Knowledge Graph for Recommender System
A Survey on Knowledge Graph-Based Recommender Systems
- IEEE Transactions on Knowledge and Data Engineering 2022
- Qingyu Guo, Fuzhen Zhuang, Chuan Qin, Hengshu Zhu, Xing Xie, Hui Xiong, Qing He
최근 많은 프로젝트를 진행하면서, 흥미가 가는 2가지 관심분야가 생기게 되었다. 그 중 하나가 추천시스템으로서, 더 세부적으로는 knowledge graph를 사용한 추천시스템이다. 나도 잘 모르는 나의 선호도를 수치화 또는 추적할 수 있고, 이를 바탕으로 나에게 맞는 컨텐츠를 제공해줄 수 있다는 점에서 크게 매력적으로 와닿았다. 다른 하나는 음성합성으로 흔히 TTS 또는 speech synthesis라고도 부른다. 이번에 교내 그리고 대외활동으로 프로젝트를 진행하다보니, 결과가 수치적인 결과 뿐만 아니라 들을 수 있는 파일로 생성된다는게 매력적이었다. 이미 많은 발전이 되어 있지만, 단순 음성합성을 넘어선 새로운 시도를 해보고 싶어 더 큰 흥미가 생기게 되었다.
둘 다 너무 다른 분야라고 생각되어, 하나를 정하기 위해 각 분야에 대한 survey 논문을 읽어보기로 하였고, 이는 그 중 첫 번째인 Knowledge grpah를 사용한 추천시스템에 대한 서베이 논문이다.
추천시스템에서는 단지 유저 행동 데이터로는 수집하기 힘든 정보들을 knowledge graph (KG)를 사용하여 보충하는 방법론을 적용하였다. KG를 사용하면, 고차원 관계를 파악할 수 있는데 여기서 말하는 고차원 관계는 여러 정점(object)를 거쳐 연결되는 관계를 말한다. 이미 연구가 이루어진 GNN(Graph Neural Network)와 더불어 KG를 사용하면 효과적으로 두 객체의 특징이나 관계를 파악할 수 있게 된다.
