Flowtron - an Autoregressive Flow-based Generative Network for Text-to-Speech Synthesis
Flowtron: an Autoregressive Flow-based Generative Network for Text-to-Speech Synthesis
- arXiv 2020
- Rafael Valle, Kevin Shih, Ryan Prenger, Bryan Catanzaro
Abstract
이 글에서는 텍스트-음성 변환을 위한 새로운 생성 네트워크인 Flowtron에 대해 다룹니다. 이 모델은 음성 변이와 스타일 전환을 제어할 수 있다는 것이 주요 특징입니다. FlowTron은 Tacotron을 기반으로 하여 높은 음성 품질을 제공하며, 훈련 과정이 간단하고 안정적입니다. 또한, 이 모델은 음성 합성의 다양한 요소를 조절할 수 있는 잠재 공간을 학습하며, 실험 결과 최신 TTS 모델들과 비교해도 뛰어난 성능을 보입니다. 스타일 전환과 샘플 간 보간 기능도 포함되어 있으며, 코드와 모델은 여기에서 확인할 수 있습니다.
1 Introduction
연구팀은 현재의 음성 합성 방법이 사용자에게 음성의 세부 조작 권한을 충분히 제공하지 못한다고 지적합니다. 기존의 텍스트-음성 변환 기술은 의미 전달과 인간의 표현력을 충분히 반영하지 못하고 있으며, 비텍스트 정보를 다루는 데 한계가 있습니다. 이러한 비텍스트 정보는 명확한 레이블이 없어 비지도 학습에 의존하게 되며, 사용자에게 이 정보를 제어할 능력을 제공하지 못합니다.
이를 해결하기 위해, 연구팀은 Flowtron이라는 새로운 생성 네트워크를 제안합니다. Flowtron은 멜-스펙트로그램 분포를 가우시안 잠재 공간으로 매핑하여 특정 음성 특성을 제어할 수 있게 합니다. 이 접근법은 음성 품질 저하 없이 다양한 변이와 제어를 가능하게 하며, 복잡한 추가 구조 없이도 선명한 멜-스펙트로그램을 생성할 수 있습니다.
실험 결과, Flowtron은 최신 모델들과 비교해 음성 품질이 우수하며, 다양한 음성 변이와 스타일 전환에도 효과적임을 보여줍니다. 연구팀은 이 기술이 텍스트-음성 변환 분야에서 중요한 발전을 이끌 것으로 기대하고 있습니다.
2 Related Work
// 과거 모델들의 주요 한계점들의 소개
초기 텍스트-음성 변환 접근법들은 비텍스트 정보를 블랙박스로 다루며, 텍스트에서 음향적 특징을 합성하는 데 중점을 두었습니다. 이러한 방법들은 수렴과 일반화를 개선하기 위해 Prenet 레이어를 추가하고, 합성 아티팩트를 줄이기 위해 Postnet 잔여 레이어와 수정된 손실 함수를 사용해야 했습니다.
비텍스트 정보에 대한 명확한 레이블이 없을 때, 수작업으로 오디오 통계를 추정하는 방법이 과거에 있긴 했습니다. 예를 들어, Nishimura et al. (2016) 및 Lee et al. (2019)의 모델들은 훈련 데이터에서 계산된 통계치에 기반해 발화를 조건화하지만, 이러한 접근은 목표 통계치를 사전에 설정해야 한다는 제약이 있습니다.
이 문제를 해결하기 위해, 운율이나 스타일에 대한 잠재 임베딩을 학습하는 방식이 또 한번 제안되었습니다. Skerry-Ryan et al. (2018) 및 Wang et al. (2018) 모델들은 레이블이 없는 데이터에서 임베딩을 학습하지만, 이 방법은 음성의 표현 특성을 세밀하게 제어하기에는 한계가 있습니다.
또한, 수작업으로 설계된 통계치와 비지도 학습된 잠재 임베딩을 결합하는 혼합 접근법도 있습니다. Mellotron(Valle et al., 2019b)은 오디오 통계치와 참조 음향 표현에서 도출된 잠재 임베딩을 결합해 발화를 생성하지만, 이 역시 합성 전에 통계치를 결정해야 하는 제약이 있습니다.
3 Flowtron
Flowtron은 이전 멜-스펙트로그램 프레임을 기반으로 멜-스펙트로그램 프레임 시퀀스를 생성하는 자가회귀 생성 모델입니다. 이 모델은 단순한 분포에서 샘플링하여 신경망을 생성 모델로 사용하며, 구체적으로는 평균이 0인 구면 가우시안 분포와 고정되거나 학습 가능한 매개변수를 가진 구면 가우시안 혼합 분포를 고려합니다.
