GlowTTS - A Generative Flow for Text-to-Speech via Monotonic Alignment Search
GlowTTS - A Generative Flow for Text-to-Speech via Monotonic Alignment Search
- NeurIPS 2020
- Jaehyeon Kim, Sungwon Kim, Jungil Kong, Sungroh Yoon
Abstract
기존의 Parallel TTS(Text-to-Speech) 모델들은 학습 과정에서 반드시 별도의 외부 *aligner를 필요로 하는 문제가 있었다. 이러한 배경을 바탕으로, 저자들은 외부 aligner 없이도 효과적으로 학습할 수 있는 새로운 flow 기반 TTS 모델인 Glow-TTS를 제안한다. 구체적으로 Glow-TTS 모델은 flow 기반 생성 모델의 장점을 살리면서, 동적 계획법(Dynamic Programming) 알고리즘을 적용하여 설계된 모델이다. 이러한 접근 방식은 모델이 복잡한 음성과 텍스트 사이의 정렬 문제를 내부적으로 해결할 수 있게 하여, 외부 aligner에 의존하지 않고도 고품질의 음성을 생성할 수 있도록 해준다.
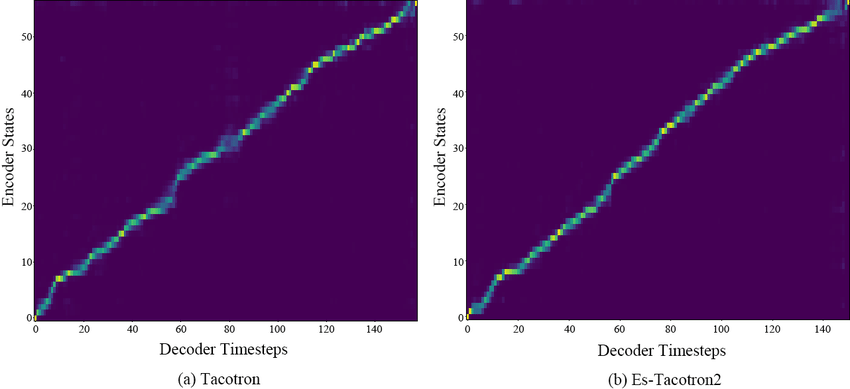
출처: ES Tacotron2
여기서 말하는 aligner는 간단히 말해 음성과 텍스트를 매핑시켜주는 alignment를 생성하는 도구라고 이해할 수 있다. 정확히는 음성에 대한 잠재변수와 텍스트의 잠재변수를 매핑시켜주는 것이다. Alignment가 있으면 해당 글자를 언제 얼마나 길게 발음해야하는지 파악하는 것이 가능하다.
1. Introduction
이전 timestep의 결과를 활용하여 현재 timestep의 mel frame을 예측하는 auto-regressive 모델들은 우수한 성능을 보여주고 있지만, 병렬 처리를 할 수 없어 추론 속도 측면에서는 떨어진다. 이로 인해 실제 서비스에 적용하는 데 어려움이 있으며, 이는 단점으로 여겨진다. 음성을 합성하는 데 걸리는 시간은 입력 텍스트의 길이에 비례해서 증가하며, 단어가 반복되어 등장하는 문장이 있을 경우 attention 계산에서 문제가 발생할 수도 있다.
Autoregressive 모델의 단점을 극복하기 위해 non-autoregressive 모델들이 등장했다. 이 중에서 가장 대표적인 예가 FastSpeech다. FastSpeech는 병렬 처리를 가능하게 함으로써, 이전 모델들보다 훨씬 빠르게 mel-spectrogram을 생성할 수 있게 해주었다. 뿐만 아니라, 부정확한 발음, 단어 생략, 단어 반복과 같은 문제도 해결했는데, 이는 alignment를 단조 증가하도록 제한하였기 때문이다.
Non-autoregressive 모델들은 빠른 처리 속도를 제공하지만, 별도의 외부 aligner를 필요로 하는 한계를 지니고 있다. 이로 인해 모델 자체의 구조뿐만 아니라 외부 aligner의 성능에 따라 음성 합성의 품질이 크게 영향을 받게 되었다. 이 지점에서 저자는 별도의 외부 aligner 없이도 병렬로 추론이 가능한 Glow-TTS를 제안한다. 구체적으로, alignment에서 음성의 로그 가능도를 최대화하는 방향으로 모델을 학습하는 방법에 대해 나중에 자세히 설명할 예정이다. 이로 인해 Glow-TTS는 Tacotron2 모델에 비해 약 15.7배 빠르게 음성을 생성할 수 있었으며, 입력 문장의 길이가 길어도 빠른 시간내에 정확하게 음성을 생성하는 능력을 보였다.
2. Related Work
2.1. Alignment Estimation between Text and Speech
텍스트와 음성사이의 alignment를 찾는 방법에는 2가지가 있다.
- Hidden Markov Models(HMMs)
- CTC: HMMs의 단점을 보완하여 등장한 개념
위 2가지 방법 모두 동적계획법(Dynamic Programming, DP)알고리즘을 사용하며 Glow-TTS도 위와 유사하게 동적계획법 알고리즘을 사용하여 alignmnent를 생성해낸다. Glow-TTS와 다른 2가지 alignment를 찾는 방법 사이에 주요 차이점은 다음과 같다.
- Glow-TTS vs. HMMs: 조건부 독립이라는 가정없이 병렬 샘플링이 가능하다.