GNN 자체로도 그래프 구조 위에 존재하는 두 객체사이의 관계를 파악할 수 있지만, knowledge graph위에서 그대로 이 개념을 적용하게 되면 더 풍부한 정보를 사용할 수 있어 더욱 세밀한 추천 또는 정보 추출이 가능하다는 것을 말한다.
1. Introduction
전통적인 추천시스템에는 2가지 아키텍처가 있다. 각각 컨텐츠 기반 추천 그리고 협업필터링 기반 아키텍처이다. 컨텐츠 기반 추천 시스템은 데이터를 벡터(임베딩)으로 표현하여 유사도를 계산하는 방법을 말한다. 다시 말해, 어떤 아이템을 유클리드 공간에 표현할 수 있어야 함을 말한다. 하지만, 실제로 모든 데이터를 유클리드 공간상에 벡터화하여 표현하는 것은 쉬운일이 아니고, 그런 데이터들은 knowledge graph 형식으로 표현되어 있다.
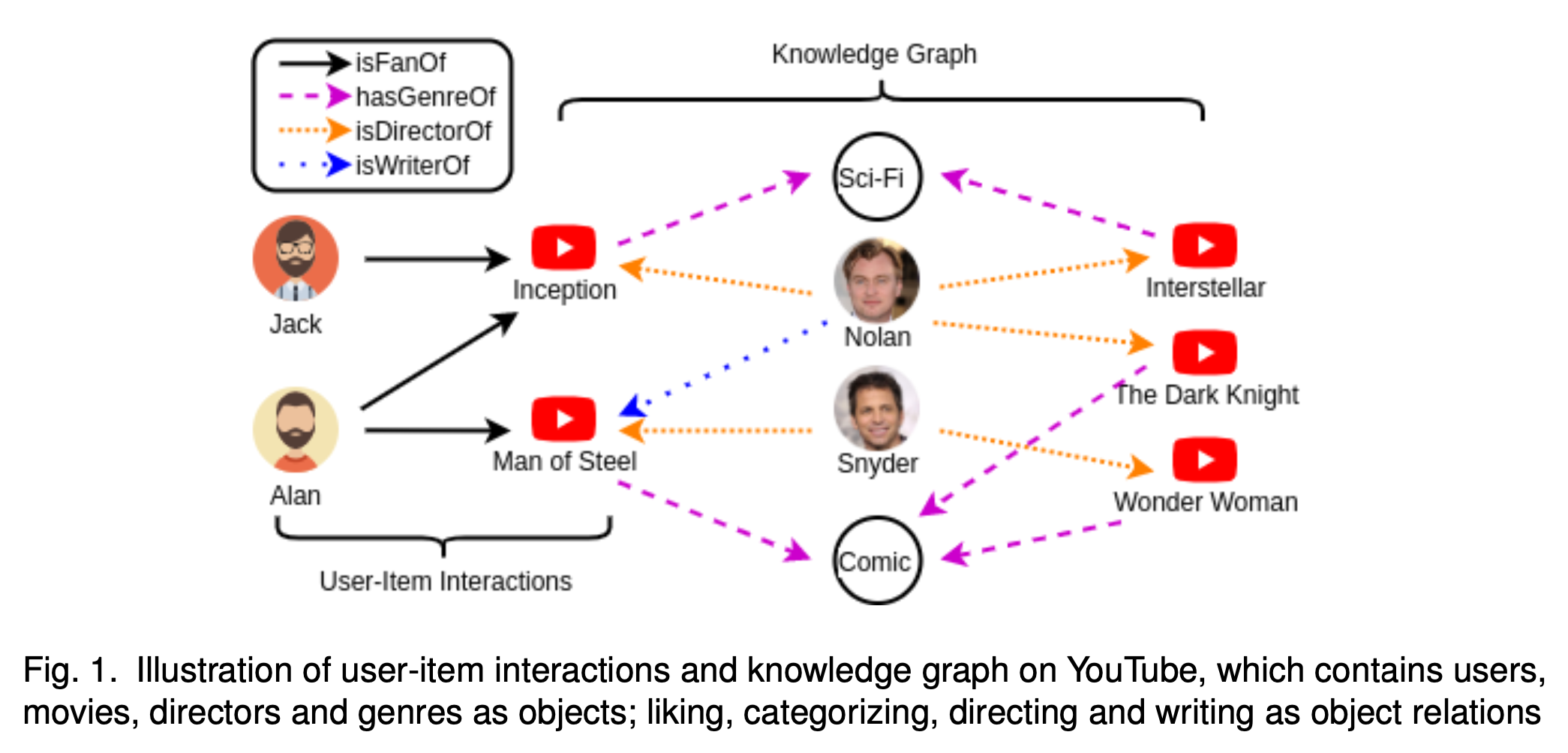
Knowledge graph는 서로 독립적인 object를 어떠한 관계(relation, attribute)로 엮어서 표현하는 것을 말한다. 위 그림은 논문에서 사용된 knowledge graph를 말하며, 유튜브 추천에서 사용될 수 있는 그래프이다. 여기서 눈여겨 볼 수 있는 점은 각 object 마다 서로 다른 수의 이웃 object를 가질 수 있고, 이는 관계의 개수도 어떤 객체인지에 따라 달라질 수 있다.
1.1 Contributions
새로운 분류체계 확립
GNN은 2가지 기본 요소인 aggregator와 updater로 구성되어 있다. 말 그대로 aggregator는 이웃 노드로 부터 전달된 정보를 결합하는 역할이고, updater는 현재 노드에서 이웃 노드로 정보를 전파시키는 역할이다. 이를 세부적으로 논문에서는 다음과 같이 분류 한다.