Flowtron의 핵심은 샘플을 일련의 가역적이고 매개변수화된 아핀 변환을 통해 변환하는 것으로, 이를 통해 간단한 분포 $p(z)$를 멜-스펙트로그램 분포 $p(x)$로 변환합니다. 이때, 자가회귀 구조 덕분에 각 변환의 야코비안 행렬식이 하삼각 행렬이 되어 계산이 용이해집니다. 이를 통해 Flowtron은 변수 변환을 사용해 데이터의 로그 가능도를 최대화하며, 효과적으로 훈련될 수 있습니다.
\[\begin{aligned} \boldsymbol{x}=\boldsymbol{f}_{0}\circ\boldsymbol{f}_{1}\circ\ldots\boldsymbol{f}_{k}(\boldsymbol{z}) \\ \end{aligned}\] \[\begin{aligned} \log{p_{\theta}(\boldsymbol{x})}=\log{p_{\theta}(\boldsymbol{z})}+\sum_{i=1}^{k}\log|\det(\boldsymbol{J}(\boldsymbol{f}_{i}^{-1}(\boldsymbol{x})))|\\ \boldsymbol{z}=\boldsymbol{f}_{k}^{-1}\circ\boldsymbol{f}_{k-1}^{-1}\circ\ldots\boldsymbol{f}_{0}^{-1}(\boldsymbol{x}) \\ \end{aligned}\]하삼각 행렬덕분에 계산이 용이해진 이유
하삼각 행렬이 등장하는 이유와 계산이 편해지는 이유를 이해하려면, 우선 야코비안 행렬의 개념과 하삼각 행렬의 특성을 알아야 합니다.
(1) 야코비안 행렬과 하삼각 행렬
\[\boldsymbol{J}(\boldsymbol{f}) = \frac{\partial \boldsymbol{f}}{\partial \boldsymbol{z}} = \begin{pmatrix} \frac{\partial f_1}{\partial z_1} & \frac{\partial f_1}{\partial z_2} & \cdots & \frac{\partial f_1}{\partial z_n} \\ \frac{\partial f_2}{\partial z_1} & \frac{\partial f_2}{\partial z_2} & \cdots & \frac{\partial f_2}{\partial z_n} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial f_n}{\partial z_1} & \frac{\partial f_n}{\partial z_2} & \cdots & \frac{\partial f_n}{\partial z_n} \end{pmatrix}\]
변환 $f$는 벡터 변수를 다른 벡터 변수로 매핑하는 함수입니다. 이 함수 $f$의 야코비안 행렬 $\boldsymbol{J}(\boldsymbol{f})$는 입력 변수의 미세한 변화가 출력 변수에 어떻게 영향을 미치는지를 나타내는 행렬입니다. 구체적으로, 야코비안 행렬은 다음과 같이 구성됩니다:여기서 $f_i$는 함수 $f$의 $i$번째 출력 성분이고, $z_j$는 입력 성분입니다. 야코비안 행렬의 행렬식(det)은 변환 $f$가 공간을 얼마나 ‘확장’ 또는 ‘축소’시키는지를 나타냅니다.
(2) 하삼각 행렬의 특성
\[\begin{pmatrix} a_{11} & 0 & 0 \\ a_{21} & a_{22} & 0 \\ a_{31} & a_{32} & a_{33} \end{pmatrix}\]
하삼각 행렬이란 모든 비대각 성분이 행보다 열이 큰 경우에만 존재하는 행렬을 말합니다. 예를 들어, 다음과 같은 행렬이 하삼각 행렬입니다:하삼각 행렬의 중요한 특성 중 하나는 행렬식 계산이 매우 간단하다는 것입니다. 하삼각 행렬의 행렬식은 대각선 성분의 곱과 같습니다. 즉, 위의 예에서 행렬식은 $a_{11} \times a_{22} \times a_{33}$이 됩니다. 따라서, 이 특성 덕분에 야코비안 행렬이 하삼각 행렬인 경우, 행렬식을 계산하는 과정이 매우 단순해집니다.
