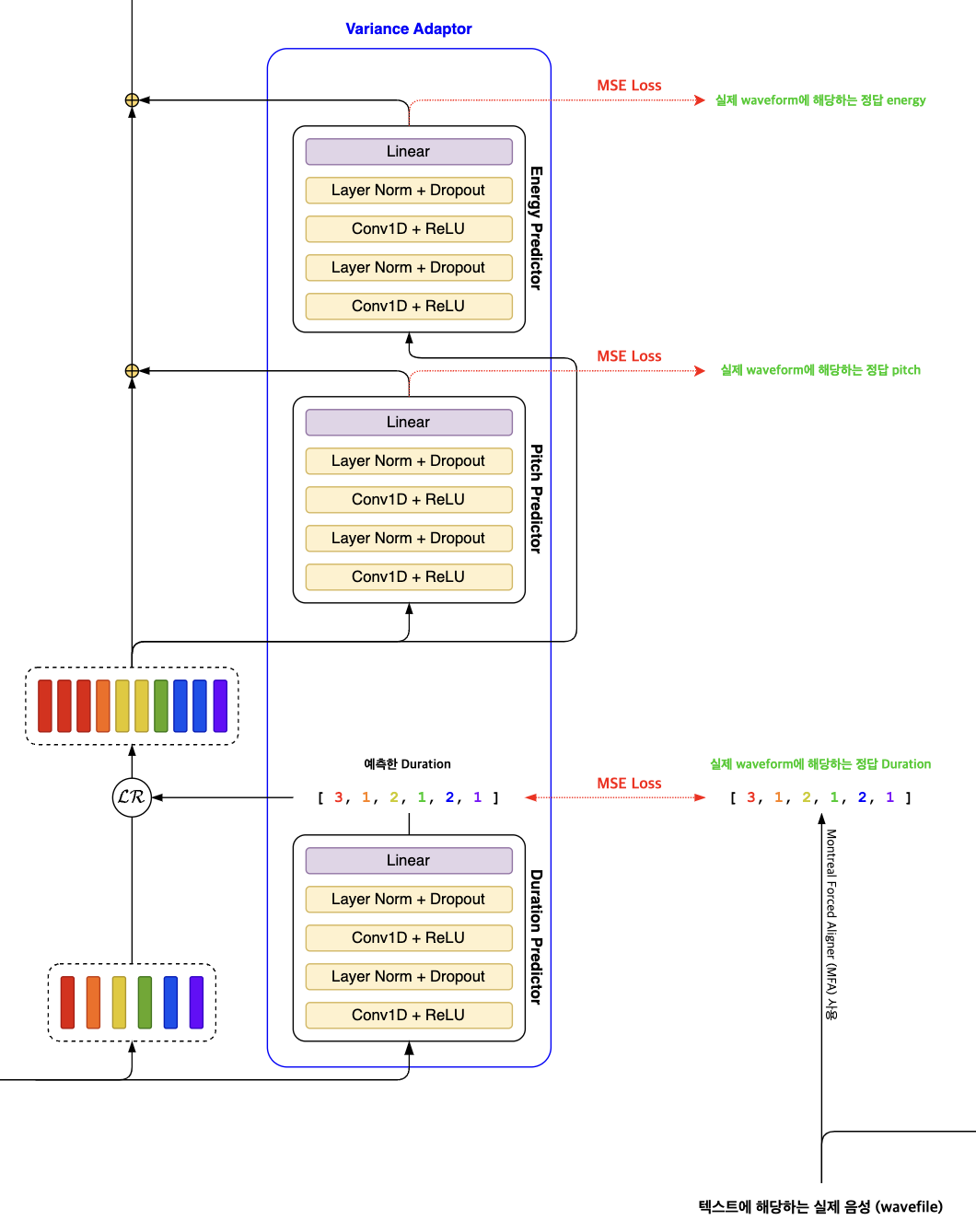
FastSpeech2 모델에서의 Variance Adaptor는 텍스트 정보를 넘어서, 음성 합성을 더욱 자연스럽고 풍부하게 만들어주는 부가 정보들을 모델에 통합할 수 있도록 설계되었습니다. 이러한 부가 정보에는 음소의 길이(duration), 음의 높이(pitch), 그리고 음의 세기(energy)가 포함됩니다. 이 세 가지 주요 정보를 예측하기 위한 각 predictor는 구조적으로 유사하게 설계되었습니다.