- Glow-TTS vs. CTC: 생성모델이라는 차이에서 구분된다.
2.2. Text-to-Speech Models
TTS(Text-to-Speech) 모델은 텍스트로부터 음성을 생성하는 모델이다. 이 분야에는 다양한 모델들이 존재하지만, mel-spectrogram을 병렬적으로 생성할 수 있는 대표적인 모델로는 FastSpeech와 ParaNet이 있다. 그러나 이 모델들의 주된 단점은 별도의 aligner가 필요하다는 점이다. 이는 다른 모델과의 결합 사용을 필수적으로 요구한다는 것을 의미한다. 그럼에도 불구하고, 이 글에서 소개하는 Glow-TTS는 별도의 aligner 없이도 모델 내에서 자체적으로 입력에 대한 alignment를 생성해내는 차별화된 접근 방식을 제공한다.
2.3. Flow-based Generative Models
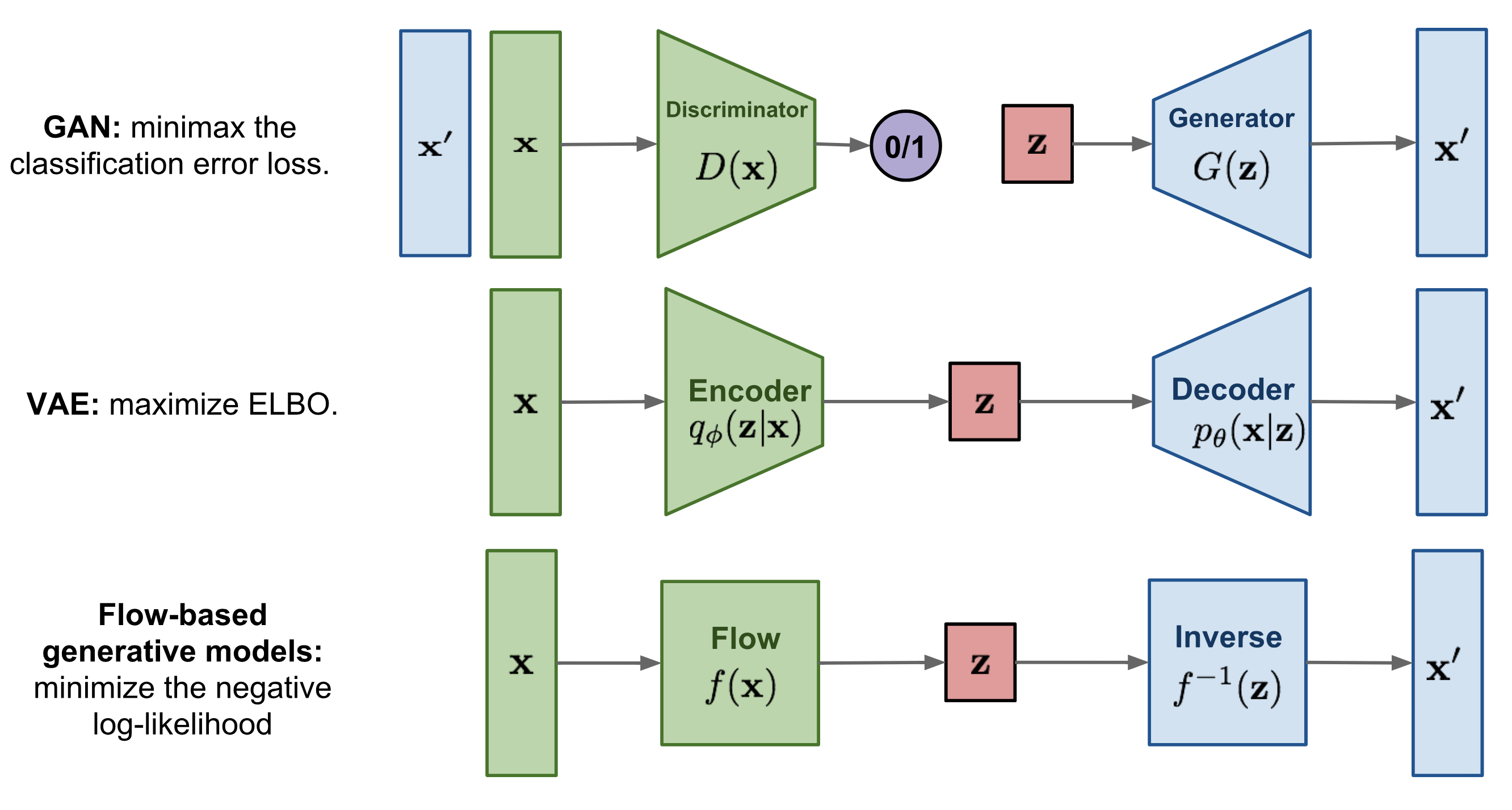
본 논문에서 수학적으로 가장 어려웠던 부분은 아마도 여기일 것 같다. 생성 모델에는 주로 GAN(Generative Adversarial Networks) 모델, VAE(Variational AutoEncoders)와 같은 오토인코더 계열 모델, 그리고 마지막으로 Flow 기반 생성 모델이 있다. Flow 기반 생성 모델의 주요 특징은 역변환이 가능한 함수를 사용하는 것이다. 이들 간의 주요 차이점은 아래 그림에서 간략하게 설명되어 있으며, 자세한 내용은 본론에서 다루어진다.