(3) 야코비안 행렬이 하삼각 행렬이 되는 이유
주어진 상황에서, 함수 $f$는 자가회귀 구조(autoregressive structure)를 가지고 있습니다. 이는 $t$번째 변수 $\boldsymbol{z}_t$가 이전 변수 $\boldsymbol{z}_{1:t-1}$에만 의존하는 구조를 의미합니다. 따라서, $f$의 야코비안 행렬에서 $t$번째 출력 성분 $\boldsymbol{z}_t$는 그 자체와 이전 변수들에 대해서만 편미분을 가지며, 이후 변수들에 대해서는 편미분이 0이 됩니다. 이 구조로 인해 야코비안 행렬은 하삼각 행렬의 형태를 띠게 됩니다.(4) 하삼각 행렬 덕분에 계산이 편해지는 이유
앞서 설명한 바와 같이, 하삼각 행렬의 행렬식은 대각선 성분의 곱으로 간단히 계산됩니다. 따라서, 변환의 야코비안 행렬이 하삼각 행렬이 되면 각 변환에 대해 행렬식을 계산하는 데 많은 계산량이 필요하지 않게 됩니다. 이는 특히 데이터의 로그 가능도를 최대화하는 과정에서 매우 효율적입니다.결론적으로, 자가회귀 정규화 흐름에서 매개변수화된 아핀 변환을 사용하면 야코비안 행렬이 하삼각 행렬이 되고, 이로 인해 각 변환의 야코비안 행렬식을 쉽게 계산할 수 있습니다. 이러한 구조적 이점 덕분에 모델의 학습이 더 효율적으로 이루어질 수 있습니다.
네트워크의 순방향 패스에서는 멜-스펙트로그램을 벡터로 처리하고, 이를 텍스트와 화자 ID에 따라 조건화된 여러 “플로우의 단계”를 거칩니다. 이러한 플로우의 각 단계는 아핀 결합 층으로 구성됩니다.
3.1 Affine Coupling Layer
Flowtron의 가역 신경망은 일반적으로 결합 층을 사용하여 구성되며, 본 연구에서는 아핀 결합 층을 사용합니다. 이 층에서는 각 입력 $x_{t − 1}$이 스케일 $s$와 바이어스 $b$를 생성하여 다음 입력 $x_t$를 아핀 변환합니다. $NN()$은 자가회귀 인과 변환으로, 첫 번째 입력이 상수이기 때문에 전체 네트워크의 가역성을 유지할 수 있습니다.
네트워크를 역전시킬 때는 이전 입력 $x_{1 : t − 1}$으로부터 $s_t$와 $b_t$를 계산하고, $x_t^′$을 역전시켜 $x_t$를 복구합니다. 아핀 결합 층에서는 $s_t$ 항만이 매핑의 볼륨을 변경하며, 이는 손실 함수에 변수 변환 항을 추가하고, 가역적이지 않은 아핀 매핑에 대해 패널티를 부여하는 역할을 합니다.
\[\begin{aligned} (\log\boldsymbol{s}_{t},\boldsymbol{b}_{t})&=NN(\boldsymbol{x}_{1:t-1},\text{text},\text{speaker}) \\ \boldsymbol{x}^{\prime}_{t}&=\boldsymbol{s}_{t}\odot\boldsymbol{x}_{t}+\boldsymbol{b}_{t}\\ \end{aligned}\]또한, 모델은 짝수 단계에서는 입력 순서를 역전시키고 홀수 단계에서는 원래의 순서를 유지함으로써 시간적 종속성을 앞뒤로 모두 학습할 수 있습니다. 이는 모델이 인과적이고 가역적인 특성을 유지하면서도 더 풍부한 시간적 관계를 학습하도록 도와줍니다.
3.2 Model Architecture
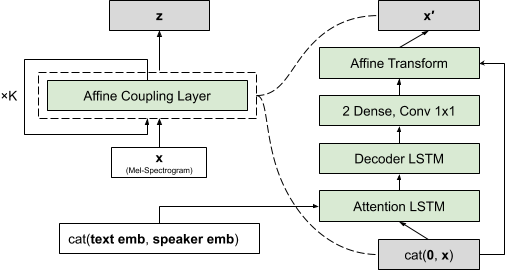
Flowtron의 텍스트 인코더는 Tacotron의 배치 정규화를 인스턴스 정규화로 대체하여 수정되었습니다. 디코더와 $NN$ 아키텍처에서는 Tacotron의 필수적인 Prenet과 Postnet 레이어를 제거하였으며, Vinyals et al. (2015)에서 설명된 tanh 어텐션을 사용합니다. 가우시안 혼합 매개변수를 예측하는 모델을 위해 Hsu et al. (2018)에서 설명된 Mel 인코더도 적용했습니다.
또한, Ping et al. (2017) 및 Gibiansky et al. (2017)에서 사용된 특정 사이트 화자 임베딩과 달리, 단일 화자 임베딩을 각 토큰의 인코더 출력과 채널 단위로 연결하는 방식을 채택했습니다. 화자 ID에 조건화되지 않은 모델에서는 고정된 더미 화자 임베딩을 사용하며, 추론 과정에서 추가적인 계산을 줄이기 위해 $z$에 가장 가까운 플로우 단계에서 시그모이드 출력을 가진 밀집 층을 추가하여 게이팅 메커니즘을 제공했습니다.