2.3.1. Duration predictor
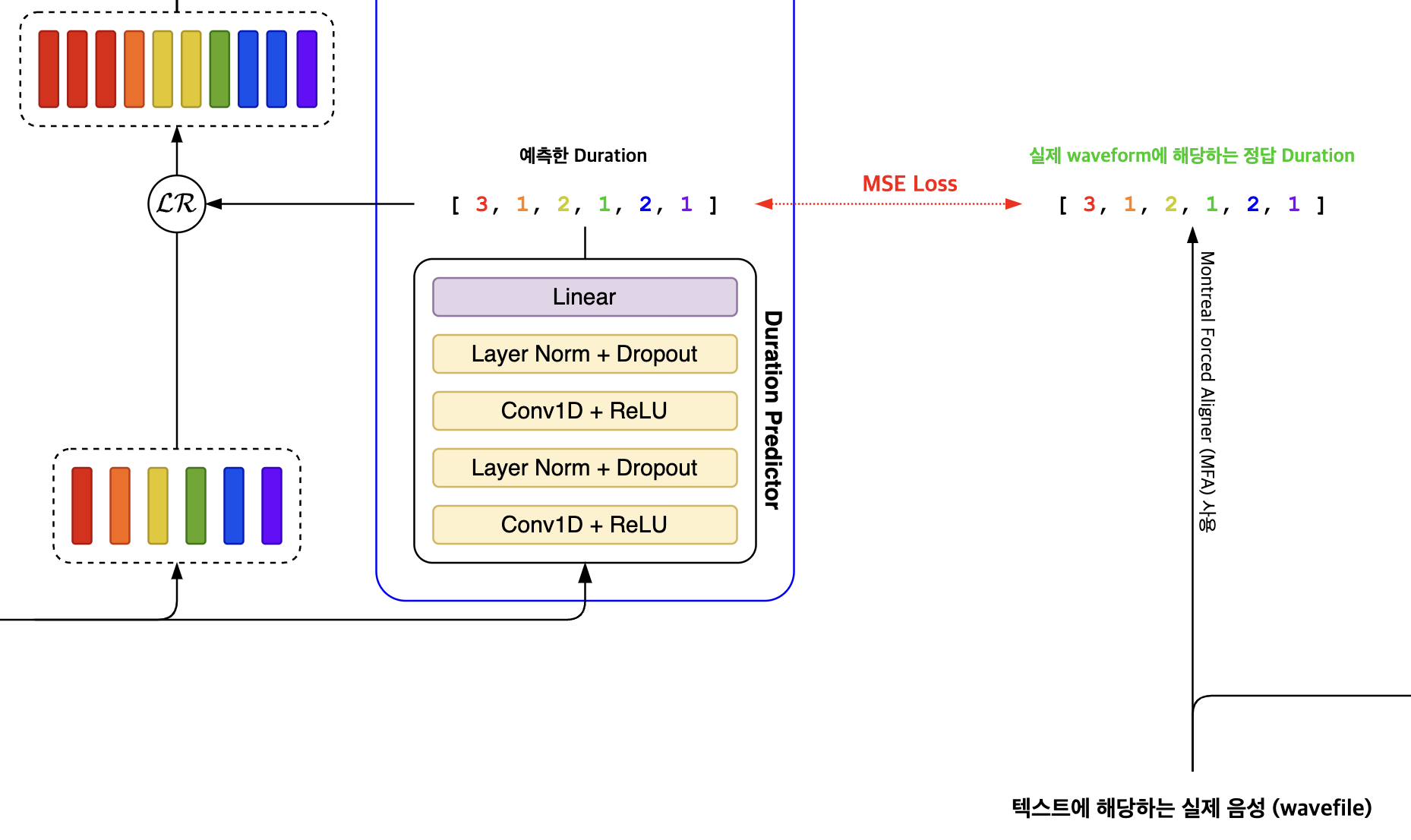
Duration Predictor는 FastSpeech2 모델에서 음성 합성의 자연스러움을 높이는 중요한 역할을 합니다. 이 모듈은 각 음소가 실제로 몇 개의 멜 프레임(mel frame)에 해당하는지를 예측하며, 우리가 실제로 문장을 발음할 때 특정 부분을 늘려 말하거나, 일부를 전혀 발음하지 않는 것처럼 묵음 처리하는 등의 다양한 발음 패턴을 반영합니다. 이러한 발음의 다양성을 모델링하기 위해 음소의 길이 예측이 포함되었고, 음성 합성에서 매우 중요한 요소로 고려됩니다.