사실, 외부 aligner의 도움 없이 TTS 모델을 만들려는 노력은 Glow-TTS 뿐만이 아니었다. 동시에 alignTTS, FlowTTS 제안되었으며 flow기반 음성합성 모델로는 flowtron이 제안되었다.
- alignTTS: 외부 aligner를 필요로 하지 않지만 flow 기반 생성 모델은 아니다.
- Flowtron: flow 기반 모델로서 음성 스타일의 변화제어가 가능하다는 장점이 있다.
- FlowTTS: 외부 aligner를 필요로 하지 않는다.
3. Glow-TTS
3.1. Training and Inference Procedures
여기서 부터 flow 기반 생성모델의 개념과 함께 alignment를 생성하는 방법 그리고 이를 최적화 하는 목적함수 등을 정의한다. 논문에 있어서 핵심적인 부분이며 공부하면서 가장 어려웠던 부분이기도 하다. *참고: Flow Based Generative Models1

Glow-TTS는 mel-spectrogram의 조건부 확률분포인 $P_X(x \vert c)$를 모델링한다. 실제 mel-spectrogram의 확률 분포는 그 복잡성으로 인해 직접 추정하기 어려우므로, 조금 더 단순한 확률 분포인 $P_Z(z \vert c)$로 대체하여 모델링하는 접근 방식을 채택한다. Flow 기반 생성 모델의 핵심은 역함수를 가질 수 있는 변환 함수를 사용하는 것이다. 여기서, 잠재 변수 $z$를 입력 데이터 $x$로 변환하는 디코더 함수 $f_{dec}: z \rightarrow x$가 사용된다. 이는 flow 기반 생성 모델의 특성상 역함수 $f_{dec}^{-1}: x \rightarrow z$가 존재한다는 것을 의미한다, 따라서 모델은 $x$로부터 $z$를 추론할 수 있고, 이 과정을 통해 복잡한 데이터 분포를 학습하며 높은 품질의 음성 합성을 달성한다.
Flow 기반 생성 모델을 이해하기 위한 기초 중 하나는 확률 밀도 함수(PDF)의 특성을 이해하는 것이다. 확률 밀도 함수의 핵심적인 특성 중 하나는, 모든 가능한 사건의 확률을 합한 값, 즉 전체 구간 $[ -\infty, +\infty]$에 대해 적분한 결과가 1이 된다는 것이다. 이는 어떠한 사건이 발생할 확률의 총합이 반드시 1이 되어야 한다는 확률론의 기본 원칙을 반영한 것이다. 이러한 특성은 확률 변수가 취할 수 있는 모든 가능한 값에 대해 정의된 확률의 총합이나, 확률 분포 아래의 전체 면적이 1이 되어야 한다는 것을 의미한다. 조건부 확률을 제외하고 간단히 이 특징을 살펴보면, 이는 확률론과 통계학의 기본적이면서도 중요한 원리 중 하나임을 알 수 있다.
$P(z)$는 위의 정의에 의해 $P(f_{dec}^{-1})$로 다시 작성할 수 있고, 전개하면 아래와 같다.
변수 변환 정리를 통해 새로운 변수로의 변환 시 확률 밀도 함수에 일어나는 변화를 알 수 있다. 이 변화, 즉 밀도의 변화나 부피의 변화는 행렬의 결정자(determinant)를 사용해 계산할 수 있다. 예를 들어, 원래 공간에서 가로축이 2배, 세로축이 3배로 증가한 새로운 공간으로 변수 변환이 이루어졌다고 하자. 그렇다면 전체 부피는 6배 증가했다고 볼 수 있다. 이런 부피 변화를 행렬의 결정자를 통해 간단히 계산할 수 있다.
원래 우리의 식에 동일 개념을 그대로 적용하면 결정자(determinant)에 의해 변화되는 밀도는 아래와 같다. 곱셈의 경우, 계산한 결과가 매우 커질 수 있기에 양변에 $\log$ 를 취하여 나타낸다. *참고: 변수변환 정리
위 식에 텍스트에 대한 조건을 추가하여 조건부 확률을 만들고, 입력을 단일 값이 아닌 벡터로 바라볼 때, 논문에서 제시된 식 (1)과 같아진다. 이때, 벡터에 대해 미분을 하기 때문에 야코비 행렬이 생성된다. 이 과정은 변환된 변수의 확률 밀도 함수가 원본 변수의 확률 밀도 함수와 어떻게 관련되는지를 나타내며, 조건부 확률을 포함해 더 복잡한 입력 구조를 다루게 해준다.
결국 식(1)이 말하고 싶은 것은 “좀 더 쉬운 잠재변수 $z$로 변수를 변환하여 모델링했을 때, determinant의 절댓값만큼의 확률밀도 변화가 발생한다!” 라는 것이다.
Flow 기반 생성 모델의 원리를 어느 정도 파악했다면, 실제 모델을 사용하기 위해 파라미터화를 진행해야 한다. 식(1)에서 언급된 잠재 변수에 대한 모델링된 확률 밀도 함수는 사전 확률 분포(prior distribution)로 불리며, Flow 기반 생성 모델에서 이는 보통 가장 간단한 확률 분포인 정규 분포(다차원의 경우에는 등방성 다변수 가우시안 분포, isotropic multivariate Gaussian distribution)로 표현된다.
정규분포를 모델링할 때 그 형태는 분포의 평균과 분산(또는 표준편차)에 의해 결정된다. 텍스트의 길이에 맞추어 평균과 표준편차를 생성하고, 각 텍스트(음소)를 alignment와 함께 하나의 잠재 변수로 샘플링한다.