3.3 Inference
네트워크가 훈련된 후, 추론 과정은 구형 가우시안 또는 가우시안 혼합 분포에서 $z$ 값을 무작위로 샘플링하고, 필요시 입력의 순서를 역전시키며 네트워크를 통과시키는 간단한 절차로 이루어집니다. 훈련 중에는 $σ^2 = 1$을 사용했으며, 가우시안 혼합의 매개변수는 고정되거나 Flowtron에 의해 예측됩니다.
4.3절에서는 $σ^2$의 다양한 값이 미치는 영향을 탐구한 결과, 훈련 중 사용된 표준 편차보다 낮은 값에서 샘플링한 $z$ 값이 더 나은 소리의 멜-스펙트로그램을 생성한다는 것을 발견했습니다. 이는 이전 연구에서도 확인된 바 있습니다. 추론 과정에서는 별도의 언급이 없는 한 $σ^2 = 0.5$인 가우시안에서 $z$ 값을 샘플링했습니다. 또한, 텍스트와 화자 임베딩은 각 결합 층에 포함되며, 아핀 변환이 시간적으로 번갈아가며 적용됩니다.
4 Experiments
이 섹션에서는 Flowtron의 훈련 설정을 설명하고, 정량적 및 정성적 결과를 제시합니다. 정량적 결과에 따르면, Flowtron은 Tacotron 2와 같은 최첨단 텍스트-멜-스펙트로그램 합성 모델과 비교할 만한 평균 의견 점수(MOS)를 기록했습니다. 정성적 결과에서는 Tacotron 및 Tacotron 2 GST로는 불가능하거나 비효율적인 기능들을 보여주며, 이에는 음성 변동의 양 제어, 샘플 간 보간, 훈련 중 보거나 보지 않은 화자 간의 스타일 전환이 포함됩니다.
모든 멜-스펙트로그램은 GitHub에서 제공되는 사전 학습된 WaveGlow 모델을 사용하여 웨이브폼으로 디코딩되었으며, 추론 중에는 $σ^2 = 0.7$을 사용했습니다. 결과적으로 WaveGlow가 범용 디코더로 사용될 수 있음을 시사합니다.
4.1 Training Setup
이번에는 Flowtron, Tacotron 2, 및 Tacotron 2 GST 모델을 훈련하기 위해 사용한 데이터셋과 훈련 설정을 설명합니다. 연구팀은 LJSpeech(LJS) 데이터셋과 두 개의 독점 단일 화자 데이터셋(Sally와 Helen)을 결합한 LSH 데이터셋을 사용하였으며, 또한 123명의 화자와 화자당 평균 25분의 데이터를 가진 LibriTTS의 train-clean-100 하위집합을 사용하여 Flowtron 모델을 훈련했습니다. 각 데이터셋에서 최소 180개의 샘플을 검증 세트로 사용하고 나머지는 훈련 세트로 사용했습니다.
모델들은 CMU 발음 사전에서 얻은 ARPAbet 인코딩과 정규화된 텍스트를 기반으로 훈련되었으며, 데이터 증강은 수행하지 않았습니다. 또한, 화자 임베딩을 포함하기 위해 공개된 Tacotron 2와 Tacotron 2 GST repository를 수정했습니다.
연구팀은 22050 Hz의 샘플링 속도와 librosa의 기본 멜 필터 설정을 사용하여 80개의 빈을 가진 멜-스펙트로그램을 생성하고, FFT 크기 1024, 윈도우 크기 1024 샘플, 홉 크기 256 샘플(~12ms)로 STFT를 적용했습니다.
Flowtron과 다른 모델들에 대해서는 ADAM 옵티마이저를 사용하였고, Flowtron에는 1e-4 학습률과 1e-6 가중치 감소를, 다른 모델들에는 1e-3 학습률과 1e-5 가중치 감소를 적용했습니다. 일반화 오류가 평탄해지면 학습률을 감소시키고, 더 이상 개선되지 않을 때 훈련을 중지했습니다.
Flowtron 모델은 LSH 데이터셋에서 약 1000 에포크 동안 훈련된 후 LibriTTS에서 500 에포크 동안 미세 조정되었으며, Tacotron 2와 Tacotron 2 GST는 각각 500 에포크 동안 훈련되었습니다. 모든 모델은 NVIDIA DGX-1에서 훈련되었습니다.
연구팀은 단일 플로우 단계와 많은 데이터를 사용하여 먼저 어텐션을 학습한 후, 이 파라미터를 더 많은 플로우 단계와 적은 데이터의 화자를 가진 모델로 이전하는 것이 더 효율적이라는 것을 발견했습니다. 먼저 LSH 데이터셋을 사용하여 단일 플로우 단계로 Flowtron 모델을 훈련한 후, 이를 더 많은 플로우 단계로 미세 조정하고, 최종적으로 선택적으로 새로운 화자 임베딩과 함께 LibriTTS에서 미세 조정했습니다.