Phoneme hidden sequence, 즉 음소의 숨겨진 시퀀스를 기반으로 각 음소의 길이를 예측합니다. 이 과정에서 로그 변환(logarithm)을 활용해 예측을 용이하게 만들었다고 합니다. 하지만 실제 PyTorch 구현에서는 torch.exp 함수를 적용하여 결과값을 크게 만들고, 이를 반올림하여 duration이 실제 발음 시간을 정확히 반영할 수 있도록 정수 형태로 예측합니다. 이는 각 음소가 발음되는 실제 시간이 1초 미만의 매우 짧은 시간을 나타내기 때문입니다. 손실(loss)을 계산할 때는 torch.log가 적용됩니다, 이는 로그 스케일로 되돌리는 과정을 의미합니다.
학습 과정에서는 정답 duration 데이터를 얻기 위해 Montreal Forced Aligner(MFA)를 사용합니다. MFA는 음성과 음소 사이, 또는 입력된 문장 사이의 정렬을 통해 정확한 attention map을 생성할 수 있으며, 이를 통해 계산된 duration은 모델이 예측한 값에 비해 훨씬 정확하므로, 정보 손실을 최소화할 수 있습니다. 이러한 접근 방식으로 인해, 모델은 정보 격차를 줄이고, MSE Loss를 사용하여 더 정확한 duration 예측값을 학습할 수 있게 됩니다.
2.3.2. Pitch predictor
Pitch Predictor는 FastSpeech2 모델에서 음의 높낮이 정보를 처리하는 중요한 부분입니다. 이전 연구들에서는 pitch 정보를 직접적으로 사용했으나, 이 방식은 pitch의 변동성이 크게 나타나는 경우, 실제 음성과 예측된 음성 사이에 상당한 차이를 초래할 수 있습니다. 이러한 변동성은 음성의 자연스러움을 해치며, 모델의 예측 성능에도 부정적인 영향을 미칩니다.