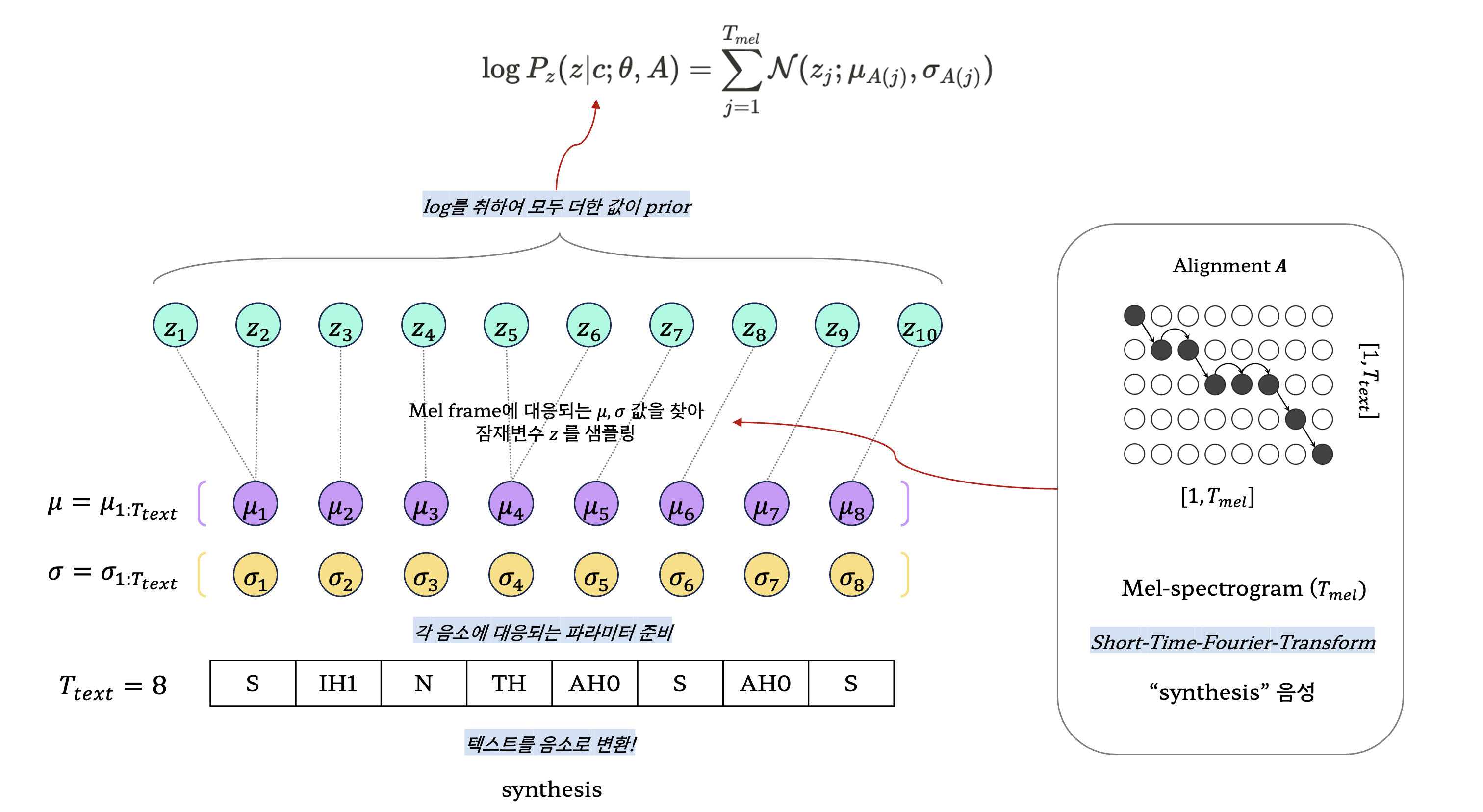
텍스트 “synthesis”가 주어졌고, 이에 해당하는 실제 음성인 “synthesis 음성”이 있다고 가정해보자. “synthesis”는 먼저 음소로 변환되고, 이 음소의 길이에 맞추어 평균과 표준편차가 임의로 설정된다. 논문에서는 모든 분산값이 1로 고정되어 있는 다변수 정규분포를 사용했다.
실제 음성은 STFT(Short-Time Fourier Transform)를 사용하여 멜-스펙트로그램으로 변환된다. 이 과정에서 각 멜-프레임마다 대응되는 음소(평균, 표준편차) 값을 구하기 위해 alignment 테이블 $A$가 사용된다. $A$를 활용하면 현재 멜 프레임이 어떤 음소와 대응되는지 쉽게 알 수 있다. 한 텍스트가 여러 멜 프레임과 대응될 수 있기 때문에, 결과적으로 추출된 잠재 변수의 개수가 더 많아지는 것을 확인할 수 있다.
마지막으로, 추출된 모든 값이 확률값이기 때문에 원칙적으로는 곱셈을 수행해야 하지만, 계산량을 줄이기 위해 로그를 취하고 덧셈으로 변환된다. 실제 음성 데이터를 사용할 수 없는 경우가 많기 때문에, 하나의 텍스트가 몇 개의 멜 프레임과 대응되는지 예측하는 duration predictor 모듈이 필요하며, 이는 모델에서 중요한 역할을 한다. 즉, prior의 값을 최대화할 수 있는 파라미터 $\theta$와 적절한 alignment $A$를 찾는 것이 핵심 과제다. Alignment를 찾는 과정이 꽤나 어렵기 때문에, 논문에서는 이를 2개의 세부 작업으로 나누어 접근한다.
