Glow - Generative Flow with 1x1 Convolutions
Glow - Generative Flow with 1x1 Convolutions
- NeurIPS 2018
- Durk P. Kingma, Prafulla Dhariwal
Abstract
음성뿐만 아니라 생성 모델은 원하는 데이터를 정확히 표현하는 확률 분포를 알고 있다면 쉽게 모델링할 수 있어요. 하지만 대부분의 경우, 우리가 다루고자 하는 확률 분포는 이해하기 어렵고 계산하기도 복잡해요. 예를 들어, 빨간색이 많이 포함된 이미지를 생성하고 싶다면, 단순히 RGB 채널 중 R 값이 높은 확률 분포를 선택하는 것으로 충분할 수 있어요. 그러나 ‘시바견🐕을 생성하는 확률 분포를 찾아라’와 같은 문제는 훨씬 더 복잡하죠. 심지어 아래 예시는 단순화된 확률 분포를 보여주는 것이며, 실제로는 이보다 훨씬 고차원의 분포를 다루게 됩니다.
이 내용을 기반으로 하면, 생성 모델이 데이터를 모델링하는 과정은 실제로 복잡한 확률 분포를 이해하고 그것을 기반으로 새로운 데이터 샘플을 생성하는 일이라고 할 수 있어요. 복잡한 이미지나 소리와 같은 데이터를 처리할 때는 특히 더 도전적이죠. 따라서, 우리는 보다 단순한 분포들(예: 가우시안 분포)을 여러 개 결합해, 최종적으로 복잡한 분포를 정확하게 표현할 수 있는 방법을 모색하게 됩니다. 이 중 하나로서, flow 또는 normalizing flow 기법의 도입이 있습니다. 특히 이 논문에서는 normalizing flow 연산을 적용하면서도, 1x1 컨볼루션 연산을 통한 flow 기반 생성 모델을 구현함으로써 다양한 이점을 얻을 수 있다고 주장합니다. 이러한 접근 방식은 복잡한 데이터 분포를 모델링하는 데 있어 효율적이고 강력한 방법을 제공한다는 점에서 그 중요성이 큽니다.
1. Introduction
논문의 서론 부분은 생성 모델이 지금까지 어떻게 발전해왔는지 그리고 머신러닝 분야에서 여전히 남아 있는 문제들에 대해 다룹니다. 특히, 머신러닝이 현재 직면하고 있는 두 가지 주요 문제, 즉 data efficiency와 generalization에 초점을 맞춥니다.
- data efficiency: 사람처럼 적은 데이터로도 충분히 패턴을 파악할 수 있는 능력
- generalization: 학습된 모델이 다른 작업에서도 비교적 강건하게 임무를 수행할 수 있는 능력
생성 모델이 데이터 효율성과 일반화 문제를 어떻게 완화시키는지에 대한 한 방법은, 모델에게 별도의 라벨링 없이 데이터만 제공하면, 그 모델이 내부적으로 주요 특징들을 스스로 파악할 수 있다는 것입니다. 이는 특정한 작업에만 초점을 맞춘 데이터를 입력하는 것이 아니라, 대용량 데이터셋에 포함된 다양한 범용 데이터를 활용함으로써 가능해집니다. 이로 인해 모델은 관련된 다양한 하위 작업들에서도 효과적으로 작동할 것으로 기대됩니다. <생성모델의 강점 소개!>
생성 모델은 크게 가능도(likelihood) 기반 모델과 GAN(Generative Adversarial Networks) 기반 모델로 나눌 수 있습니다. 이 두 범주는 생성 모델의 핵심적인 접근 방식을 대표하며, 각각의 고유한 장점과 적용 분야가 있습니다. 본 논문에서는 가능도 기반 모델에 보다 깊이 있게 집중합니다. 가능도 기반 모델 중에서도 flow 기반 생성 모델이 포함되는데, 이는 가능도를 직접적으로 모델링하는 데 초점을 맞춘 방식 중 하나입니다.
- Autoregressive models
- Variational Autoencoders (VAE)
- Flow based generative models
Flow 기반 생성 모델은 역변환이 가능한 함수를 사용하여 여러 가지 중요한 이점을 얻습니다. 첫 번째로, VAE와 달리 확률 밀도 함수나 확률 분포에 대한 정확한 추정이 가능합니다. 이는 둘 다 인코더와 디코더를 사용함에도 불구하고, Flow 기반 모델이 역변환이 가능한 함수를 통해 이러한 정확성을 달성한다는 점에서 차이가 있습니다. 추가로, Flow 기반 모델은 병렬 처리 측면에서도 강점을 가지고 있어, 학습과 추론 과정 모두에서 병렬 연산을 가능하게 합니다.