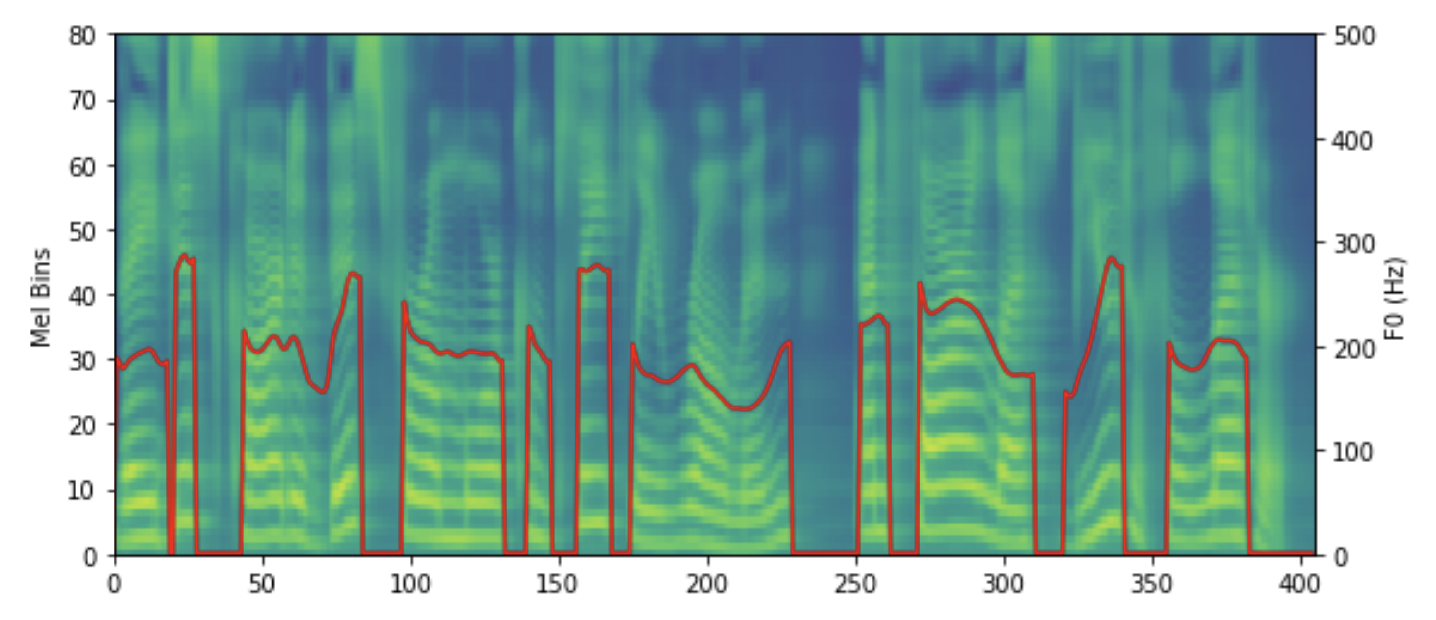
이 문제를 해결하기 위해, FastSpeech2에서는 Continuous Wavelet Transform (CWT)을 도입하여 pitch 정보의 변동성을 완화시키는 새로운 접근 방식을 채택했습니다. CWT를 적용함으로써, 원래의 pitch contour 대신에 pitch spectrogram을 생성합니다. 이 pitch spectrogram은 pitch 정보의 변동성을 보다 부드럽게 만들어 줌으로써, 모델이 예측하기에 더 용이한 형태로 변환됩니다.
모델은 이 pitch spectrogram을 예측하게 되며, 예측된 값은 다시 역-CWT(Invert-CWT)연산을 통해 원래의 pitch contour로 변환됩니다. 이 과정을 통해, FastSpeech2는 높낮이 정보의 변동성을 효과적으로 관리하며, 최종적으로 더 자연스러운 음성을 합성할 수 있게 됩니다. 이러한 방법은 pitch 정보를 활용함에 있어서 새로운 가능성을 제시하며, 음성 합성 분야에서의 발전을 촉진시키는 중요한 기여로 평가받고 있습니다.
2.3.3. Energy predictor
Energy Predictor는 FastSpeech2 모델 내에서 음성의 세기, 즉 energy를 처리하는 또 다른 중요한 모듈입니다. 여기서 energy는 멜 스펙트로그램의 각 프레임에 대한 $L_2$ 노름을 취한 값으로 정의됩니다. 이러한 정의는 음성의 세기를 보다 정량적으로 측정하고, 이를 모델이 학습할 수 있는 형태로 변환하는 데 도움을 줍니다.
이후, 계산된 energy 값들은 256개의 값으로 양자화되어, 모델이 이를 더 효과적으로 처리할 수 있도록 합니다. 이 양자화된 값을 “energy embedding”이라고 부릅니다. 하지만, 모델 학습 과정에서는 이 양자화된 값이 아니라 원래의 energy 값을 직접 예측하도록 설계되었습니다. 이 접근 방식은 모델이 실제 energy 분포를 더 잘 이해하고, 예측 성능을 향상시키는 데 기여합니다.