- STEP 1. 현재 주어진 파라미터 $\theta$ 를 이용해 가장 유망한 alignment $A^*$ 찾기 (이후 MAS에서 설명!)
- STEP 2. 사후확률에 대한 로그 가능도를 최대화하는 $\theta$ 로 업데이트 하기
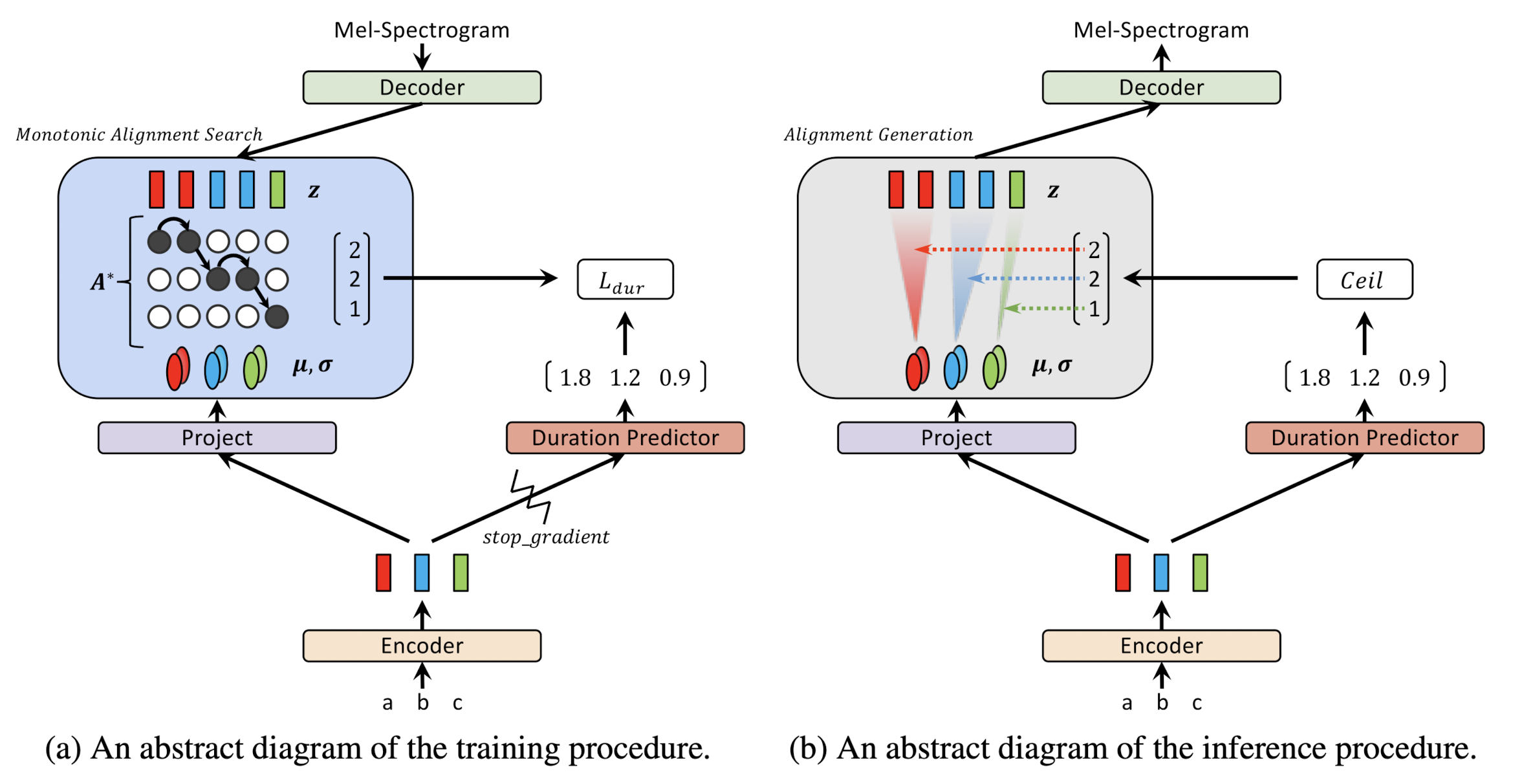
앞서 언급했듯이, 더 자연스러운 음성을 생성하기 위해 각 음소마다 얼마나 길게 발음해야 하는지 결정하는 duration predictor를 도입했다. 실제 정답 duration은 alignment 행렬을 통해 각 음소가 몇 개의 mel-frame과 대응되는지 확인함으로써 얻어진다(아래 식(5) 참조). 이 값을 정답으로 사용해 duration predictor의 학습을 진행한다. 손실 함수로는 MSE(Mean Squared Error)를 사용했다(아래 식(6) 참조). 이러한 접근 방법은 모델이 각 음소의 발음 길이를 더 정확하게 예측하도록 하여, 결과적으로 자연스러운 음성 합성을 가능하게 한다.
중요한 추가 사항으로, stop gradient라는 개념이 도입되었다. 이는 duration predictor로 계산한 손실을 줄이려는 과정에서, 그 영향이 인코더 쪽으로 전달되지 않도록 방지하는 역할을 한다. PyTorch에서는 이를 구현하기 위해 with torch.no_grad() 문을 사용하여, 해당 코드 블록 안에서의 연산들이 기울기 계산에 영향을 주지 않도록 할 수 있다. 이 방법은 모델의 특정 부분을 업데이트하면서 다른 부분에는 영향을 주지 않고자 할 때 유용하게 사용된다.