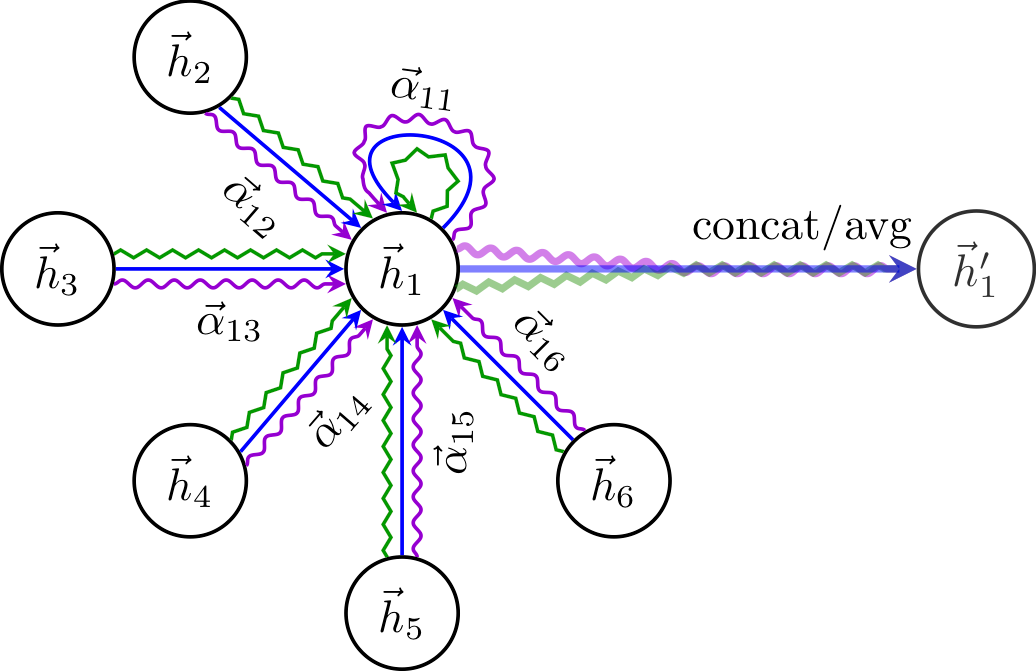
Aggregator
- relation unaware aggregator
- relation aware subgraph aggregator
- relation aware attentive aggregator
Updater
- context only updater
- single interaction updater
- multi interaction updater
GNN-based Knowledge Aware Deep Recommender (GNN-KADR) 설명
GNN-KADR 시스템의 비교를 위해 사용된 평가 데이터셋, 평가지표 요약
미래 연구 방향성 제시
논문은 현재 존재하는 그래프 기반 추천시스템의 한계와 앞으로 해결해야 하는 과제들은 무엇이 있는지를 설명한다. (다양성, 해석가능성, 공정(평)한 추천이 되었는지)
2. Preliminary and notation
Knowledge graph는 유저가 발생시키는 모든 데이터들을 그래프로 나타낼 수 있다는 점에서 가용성이 좋다. 예를 들어, 누군가가 물건을 구매하기 위해 검색한 내역, 실제 구매 내역, 그리고 같이 조회한 상품이나 어디서 구매했는지의 정보들을 모두 그래프 위에서 나타낼 수 있다. 단순히 추천시스템에서 사용하던 장바구니 분석 이외에 다양한 정보들을 그래프 구조를 통해 한 번에 관리할 수 있다는 점이 강력한 장점으로 보여진다.
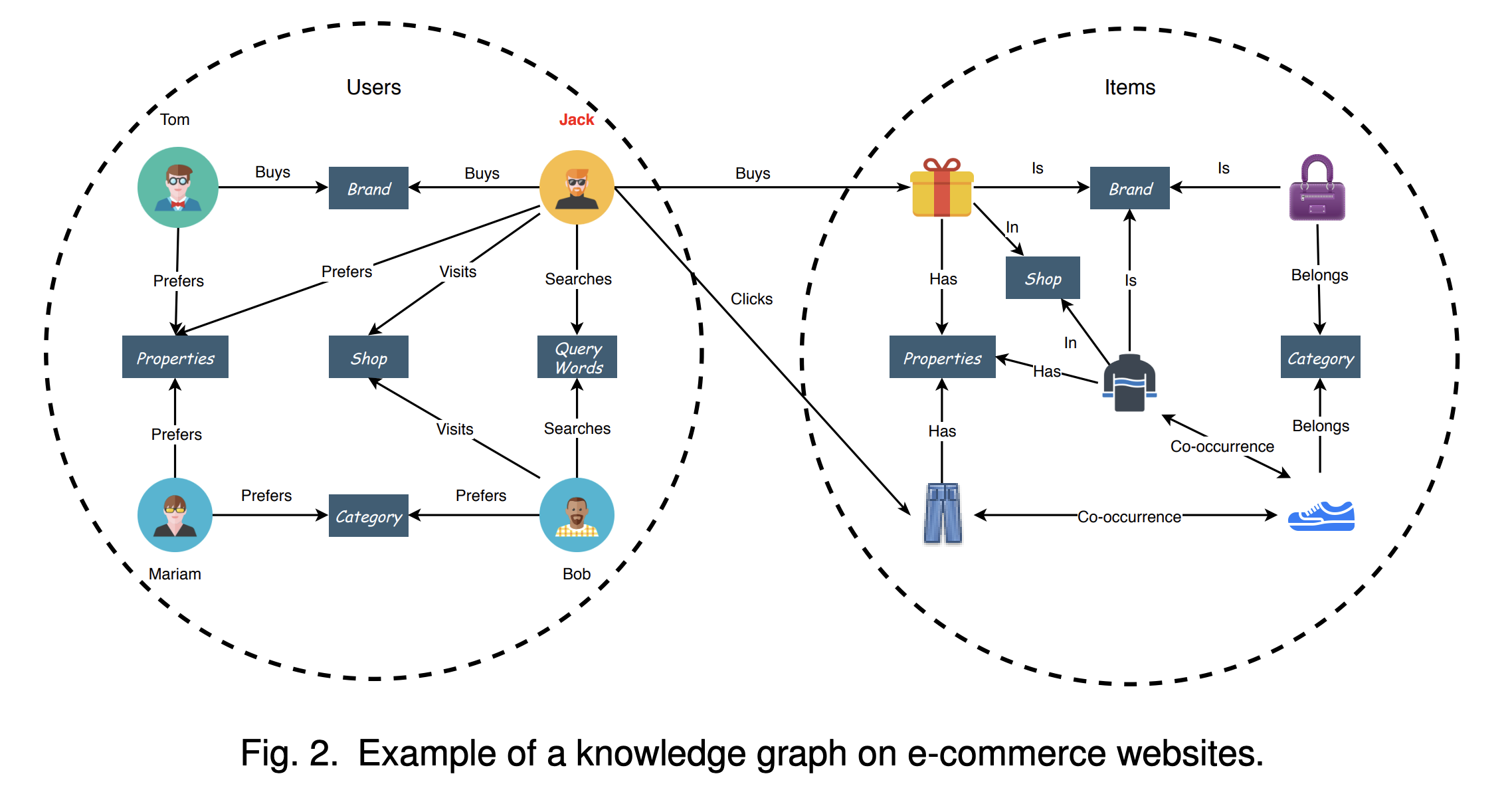
2.1. Knowledge Graph
Knowledge graph는 방향성 있는 그래프로서, 다른 그래프의 표현과 마찬가지로 $\mathcal{G} = (\mathcal{V}, \mathcal{E})$ 의 형태로 정의된다. 여기서 말하는 $\mathcal{V}$ 는 Vertex인 정점을 말하며 $\mathcal{E}$는 Edge로서 간선들의 집합을 말한다. (그래프는 정점들과 간선들의 집합으로 표현됨을 의미) 하나 중요한 개념으로는 지식그래프를 표현하는 방법이 있다. 흔히 지식그래프를 말할 때, entity-relation-entity 구조를 띈다고 말한다. Entity는 쉽게 말해 정점을, relation은 간선에 대응된다. 이 구조를 triplet 구조라고 하며 해당 논문에서는 knowledge triplets 라고 정의한다.