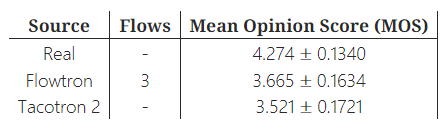
4.2 Mean Opinion Score comparison
연구팀은 LJS 데이터셋의 실제 데이터, 2단계 플로우을 가진 Flowtron 샘플, 그리고 LSH에서 훈련된 Tacotron 2 샘플 간의 평균 의견 점수(MOS)를 비교했습니다. MOS 테스트는 Amazon Mechanical Turk에서 진행되었으며, 평가자들은 청력 테스트를 통과한 후 무작위로 선택된 발화를 듣고 5점 척도로 평가했습니다.
평균 의견 점수는 95% 신뢰 구간과 함께 표 1에 제시되었으며, 결과는 주관적인 평가와 대체로 일치했습니다. Flowtron의 주요 장점은 음성 변동을 제어하고 잠재 공간을 조작할 수 있는 능력입니다.
4.3 Sampling the prior
Flowtron으로 샘플을 생성하는 가장 간단한 방법은 사전 분포에서 샘플링한 후, $σ^2$ 값을 조정하여 변동의 양을 제어하는 것입니다. $σ^2 = 0$일 때는 변동이 제거되어 모델의 편향에 따라 출력이 생성되고, $σ^2$ 값을 높이면 음성의 변동이 증가합니다.
4.3.1 Speech variation
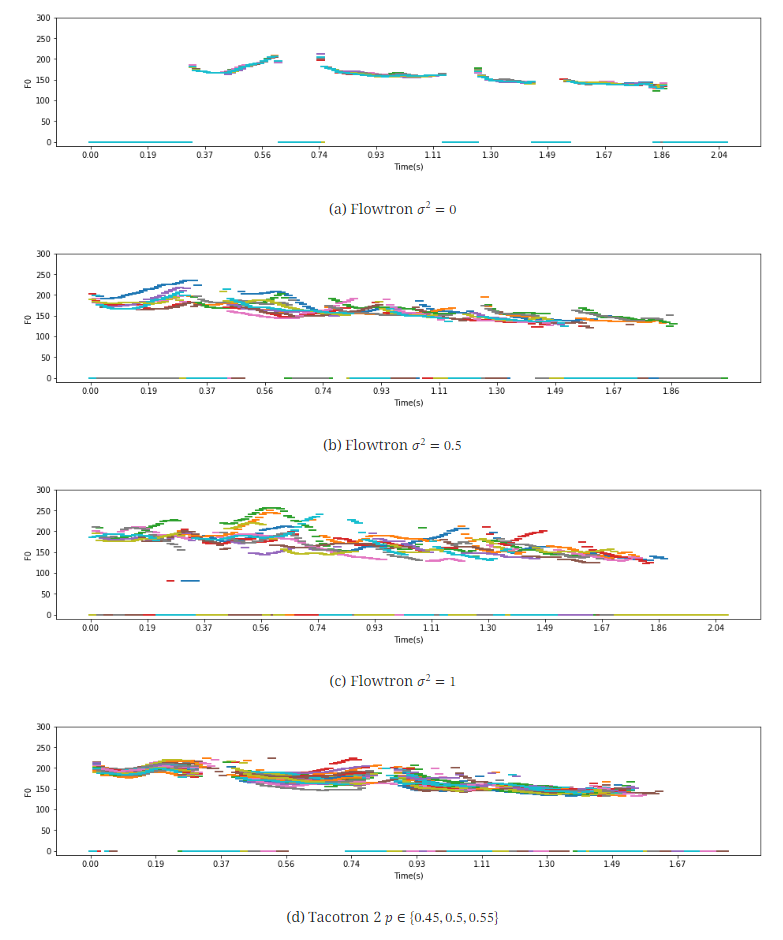
Flowtron에서 음성 변동성과 그 제어를 보여주기 위해, 고정된 화자와 텍스트에 조건화된 10개의 멜-스펙트로그램을 합성하고, $σ^2$ 값을 0.0, 0.5, 1.0으로 조정하여 샘플을 생성했습니다. 결과적으로, $σ^2$ 값을 높일수록 변동성이 증가하지만, 여전히 높은 품질의 음성이 생성됨을 확인했습니다.