음성 합성 과정에서는 양자화된 energy 값이 사용됩니다. 이는 합성된 음성이 실제와 같은 세기를 갖도록 하여, 결과물의 자연스러움을 높이는 데 중요한 역할을 합니다. 실제 energy 값과 모델이 예측한 값 사이의 차이를 측정하기 위해서는, 다른 variance adaptor 모듈과 마찬가지로 MSE(Mean Squared Error) Loss가 사용됩니다. 이는 모델이 실제 음성의 세기를 가능한 한 정확하게 예측하도록 유도하며, 전반적인 음성 합성 품질의 개선에 기여합니다.
3. Experiments and Results
3.1. Experimental setup
- 사용 데이터셋: LJSpeech
- Train: Valid, Test 데이터셋을 제외한 나머지
- Valid: LJ001, LJ002로 시작하는 음원파일들
- Test : LJ003 으로 시작하는 음원파일들
- 문장을 음소로 변활할 때, 생성된 음소의 개수: 76
- Waveform에서 멜스펙트로그램 변환 (파라미터 값)
- frame size: 1024
- hop size: 256
- sampling rate: 22050
- CPU: 36 Intel Xeon
- RAM: 256GB
- GPU: NVIDIA V100
- 학습 batch: 48, 추론 batch: 1
3.2. Results
FastSpeech2 모델의 성능을 평가하기 위해, Tacotron2, Transformer TTS, 그리고 FastSpeech와 같은 다른 음성 합성 모델들과 비교되었습니다. 이 모델들은 모두 텍스트에서 멜 스펙트로그램을 생성하는 어쿠스틱 모델이며, 이후 생성된 멜 스펙트로그램을 파형(waveform)으로 변환하는 데 보코더 모델이 필요합니다. 실험에서는 어쿠스틱 모델의 성능만을 집중적으로 비교하고자 하였기 때문에, 모든 모델에 대해 보코더로는 Parallel WaveNet GAN을 고정하여 사용하였습니다.
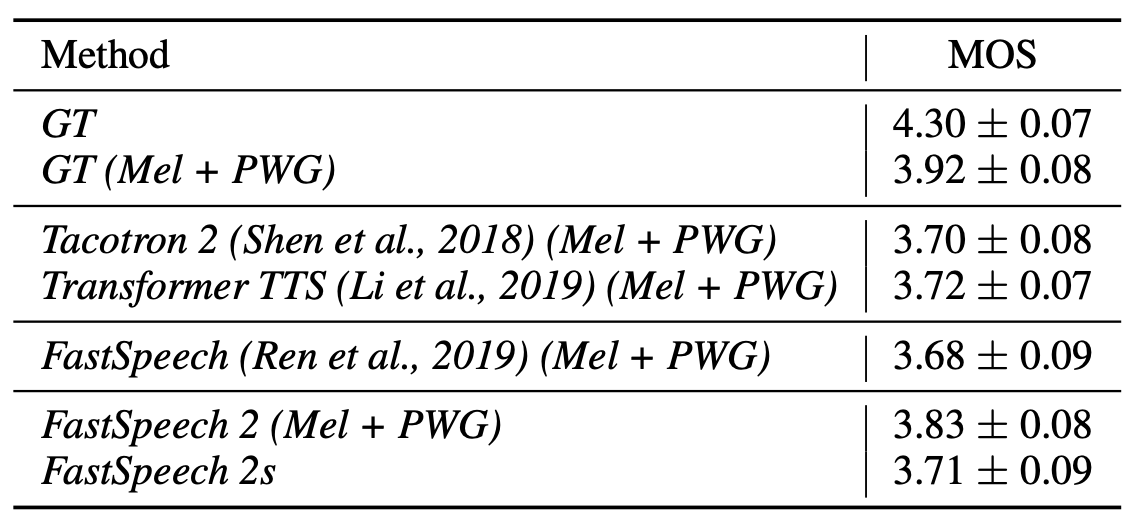
성능 평가 지표로는 MOS(Mean Opinion Score) 점수가 사용되었는데, FastSpeech2는 3.83점을 기록하며, 보코더를 적용한 실제 음성(Ground Truth)의 3.92점에 거의 근접한 결과를 보였습니다. 이는 FastSpeech2가 생성한 음성이 자연스러움 면에서 거의 실제 음성과 동등한 수준에 이르렀음을 의미합니다. 논문에서 특히 강조하고 싶은 점은 음성 합성 속도입니다. FastSpeech2는 이름에서도 알 수 있듯이, 음성 합성을 매우 빠르게 처리합니다.