그래서, 저자인 Kingma가 제시한 것이 바로 Glow입니다. Glow는 메모리 효율적이며, 병렬 처리에 최적화된 flow 기반의 생성 모델이죠. 이 모델은 복잡한 데이터를 합성하고 추론하는 과정에서 높은 효율성을 보입니다. 아래부터는 Glow, 즉 flow 기반 생성 모델이 어떤 원리로 작동하는지, 필요한 조건은 무엇인지, 그리고 이 모델이 어떻게 효율적인 연산을 가능하게 하는지 자세히 살펴보려 합니다.
2. Background: Flow-based generative models

실제 데이터셋을 완벽하게 나타내는 정확한 분포 $p^*(\mathbf{x})$가 있다고 가정해보겠습니다. 여기서 실제 분포로부터 추출된 고차원 데이터 $\mathbf{x}$는 우리가 관찰할 수 있는 샘플입니다. 우리의 궁극적인 목표는 이 실제 분포를 찾아내는 것이며, 이를 위해 딥러닝 모델을 사용합니다. 모델을 학습시키기 위해서는, 우리는 임의의 학습 분포 $p_\theta (\mathbf{x})$를 설정하고, 이 분포의 가능도를 높이는 방향으로 모델을 학습시키려 합니다.
가능도(likelihood)는 주어진 데이터가 특정 확률 분포에서 나올 가능성을 나타냅니다. 따라서, 우리가 실제 데이터를 모델에 제공하고 그 가능도를 최대화하려는 시도는, 실제 확률 분포를 모델링하는 것과 동일한 과정이 됩니다. 이 과정에서 사용하는 손실 함수 $\mathcal{L}$은 다음과 같이 정의할 수 있습니다.
- $\mathcal{D}$: 실제 정답 분포 $p^{*}$ 에서 추출한 데이터셋
- 위 손실함수는 Negative Log Likelihood (NLL)으로 잘 알려져있는 식!
딥러닝 모델이 학습을 통해 배우는 분포, 즉 $p_\theta$ 의 가능도를 높이는 것이 목표인 것까지는 알고 있었지만, 실제로 이를 어떻게 구현할지가 큰 문제였습니다. 우리가 모델링하고자 하는 실제의 정답 분포는 너무나도 복잡해서, 이를 정확하게 구해내기란 쉽지 않다고 이전에 설명드렸죠. 이러한 문제를 해결하는 한 방법으로 normalizing flow의 적용이 있습니다. 그리고 이번에는 normalizing flow를 수학적으로 어떻게 표현할 수 있는지 살펴보려 합니다.
생각해보세요, 가장 간단하면서도 잘 알려진 가우시안 분포를 시작점으로 삼는다면 어떨까요? 가우시안 분포로부터 임의로 추출된 잠재변수 $\mathbf{z}$가 있다고 해볼게요. 만약 우리가 이 $\mathbf{z}$에 어떤 변환 $g_\theta (\mathbf{z})$를 적용하여 우리가 찾고자 하는 실제 데이터 $\mathbf{x}$를 정확하게 얻어낼 수 있다면, 그야말로 이상적인 상황이겠죠. 하지만 여기서 한 발 더 나아가, 만약 이 변환 함수 $g_\theta$가 invertible하다는 것, 즉 역변환도 가능하다면, 우리는 정확한 분포를 추정할 수 있게 됩니다. 바로 이 아이디어가 Flow 기반 생성 모델의 핵심이에요.