또한, Flowtron은 다른 최첨단 모델들과 달리, 복합 손실이나 추가적인 레이어 없이도 선명한 고조파와 잘 정의된 포먼트를 생성합니다. $σ^2$ 값을 조정하면 Tacotron 2보다 더 큰 변동성과 제어를 제공하며, 샘플의 지속 시간과 $F_0$ 윤곽에서도 더 다양한 변화를 만들어냅니다. 특히, $σ^2$ 값을 증가시키면 샘플의 표현력이 크게 향상되는 반면, Tacotron 2에서는 이러한 변동이 거의 발생하지 않음을 알 수 있습니다.
4.3.2 Interpolation between samples
Flowtron을 사용하면 $z$-공간에서 보간을 수행함으로써 멜-스펙트로그램 공간에서 보간을 수행하는 것과 같은 효과를 줄 수 있습니다. 이를 위해 화자 임베딩이 있는 모델과 없는 모델을 각각 평가했습니다.
화자 임베딩이 포함된 실험에서는 Sally 화자와 문장 “It is well known that deep generative models have a rich latent space.“를 사용하여, $z ∼ \mathcal{N}(0,0.8)$에서 두 번 샘플링한 후 그 사이를 100단계에 걸쳐 보간하여 멜-스펙트로그램을 생성했습니다.
화자 임베딩이 없는 실험에서는 Sally와 Helen 간의 보간을 수행했습니다. 먼저 Helen과 Sally의 음성을 각각 생성하는 $z$ 값($z_h$와 $z_s$)을 찾은 후, 이들 사이를 선형으로 보간하며 샘플을 생성했습니다.
결과적으로, 같은 화자 간 보간에서는 Flowtron이 여러 샘플 간의 보간을 통해 올바른 alignment을 생성할 수 있음을 확인했으며, 다른 화자 간 보간에서는 두 화자의 특성을 결합한 새로운 화자를 생성할 수 있음을 보여줍니다.
4.4 Sampling the posterior
이 접근법에서는 관심 있는 음성 특성을 포함한 데이터에 조건화된 사후 확률 분포를 샘플링하여 Flowtron으로 샘플을 생성합니다【Gambardella et al., 2019; Kingma & Dhariwal, 2018】. 실험에서는 추론 중 사용할 화자 ID와 관심 있는 특성을 가진 샘플 세트의 텍스트와 멜-스펙트로그램을 사용해 순방향 패스를 수행하여 사전 데이터 $z_e$를 수집합니다. 필요한 경우, $z_e$를 시간적으로 반복하여 텍스트 길이에 따른 최소 길이 요구사항을 충족시킵니다.
Tacotron 2 GST는 이와 유사한 사후 확률 샘플링 접근법을 사용합니다【Wang et al., 2018】. Tacotron 2 GST에서는 추론 시 기존 오디오 샘플의 임베딩을 통해 쿼리된 글로벌 스타일 토큰(사후 확률)의 가중 합에 모델이 조건화됩니다. 이를 평가하기 위해, 단일 샘플을 사용해 스타일 토큰을 쿼리하는 방법과 여러 샘플의 평균 스타일 토큰을 사용하는 방법 두 가지를 비교합니다.
4.4.1 Seen speaker without alignments
이 실험에서는 기본 주파수 변동이 큰 30개의 Helen 샘플을 기반으로 계산된 후방 분포에 조건화하여 생성된 Flowtron과 Tacotron 2 GST의 Sally 샘플을 비교했습니다. 목표는 단조로운 화자가 더 표현력 있게 들리도록 하는 것입니다.
실험 결과, Flowtron은 후방 분포에서 샘플링하거나 후방 분포와 표준 가우시안 사전 분포를 보간함으로써 단조로운 화자를 점진적으로 더 표현력 있게 만들 수 있음을 확인했습니다. 반면, Tacotron 2 GST는 화자의 특성을 거의 변화시키지 못했습니다.
4.4.2 Seen speaker with alignments
연구팀은 화자 임베딩이 포함된 Flowtron 모델을 사용하여, 청각적으로 쉽게 인지되지만 알고리즘적으로 표현하기 어려운 음향적 특성을 학습하고 전이하는 Flowtron의 능력을 시연했습니다. 이 실험에서, LibriTTS 데이터셋에서 독특한 비음과 $F_0$ 진동이 두드러진 여성 화자를 소스 화자로 선택하고, 그녀의 스타일을 다른 음향적 특성을 가진 남성 화자에게 전이했습니다. 이번 실험에서는 텍스트와 alignment도 여성 화자에서 남성 화자로 함께 전이되었습니다.