knowledge graph에는 타입 매핑 함수 $\phi$, $\psi$가 존재한다. 위 그림에서 보여지는 것처럼 KG에는 정점이더라도 그 종류가 사람이 될 수도 있고, 아이템이 될 수도 있으며 또 다른 종류가 될 수 있다. 이때, 정점 타입 매핑 함수를 사용해 $\phi(\mathcal{v})$ 그 타입을 알 수 있으며 정점 타입의 집합은 $\mathcal{A}$로 나타낸다. 마찬가지로 간선에 대해서도 동일한 개념을 적용할 수 있으며 기호로 $\psi(\mathcal{e}) \in \mathcal{R}$ 로 나타낸다.
2.2. Neighborhood
이웃 정점집합 $N(\mathcal{v})$ 는 현재 정점 $\mathcal{v}$ 와 직접적으로 연결된 다른 모든 정점들의 집합을 말한다. 연결된 relation의 type이나 entity의 type을 고려하지 않고 직접적으로 연결된 정점들은 모두 이웃에 해당된다.
2.3. r-Neighborhood
이웃 정점집합들 중, relation type $r$에 의해 연결된 이웃 정점들만 묶어 $N_r(\mathcal{v})$로 표현한다. 바로 위에서 설명한 수식과 함께 표현하면 아래와 같다.
\[\{ w | (w, e, u) \; or \; (u, e, w), \quad where \; e \in \mathcal{E} \; and \; \psi(e)=r \}.\]2.4. User-Item recommendation
모든 정점들의 집합을 표현하는 $\mathcal{V}$는 사실 $\mathcal{V}_1 \cap \mathcal{V}_2 \cap \cdots \mathcal{V}_n$ 으로 풀어서 작성할 수 있다. $\mathcal{V}_i$는 정점의 type이 $i$인 것들의 집합이며 당연히 $n$은 전체 정점의 type의 수가 된다 ( $ n= \vert \mathcal{A} \vert $). 또한, 추천 task에서는 $\mathcal{V}_1$을 유저 노드로, $\mathcal{V}_2$를 아이템 노드로 정의한다.