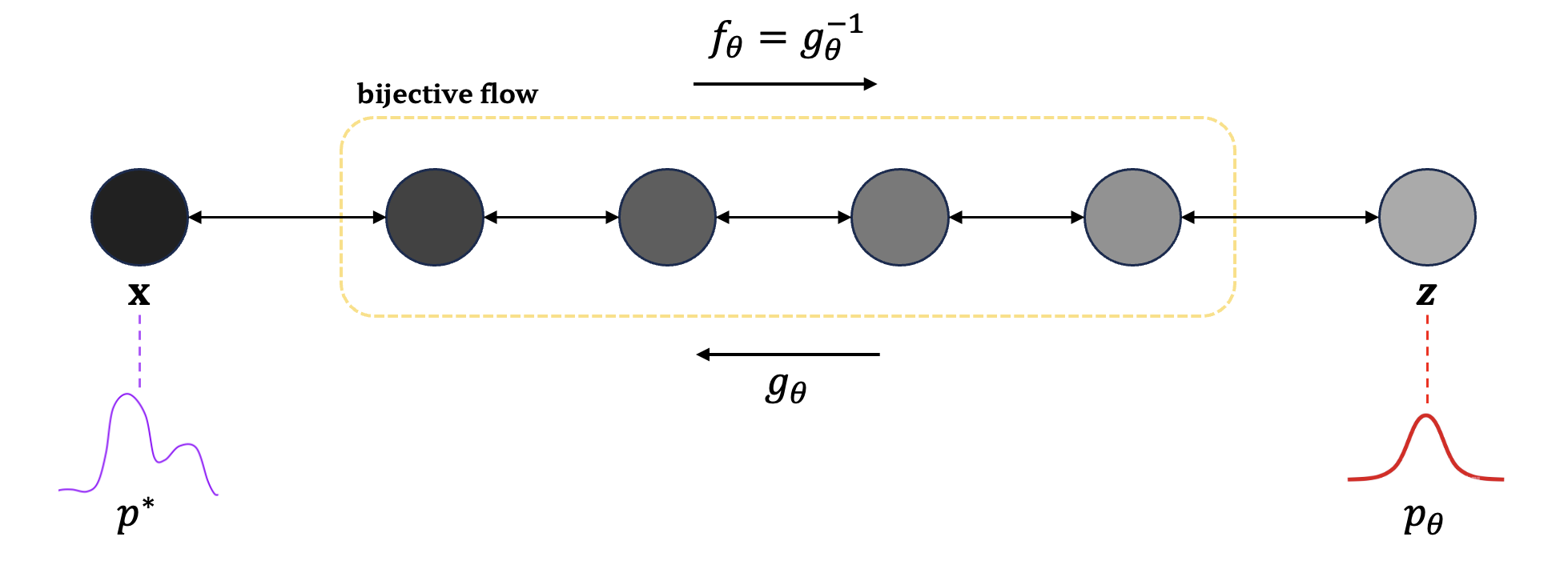
여기서 더 흥미로운 점이 하나 있습니다. 바로 변수변환 정리(change of variables) 덕분에, 우리는 확률밀도함수가 변환을 거치며 어떻게 밀도가 변화하는지를 계산할 수 있게 됩니다. 이것이 바로 모델이 normalizing flow를 사용하는 이유입니다. 이 과정을 통해, 몇 가지 간단한 분포들만으로도 원하는 정확한 분포를 찾아낼 수 있게 되죠. 아래 식은 변수변환 정리를 사용하여 변화하는 밀도(log scaled)를 계산하는 방법을 보여줍니다.
하지만, 여기에서 한 가지 문제가 발생합니다. 실제 모델에서는 행렬을 기반으로 연산이 이루어지기 때문에, 우리가 다뤄야 하는 것은 바로 행렬식(determinant)이 되는데요, 이는 Jacobian 행렬의 행렬식을 계산하는 것과 같습니다. 그런데 행렬식을 계산하는 일이 그리 간단한 연산이 아니라는 점이 문제입니다. 상당히 많은 연산량을 요구하죠.
이 문제를 해결하기 위해, Kingma를 포함한 이전 연구에서는 삼각행렬을 사용해 이 연산을 대단히 간단하게 만드는 방법을 고안했습니다. 그리고 본 논문에서도 이 방법을 채택하고 있습니다. 흥미로운 사실은, 상삼각행렬 또는 하삼각행렬의 determinant는 바로 대각 성분들의 곱과 같다는 것입니다. 여기서 우리는 log를 취해 계산하기 때문에, 결국 대각성분들의 합이 Jacobian 행렬의 행렬식을 나타내게 됩니다.