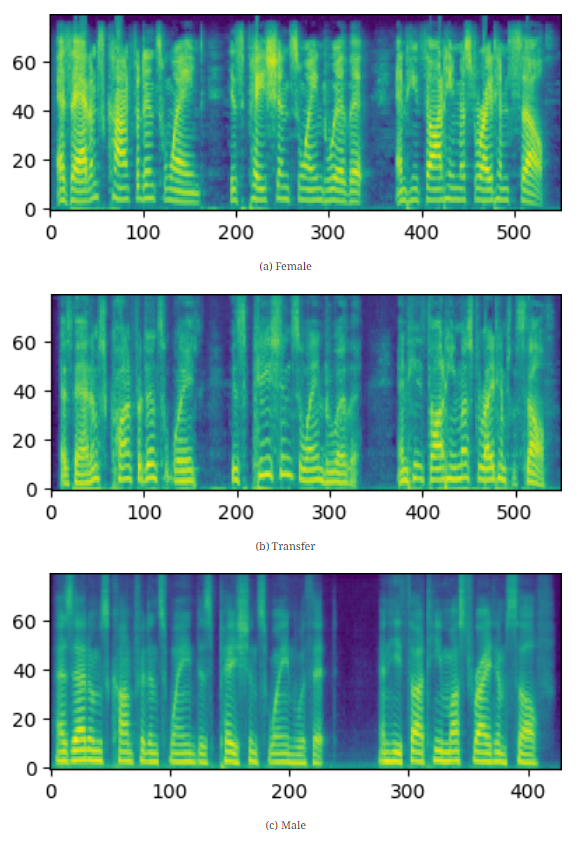
그림 5는 이러한 음향적 특성의 전이를 시각화하려는 시도로, 전이 후 남성 화자의 하부 배음이 더 많이 진동하여 여성 화자와 더 유사해지는 것을 보여줍니다.
4.4.3 Unseen speaker style
연구팀은 동일한 화자의 데이터를 사용하되, 훈련 중에 보지 못한 스타일로 화자의 스타일을 수정한 Flowtron과 Tacotron 2 GST의 샘플을 비교했습니다. Sally의 경우, 훈련 중에는 뉴스 기사 낭독 데이터를 사용했지만, 평가 샘플에서는 음울하고 뱀파이어적인 소설 Born of Darkness에 대한 Sally의 해석이 포함되었습니다.
결과적으로, Tacotron 2 GST는 Born of Darkness 데이터의 음울한 스타일을 모방하는 데 실패했으나, Flowtron은 이 스타일뿐만 아니라 서술적 스타일과 관련된 긴 멈춤도 성공적으로 전이할 수 있음을 확인했습니다.
4.4.4 Unseen speaker
이 실험에서는 훈련 중에 보지 못한 화자의 말하기 스타일을 전이한 Flowtron과 Tacotron 2 GST 샘플을 비교했습니다. 두 모델 모두 화자 임베딩을 사용합니다.
첫 번째 화자는 감정 레이블이 있는 RAVDESS 데이터셋의 화자 ID 03으로, “놀람”이라는 감정에 중점을 두었고, 두 번째 화자는 리처드 파인만으로, 웹에서 수집한 10개의 오디오 샘플을 사용했습니다. 각 실험에서 Sally 화자와 함께 RAVDESS나 파인만의 오디오 샘플에 없는 문장들을 사용했습니다.
결과적으로, Tacotron 2 GST는 RAVDESS의 놀란 스타일이나 파인만의 운율 및 음향적 특성을 모방하지 못했지만, Flowtron은 Sally에게 놀란 느낌을 주고, 파인만의 독특한 말하기 스타일을 성공적으로 전이할 수 있었습니다.
4.5 Sampling the Gaussian Mixture
이 마지막 섹션에서는 Flowtron Gaussian Mixture (GM)의 시각화와 샘플을 소개합니다. 먼저, 다양한 혼합 구성 요소와 화자 간의 상관관계를 조사한 후, 개별 구성 요소의 한 차원을 변환하여 음성 특성을 조절한 음성 예제를 제공합니다.
4.5.1 Visualizing assignments
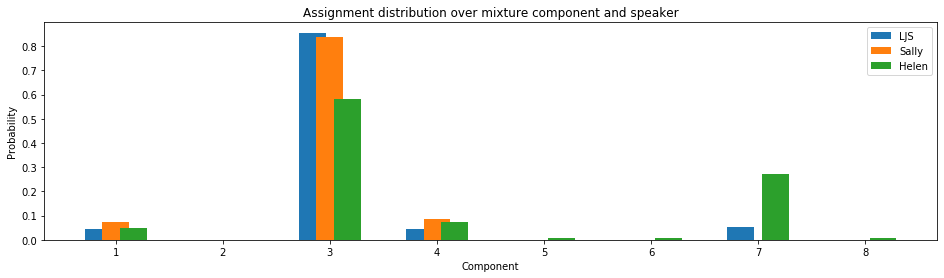
첫 번째 실험에서는 LSH 데이터셋을 사용하여 2단계 플로우, 화자 임베딩, 고정된 평균 및 공분산을 가진 Flowtron Gaussian Mixture (Flowtron GM-A)를 훈련했습니다. 순방향 패스를 통해 멜-스펙트로그램별로 혼합 구성 요소 할당을 얻었으며, 그림 6에서 대부분의 화자가 모든 구성 요소에 균등하게 할당된 반면, Helen의 데이터는 주로 구성 요소 7에 할당되었습니다.