3.2. Monotonic Alignment Search
논문에서 다루는 주요 논점 중 하나인 alignment에 대한 설명은, 음소와 실제 음성 사이를 매핑하는 과정으로 간단하게 이해할 수 있다. 이 매핑 과정에서 alignment가 단조 증가하거나 감소하는 형태를 유지하는 것이 음성 합성의 결과를 매끄럽게 만드는 데 중요하다. 만약 매핑 과정에서 중단이 발생하면, 음성 합성 중에 잘못된 발음이 삽입될 위험이 있고, 이미 발음된 내용을 반복해서 발음하게 될 수도 있다. 따라서, monotonic한 결과를 얻는 것이 음성 합성의 품질을 높이는 데 중요한 요소이다.
저자는 이러한 monotonic한 결과를 얻기 위한 방법으로 동적 계획법(Dynamic Programming, DP)을 활용한 최적화 방법을 제시한다. 동적 계획법을 사용함으로써, 각 음소와 음성 사이의 최적의 매핑을 효율적으로 찾아낼 수 있으며, 이는 전체 음성 합성 과정에서 일관된 품질을 유지하는 데 도움을 준다.
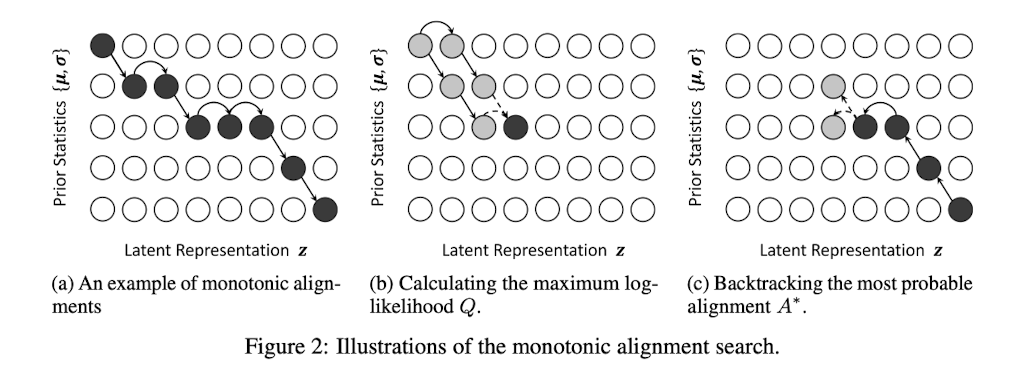
식(7)에서 $Q_{i, j}$는 i번째 사전 확률 분포와 j번째 잠재 변수 사이에서 계산될 수 있는 최대 로그 가능도 값을 의미한다. Alignment가 반드시 Monotonic해야 하기 때문에, 바로 이전 값이 될 수 있는 것은 왼쪽 위 혹은 바로 왼쪽 값 중 하나이다. 이러한 정보를 바탕으로 동적 계획법 알고리즘을 적용하여, 로그 가능도 값을 최대화하는 alignment를 찾는 것을 목표로 한다. 최대 로그 가능도를 구한 후에는 백트래킹을 수행하여 현재 로그 가능도가 어디서부터 계산되었는지 역추적한다.
해당 알고리즘의 시간 복잡도는 $\mathcal{O}(T_{text} \times T_{mel})$로, 주요 단점은 병렬화가 불가능하다는 점이다. 그러나 저자는 GPU 없이도 CPU만으로 충분히 빠른 계산이 가능하므로, 이 부분이 큰 문제가 되지 않는다고 언급한다. 이는 특히 리소스가 제한된 환경에서도 효과적인 음성 합성이 가능함을 의미한다.
3.3. Model Architecture
3.3.1. Decoder
디코더는 Glow-TTS 모델에서 매우 중요한 역할을 수행한다. 앞서 언급한 바와 같이, 디코더는 두 가지 주요 기능을 담당한다. 첫째, 훈련 과정에서 alignment 정보를 바탕으로 실제 멜 스펙트로그램에 해당하는 잠재 변수를 생성하는 역할이다. 둘째, 추론 과정에서 이 잠재 변수로부터 다시 멜 스펙트로그램을 재생성하는 역할이다. 이렇게 디코더는 두 종류의 Flow를 병렬적으로 수행하는 구조를 가지고 있다.
실제로 디코더 내부에서는 여러 레이어가 쌓여 있으며, 이 레이어들은 복잡한 데이터 변환 과정을 통해 최종적으로 고품질의 멜 스펙트로그램을 생성한다. 각 레이어는 특정한 변환 함수를 수행하며, 이 과정에서 데이터의 차원이 변하거나 특정 패턴이 강조되는 등의 작업이 이루어진다.
- [ Activation Normalization Layer + Invertible 1x1 Convolution Layer + Affine Coupling Layer ] x N
사실 위 구성 요소들 하나하나가 이해가 안돼 찾아보았더니, 생성모델에서 유명하신 Kingma 님 께서 발표하신 논문 중 하나인 Glow에서 등장한 내용이었다. 관련한 내용에 대해서는 이후 따로 리뷰를 진행해볼 예정이다.
- Kingma, D. P., & Dhariwal, P. (2018). Glow: Generative flow with invertible 1x1 convolutions. Advances in neural information processing systems, 31.