3. Proposed Geneartive Flow
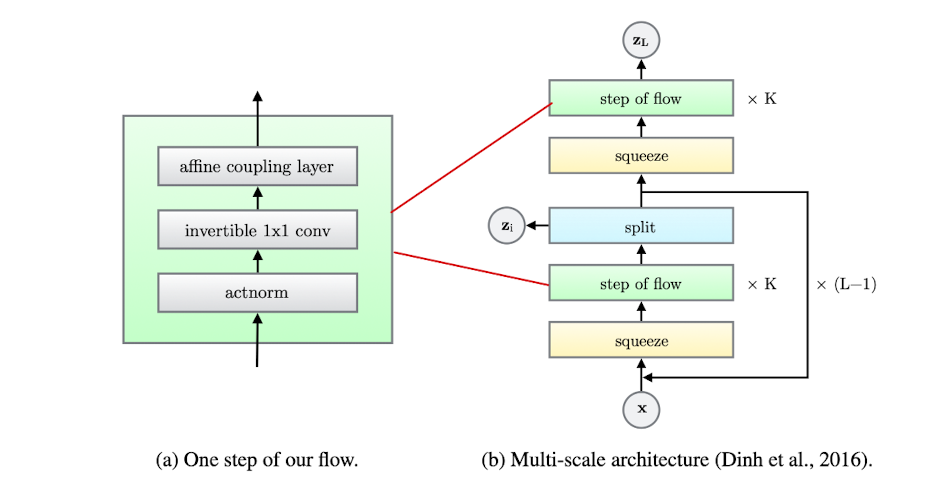
3.1. Actnorm: scale and bias layer with data dependent initialization
batch normalization 기술이 처음 소개되었을 때, 많은 이들이 그 혁신에 주목했습니다. 이 방법은 더 깊은 신경망을 학습시킬 때 발생하는 주요 문제 중 하나인, 배치마다 학습 데이터의 분포가 달라지는 현상을 해결하기 위해 고안되었죠. 이는 학습 과정을 안정화시키고, 속도를 향상시키는 데 큰 도움이 되었습니다.
그러나, batch normalization에는 명확한 한계가 있었습니다. 바로 1대의 GPU가 처리할 수 있는 데이터 양에 따라 그 효율성에 큰 차이가 있다는 점이었죠. 특히, 초고해상도 이미지를 다룰 때, 간혹 1개의 배치에 단 1개의 이미지만을 올릴 수 있는 상황도 발생합니다. 이런 경우, batch normalization의 이점을 전혀 활용할 수 없게 되는데요, 이는 실제로 많은 연구자들과 개발자들에게 큰 도전 과제로 다가왔습니다.
바로 이 파트에서 설명할 Actnorm 레이어가 이 단점을 해결합니다. batch normalization이 각 배치 내에서 학습 데이터의 분포를 일정하게 유지시켜주는 방법으로 널리 알려져 있지만, Actnorm은 조금 다른 접근을 제시합니다. Actnorm은 맨 처음 배치의 평균과 분산을 기준으로 삼아, 이후 등장하는 모든 데이터들이 그 첫 번째 배치와 동일한 분포를 가지도록 조정해줍니다. 이는 특히 배치 사이즈에 제약이 있는 상황에서, 일관된 데이터 분포를 유지하면서도 학습의 안정성과 효율성을 높이고자 할 때 큰 도움이 됩니다.
3.2. Invertible 1x1 convolution
이전에 Normalizing flow를 활용했던 모델들을 살펴보면, 역변환이 가능한 함수를 정의할 때 임의의 permutation 함수, 즉 행렬의 각 열의 순서를 바꾸는 연산을 사용했던 것을 볼 수 있습니다. 하지만 본 논문의 저자는 한 발짝 더 나아가, 이 연산을 1x1 convolution으로 대체함으로써 연산의 효율성을 크게 향상시켰다고 합니다.
그렇다면, 기존 상태 $\mathbf{h}$에 1x1 convolution을 적용할 때 사용하는 $\mathbf{W}$를 통해 이루어지는 변화는 어떻게 이해할 수 있을까요? 이는 바로 변수변환 정리를 통해 생기는 밀도의 변화를 아래와 같이 나타낼 수 있습니다.
- 여기서 높이 $h$ 와 너비 $w$ 가 따로 빠질 수 있는 것은 행과 열 1칸마다 convolution 연산을 진행하기 때문이라 볼 수 있음!