RTF(Real-Time Factor)는 1초 분량의 waveform 생성에 소요된 시간을 나타내는 지표로, Transformer TTS는 auto-regressive한 특성 때문에 상대적으로 더 많은 시간을 필요로 했습니다. FastSpeech1은 지식 증류(Knowledge Distillation) 과정 때문에 학습 시간이 길었습니다. 그러나 FastSpeech2는 선생 모델(Teacher Model)을 별도로 학습할 필요가 없고, non-autoregressive 구조를 가지고 있어서 RTF 값이 낮으며, 음성 합성 속도가 매우 빠릅니다.

또한, 저자들은 Montreal Forced Aligner(MFA)를 사용해 얻은 결과와 선생 모델로 예측한 duration의 결과를 비교하여 제시했습니다. CMOS(Comparative Mean Opinion Score) 점수에서 MFA를 사용하여 합성한 음성이 0.195점 더 높게 기록되었으며, 이 평가는 약 50개의 음원 샘플을 사용하여 진행되었습니다. 이러한 결과는 FastSpeech2가 기존 모델들에 비해 우수한 성능을 제공하며, 특히 음성 합성 속도 면에서 혁신적인 개선을 이루었음을 보여줍니다.
4. Conclusion
정리하자면, FastSpeech2 모델은 이전의 FastSpeech 모델에서 발생했던 몇 가지 문제점들을 해결하기 위해 제안되었습니다. 특히, 이전 모델에서 사용되었던 지식 증류 기법의 복잡성과 선생(teacher) 모델의 정확도 문제를 지적하면서, FastSpeech2는 음성 합성의 품질을 향상시키기 위한 새로운 방향을 제시했습니다. 이를 위해, 모델은 단순히 음소의 지속시간(duration) 정보만을 제공하는 것이 아니라, 음성의 피치(pitch)와 에너지(energy) 정보를 추가적으로 고려함으로써 음성 합성의 자연스러움과 품질을 높였습니다.
FastSpeech2의 후속 연구들을 미리 공부해봤기에, 이 모델이 음성 합성 분야에 끼친 영향력을 살펴볼 수 있었습니다. 또한, 이 모델에서 요구되었던 외부 정렬자(external aligner)인 MFA는 이후 연구에서 제거되는 형태로 발전하며 성능 개선을 위한 노력은 이 분야의 연구 발전에 있어 흥미로운 전환점을 제공합니다.
한편으로는, 음성 합성 연구가 단순한 모델 구축을 넘어서 음성 도메인에 대한 깊은 이해와 다양한 지식을 필요로 한다는 것을 인식하게 되었습니다. 또한, 현재까지 모델링하지 못한 중요한 특성들이 있을 수 있으며, 이러한 부분들을 해결함으로써 성능을 개선할 수 있는 가능성이 있을 것 같다는 생각이 들기도 합니다.
5. References
[1] Ren, Yi, et al. “Fastspeech 2: Fast and high-quality end-to-end text to speech.” arXiv preprint arXiv:2006.04558 (2020).
[2] Ren, Yi, et al. “Fastspeech: Fast, robust and controllable text to speech.” Advances in neural information processing systems 32 (2019).
[3] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
[4] ming024, FastSpeech2, GitHub repository, https://github.com/ming024/FastSpeech2/tree/master?tab=readme-ov-file