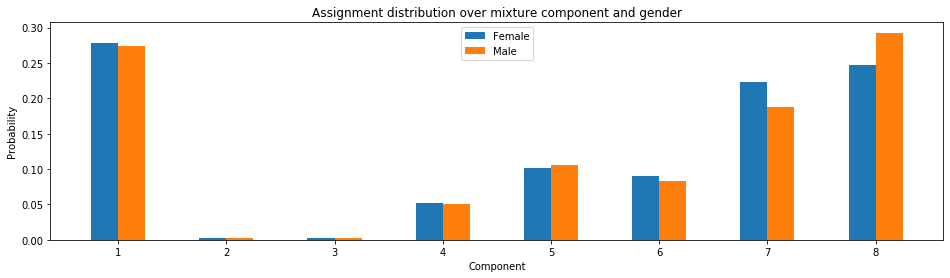
두 번째 실험에서는 LibriTTS 데이터셋에서 화자 임베딩 없이 예측된 평균과 공분산을 사용하여 1단계 플로우로 구성된 Flowtron Gaussian Mixture (Flowtron GM-B)를 훈련했습니다. 그림 7은 화자가 남성일 때 구성 요소 7에 더 높은 확률이 할당되고, 화자가 여성일 때는 구성 요소 6에 더 높은 확률이 할당되는 결과를 보여줍니다. 이는 구성 요소에 저장된 정보가 성별에 따라 달라질 수 있음을 시사합니다.
4.5.2 Translating dimensions
이 하위 섹션에서는 앞서 설명한 Flowtron GM-A 모델을 사용하여, 단일 혼합 구성 요소를 선택하고 오프셋을 추가하여 그 구성 요소의 한 차원을 변환하는 실험을 다룹니다.
연구팀의 보충 자료에 있는 샘플들은 피치와 단어 길이와 같은 특정 음성 특성을 조절할 수 있음을 보여줍니다. 피치 높이와 관련된 차원을 변환하여 생성된 샘플들은 서로 다른 피치 윤곽을 가지지만, 동일한 지속 시간을 유지합니다. 또한, 첫 번째 단어의 길이와 관련된 차원을 변환해도 첫 번째 단어의 피치에는 영향을 미치지 않습니다. 이는 이러한 차원을 조작함으로써 특정 음성 속성을 조절할 수 있으며, 모델이 이 속성들을 분리하여 표현할 수 있음을 증명합니다.
5 Discussion
이 논문에서 연구팀은 우도(likelihood)를 최대화하여 최적화되고, 음성 변동 및 스타일 전이를 제어할 수 있는 자가회귀 플로우 기반의 새로운 텍스트-멜-스펙트로그램 합성 모델, FlowTron을 제안합니다. 실험 결과, FlowTron으로 생성된 샘플들이 최첨단 텍스트-음성 변환 모델들과 유사한 평균 의견 점수(MOS)를 기록했으며, 추가 비용이나 복합 손실 항 없이 비텍스트 정보를 저장하는 잠재 공간을 학습할 수 있음을 확인했습니다.
FlowTron은 사용자가 소스 샘플이나 화자의 특성을 타겟 화자에게 전이할 수 있는 가능성을 제공하여, 예를 들어 단조로운 화자를 더 표현력 있게 만들 수 있습니다. 또한, $\sigma^2$ 값을 조정하여 추가된 변동성에도 불구하고 여전히 높은 품질의 음성을 생성하며, 비텍스트적 특징에 대한 잠재 공간을 학습해 사용자가 생성 모델의 출력을 더 세밀하게 제어할 수 있게 합니다.
연구팀은 여러 예제를 통해 멜-스펙트로그램에서 변동성을 제어 가능한 방식으로 증가시키고, 화자의 스타일을 전이하며, 단조로운 화자를 표현력 있게 만드는 방법을 시연했습니다. FlowTron은 레이블된 데이터 없이도 표현력 있는 음성을 생성하며, 텍스트-음성 변환의 표현적 한계를 넘어 인간-컴퓨터 상호작용과 예술 분야에서 새로운 가능성을 열어주었습니다. 또한 이 연구는 텍스트-멜-스펙트로그램 합성에서 정규화 플로우 모델의 이점을 처음으로 입증한 것입니다.