- $\mathbf{h}$ 는 높이 $h$, 너비 $w$, 채널 $c$ 를 갖는 ($h, w, c$) 크기의 텐서
- $\mathbf{W}$ 는 높이 $1$, 너비 $1$, 입력 채널 $c$, 출력 채널 $c$ 를 갖는 ($1, 1, c, c$) 크기의 텐서
원래 $\mathbf{W}$의 행렬식을 계산하는 과정은 시간이 상당히 많이 소요됩니다. 구체적으로, 계산 복잡도는 $\mathcal{O}(c^3)$에 달하는데요, 여기서 $c$는 채널의 수를 의미합니다. 이는 특히 채널 수가 많을 때, 상당한 연산 부담으로 작용할 수 있습니다.
하지만, 저자는 이러한 연산 부담을 혁신적으로 줄이는 방법을 제안했습니다. 바로 행렬을 상삼각행렬과 하삼각행렬 두 개로 분해하여 계산하는 LU Decomposition 기법을 도입한 것이죠. 이 기법을 사용함으로써, 연산량을 $\mathcal{O}(c)$로 대폭 감소시킬 수 있었습니다.
3.3. Affine Coupling Layers
1x1 컨볼루션 연산 후, 우리의 모델은 또 다른 변환 레이어를 거치게 됩니다. 이 과정에서도 역변환이 가능하며, 행렬식(determinant)을 쉽게 계산할 수 있는 구조가 필요했습니다. 이러한 요구사항을 만족시키는 데에 완벽한 해결책을 제시하는 것이 바로 2014년에 처음 고안된 affine coupling layer입니다.
Affine coupling layer는 입력 데이터에 대한 변환을 수행하되, 연산이 반드시 삼각행렬의 형태로 이루어지도록 설계된 매우 특별한 레이어입니다. 이 설계 덕분에, 변환 과정에서의 행렬식 계산이 훨씬 간소화되며, 이는 전체 모델의 연산 효율성을 크게 향상시킵니다.
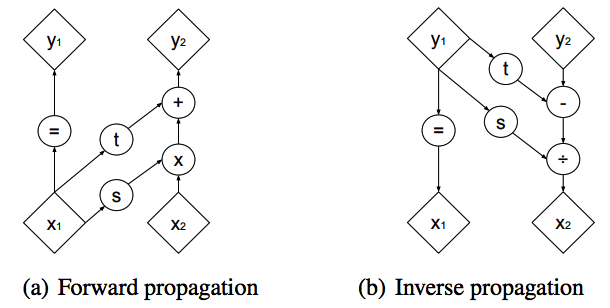
그림을 자세히 살펴본다면, 입력 $x$가 두 부분, $x_1$과 $x_2$로 나누어지는 과정을 확인할 수 있습니다. 이 과정에서 하나는 그대로 출력으로 넘어가고, 다른 하나는 여러 변환 연산을 거친 후, 결과적으로 $y_1, y_2$라는 출력을 내놓게 됩니다.
이런 방식으로 입력을 반으로 나누어 연산을 진행하는 이유는 매우 흥미롭습니다. 바로 이렇게 할 경우, 미분을 통해 얻어지는 Jacobian 행렬이 삼각행렬의 형태로 나타나게 되기 때문입니다. 이는 전체 변환 과정의 복잡성을 대폭 줄여주며, 연산의 효율성을 높이는 중요한 역할을 합니다.
4. Quantitative Experiments
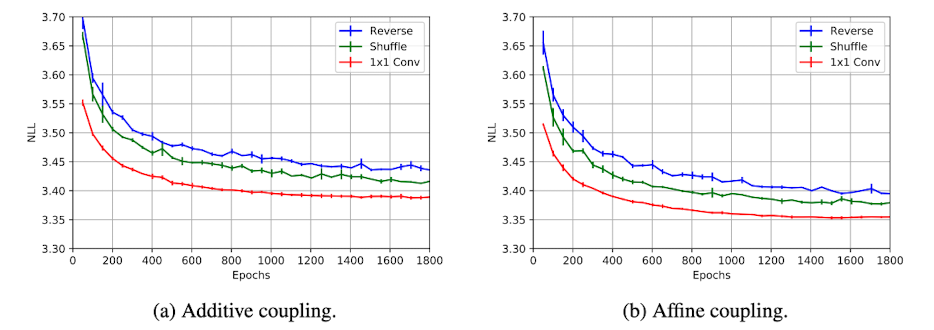
1x1 컨볼루션을 사용하면서 얻을 수 있는 이점은 다양한 방식으로 입력 데이터의 채널에 변화를 주는 방법들과 비교해 볼 때 더욱 두드러집니다. 비교 대상은, RealNVP에서 고안된 채널 순서를 뒤집는 reverse 연산과, 채널을 섞어주는 shuffle 연산, 그리고 본 논문에서 제안하는 1x1 컨볼루션 연산입니다.