3.3.2. Encoder and Duration predictor
Encoder의 구조는 기존의 Transformer TTS 모델을 기반으로 하되, 두 가지 중요한 변화를 적용했다. 첫 번째 변화는 positional encoding을 사용하는 대신, self-attention 부분에서 relative positional encoding을 적용했다는 점이다. 이 변화는 입력 시퀀스의 위치 관계를 더 잘 반영할 수 있게 하여, 모델이 시퀀스 내에서 각 요소의 상대적 위치 정보를 더 정확하게 인식할 수 있게 한다. 특히, 입력 시퀀스의 길이가 긴 경우에 이 방식이 더 효과적일 것으로 추측할 수 있다.
두 번째 변화는 인코더 내에 존재하는 Prenet에 residual connection을 추가한 것이다. 이는 네트워크의 깊이가 깊어질 때 발생할 수 있는 학습 문제를 완화하고, 깊은 네트워크에서도 정보가 효과적으로 전달될 수 있도록 도와준다. Residual connection은 입력을 네트워크의 출력에 직접 더함으로써, 학습 과정에서 발생할 수 있는 gradient vanishing 또는 exploding 문제를 완화하는데 도움을 준다. 이러한 변화들은 Transformer 기반의 TTS 모델의 성능을 향상시키기 위해 도입되었으며, 더 정확한 위치 인코딩과 효율적인 정보 전달을 통해 음성 합성의 품질을 높이는데 기여한다.
하나의 음소가 몇 개의 멜프레임과 대응되는지 예측하는 duration predictor는 fastspeech 논문에서 발표된 것과 동일한 구조를 사용하였다. 구성은 Convolution + ReLU + Normalization + Dropout + Projection layer이다.
4. Experiments
실험에 사용된 데이터셋은 두 가지 종류로 나뉜다: 단일화자 데이터셋과 다중화자 데이터셋이다. 단일 화자 데이터셋으로는 LJSpeech가 사용되었는데, 이는 약 24시간 분량의 음성 데이터를 포함하고 있다. 다중화자 데이터셋은 247명의 발화자에 의해 녹음된 총 54시간 분량의 음성 데이터로 구성되어 있다. 데이터 전처리 과정에서는 음성 녹음의 마지막 부분에 존재할 수 있는 공백을 제거했고, 텍스트의 길이가 190을 초과하는 데이터는 학습 데이터셋에서 제외했다. 또한, 저자들은 학습 데이터셋의 조건과 다른 특별한 경우, 예를 들어 텍스트의 길이가 800을 넘어가는 데이터에 대한 실험도 진행했다.
- 비교군: Tacotron2
- 입력 토큰: 음소(Phoneme)
- 보코더 모델: 사전학습된 WaveGlow
- Optimizer: Adam
- Noam Learning Rate Scheduler
- 장비: NVIDIA V100 x2
5. Results
5.1. Audio Quality
평가지표는 역시 MOS 점수를 사용하였으며 평가는 아마존에서 제공하는 외주 서비스를 이용하였다. Glow-TTS 모델에서 추론을 진행할 때, prior distribution에 대한 표준편차를 설정할 수 있다고 하는데 사실 정확히 이해가 되지는 않는다. 표준편차의 값을 파라미터 $\theta$로 포함시켜 학습하였다고 이해했는데 별도로 설정한다는 부분이 잘 와닿지는 않는다(아래 설명 추가). 그러나 논문에 의하면 표준편차의 값을 0.333으로 고정하였을 때 음성합성의 결과가 가장 좋았다고 밝혔다. 가장 눈에 띄는 부분은 표준편차(Temperature)를 어떻게 설정하더라도 기존의 Tacotron2의 음성합성 결과보다는 뛰어나다는 점이다.

5.2. Sampling speed and Robustness
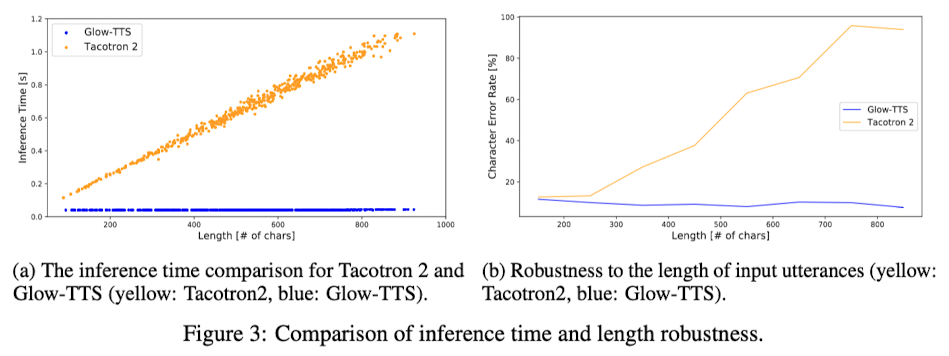
Glow-TTS 모델에 관해서 이야기해보면, 눈에 띄는 몇 가지 점이 있다. 첫 번째로, 텍스트의 길이가 길어져도 Glow-TTS가 음성을 합성하는 데 걸리는 시간은 대체로 40ms로 일정했다. 이는 텍스트의 길이에 관계없이 모델이 일관된 속도로 처리할 수 있다는 것을 의미한다. 이런 특징은 실시간으로 음성을 합성하는 상황에서 큰 장점이 된다. 반면, Tacotron2와 같은 모델은 텍스트가 길어질수록 처리 시간이 선형적으로 증가하는 경향을 보였다. 이는 긴 문장을 처리할 때 제약이 될 수 있다.