평가 지표로 사용된 Negative Log Likelihood (NLL)를 통해, 다른 방법들과 비교했을 때 1x1 컨볼루션 연산을 사용한 경우 가장 빠르게 손실이 감소하는 형태를 보여준다는 것을 알 수 있습니다. 이는 1x1 컨볼루션 연산이 효율성 면에서 우월함을 시사하는 중요한 증거입니다.
5. Qualitative Experiments
저자가 진행한 모델 평가에는 단순한 숫자로의 평가뿐만 아니라, 모델이 얼마나 잘 작동하는지를 보여주는 정성적인 평가도 포함되었습니다. 이번 평가에서는, 이전 실험들에서 사용한 32x32나 64x64 크기의 이미지를 다운샘플링하는 대신, 256x256 해상도의 CelebA-HQ 데이터셋을 활용했습니다. 이는 모델이 잠재변수들을 얼마나 잘 매핑하고, 의미 있는 잠재공간을 생성하고 있는지를 더욱 정밀하게 평가하기 위함이었습니다.
예를 들어, 만약 ‘스폰지밥’과 ‘뚱이’라는 두 이미지를 잠재공간에 매핑하고, 이 두 공간 사이를 선형적으로 보간한다면, 스폰지밥과 뚱이 사이에서 어떤 이미지들을 추출할 수 있을까요? 이 아이디어는 모델이 얼마나 풍부하고 다양한 변형을 잠재공간에서 생성할 수 있는지를 시험해 보는 흥미로운 방법입니다.


실제로 잘 훈련된 모델을 통해 중간 지점에서 샘플링한 이미지들을 확인해보니, 실제 이미지와 거의 유사한 결과를 만들어냈다는 점이 놀라웠습니다. 이 과정에서, 저자는 노이즈를 다양하게 섞어보기도 했습니다. 흥미롭게도, 1에 가까운 노이즈를 추가했을 때는 이미지가 손상되는 듯한 느낌이 강해지는 반면, 0.7 정도의 노이즈를 추가했을 때는 다양하고 흥미로운 이미지를 생성하는 데 있어 최적의 ‘temperature’로 작용했다고 합니다.
이는 모델이 단순히 이미지를 재현하는 데 그치지 않고, 다양한 변형을 통해 새로운 이미지를 생성할 수 있는 능력을 가지고 있음을 시사합니다. 특히, 노이즈의 양을 조절하여 생성되는 이미지의 다양성을 조절할 수 있다는 점은, 이 모델의 유연성과 창의적인 활용 가능성을 보여줍니다.
6. Conclusion
저자가 이번에 소개한 Glow라는 새로운 flow 기반 생성 모델은, 단순히 새로운 이름을 넘어서는 중대한 발전을 의미합니다. 실제 실험을 통해, 이 모델이 기존의 방식들을 크게 뛰어넘는 로그 가능도 성능을 보여주었을 뿐만 아니라, 고해상도 얼굴 이미지 생성에서도 현실과 구분하기 어려운 수준의 결과물을 만들어내는 능력을 보여주었습니다.
특히 흥미로운 점은, 확률 기반 모델을 이용한 고해상도 자연 이미지의 효율적인 합성 작업이 이번이 처음이라는 것입니다. Glow 모델은 이 분야에서 선구적인 역할을 하며, 앞으로 생성 모델이 나아갈 방향성에 대한 기대를 한껏 높여줍니다.
7. References
[1] Kingma, D. P., & Dhariwal, P. (2018). Glow: Generative flow with invertible 1x1 convolutions. Advances in neural information processing systems, 31.
[2] Dinh, L., Krueger, D., & Bengio, Y. (2014). Nice: Non-linear independent components estimation. arXiv preprint arXiv:1410.8516.
[3] Dinh, L., Sohl-Dickstein, J., & Bengio, S. (2016). Density estimation using real nvp. arXiv preprint arXiv:1605.08803.