그 다음으로, 학습 데이터셋과 다른 분포를 가진 데이터에 대한 실험 결과도 주목할 만하다. 특히, 문장의 길이가 매우 긴 경우를 살펴보았을 때, Glow-TTS는 오류율이 계속 낮게 유지되는 반면, Tacotron2는 문장의 길이가 길어질수록 오류율이 높아지는 경향을 보였다. 이는 Glow-TTS가 다양한 길이의 문장에 대해 더 안정적이고 정확한 음성 합성 결과를 제공할 수 있음을 시사한다.
5.3. Diversity and Controllability
Glow-TTS는 flow 기반 생성 모델로, 우리는 이미 이 모델이 가우시안 분포에서 샘플링한 잠재 변수 $z$를 사용하여 모델링되는 방식을 살펴봤다. 실제 구현 시, 샘플링이라는 행위는 미분이 불가능하기 때문에, 구현 과정에서는 특정 평균값과 임의로 선택된 값 하나를 사용하여 샘플링을 구현하게 된다. 이때 샘플링한 값에 작은 변화를 주면, 음성 합성 결과에도 영향을 미칠 수 있다는 생각에서 이 아이디어가 나왔다. 예를 들어, 소리를 크게 하거나 특정 구간을 길게 만드는 등의 조절이 가능할 것이다.
여기서 사용된 변수 $T$가 표준편차를 의미하며 논문에서는 Temperature 라고 지칭한다. 그렇다면 과연 $\epsilon, T$ 값이 어떤 영향을 주는지 알기 위해 저자는 몇 가지 실험을 진행하였다.
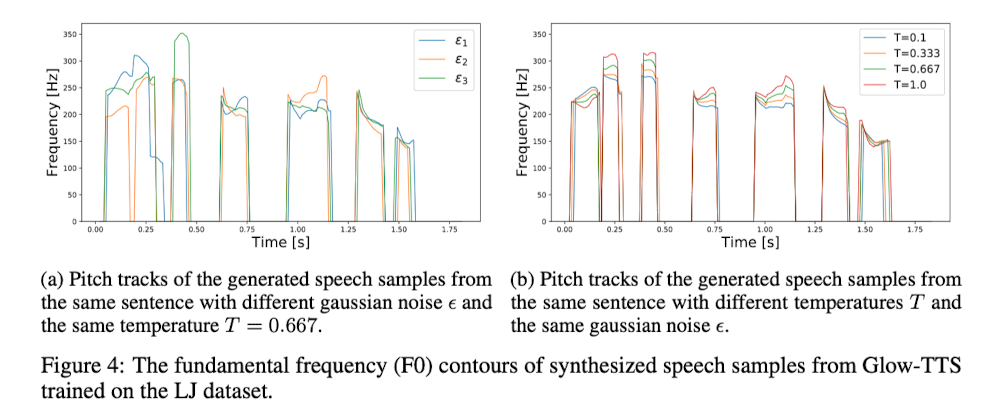
- Figure 4.a 를 보면 $\epsilon$ 조절을 통해 음성의 강도 또는 억양을 제어할 수 있음을 말한다.
- Figure 4.b 를 보면 $T$ 조절을 통해 억양은 유지한채로 음성의 높낮이를 제어할 수 있음을 말한다.
또한, 각 음소가 얼마나 길게 발음되는지 예측해주는 Duration predictor 모듈을 도입했다는 사실도 흥미롭다. 이 모듈이 예측한 값에 특정 상수를 곱함으로써 합성된 음성의 길이를 조절할 수 있다는 것을 알아냈다. 예를 들어, 원래 예측 결과에 0.5를 곱한다면, 결과적으로 2배 빠르게 합성된 음성을 얻을 수 있다. 이는 음성의 속도를 조절하거나, 특정 용도에 맞게 음성의 길이를 조정하는 데 유용하게 사용될 수 있다.
6. Conclusion
- 음성합성을 진행할 때, 별도의 외부 aligner 모델을 필요로 하던 기존 TTS 모델과는 달리 자체의 alignment 생성을 통해 효과적인 모델을 제안 (Tacotron2 와 비교하였을 때 약 15.7배 빠른 음성합성이 가능해짐)
- Alignment를 생성하는데 있어 동적계획법 알고리즘을 도입하여 계산하는데 드는 비용을 최소화
- Flow 기반 음성합성을 제안하였기에 약간의 변화를 주어 음성합성의 다양한 결과를 만들어내는데 성공
7. References
[1] Kim, J., Kim, S., Kong, J., & Yoon, S. (2020). Glow-tts: A generative flow for text-to-speech via monotonic alignment search. Advances in Neural Information Processing Systems, 33, 8067-8077.
[2] Ren, Y., Ruan, Y., Tan, X., Qin, T., Zhao, S., Zhao, Z., & Liu, T. Y. (2019). Fastspeech: Fast, robust and controllable text to speech. Advances in neural information processing systems, 32.
[3] yun_s, [Glow-TTS] Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search (NIPS 20) [작심삼일:티스토리] https://sofar-sogood.tistory.com/entry/Glow-TTS-Glow-TTS-A-Generative-Flow-for-Text-to-Speech-via-Monotonic-Alignment-Search-NIPS-20
[4] minjoon, [논문리뷰] Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search (NeurIPS20) [음악과 오디오,인공지능:티스토리] https://music-audio-ai.tistory.com/35