마찬가지로 간선에 대해서도 분해하여 표현할 수 있다. 분해하면 $\mathcal{E} = \mathcal{E}_{label} \cap \mathcal{E}_{unlabel}$로 나타내어 지며 $\mathcal{E}_{label}$은 유저노드와 아이템노드 사이에 만들어진 간선들만을 지칭한다. 추천시스템은 유저 개인의 선호도를 고려하여 아이템을 추천해야하기 때문에 지식 그래프는 각 유저마다 생성되며 이는 $\mathcal{G}^P = (\mathcal{V}^P, \mathcal{E}^P)$로 작성한다. 이렇게 되면 지식 그래프위의 추천시스템은 어떠한 아이템 노드와 유저 노드 사이에 존재할 간선($\widehat{\mathcal{E}}_{label}^P$)의 생성 여부를 예측하는 문제가 된다.
3. Categorization and Frameworks
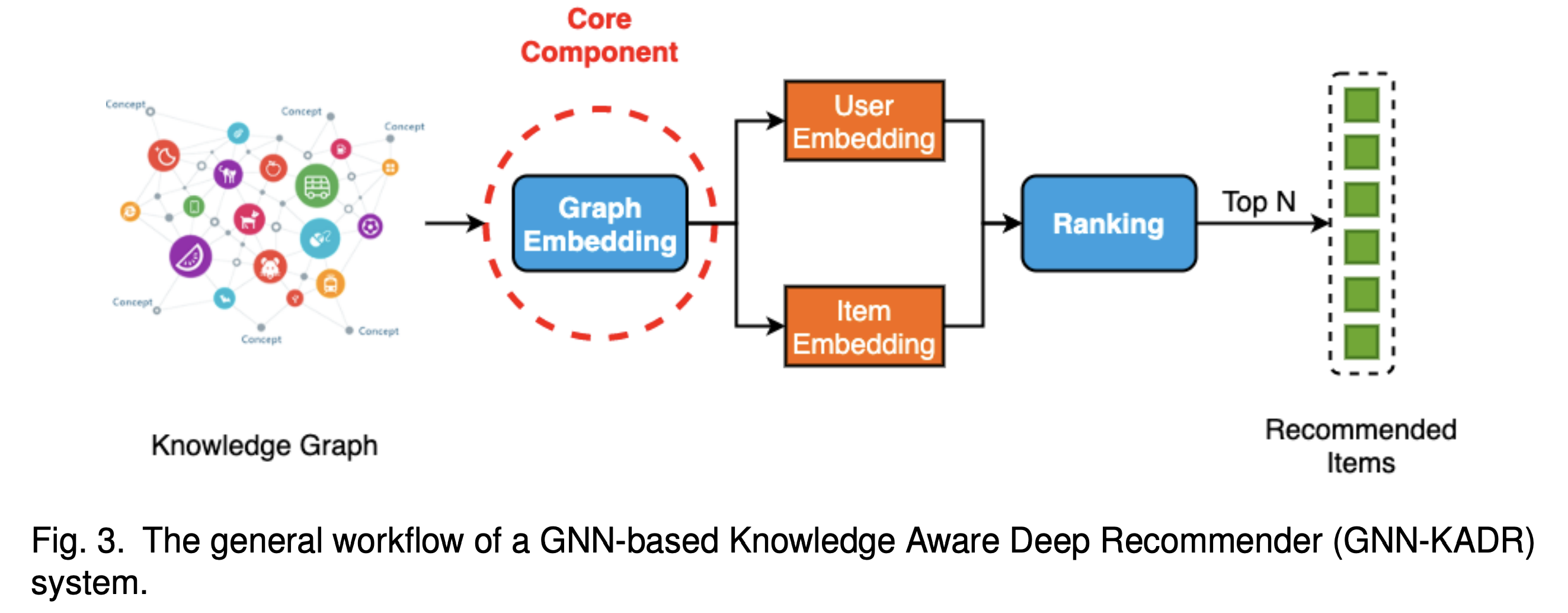
해당 그림은 GNN을 활용한 추천 시스템, GNN-KADR의 구조를 잘 보여준다. GNN-KADR은 처음에 그래프로 표현된 정점들을 수치화하기 위해 임베딩 과정을 거친다. 이 임베딩 과정은 주로 GNN을 통해 진행되며, 이때 knowledge graph에서 얻은 정보를 충분히 반영한 임베딩을 생성하는 것이 중요하다. 다음 단계에서는 유저의 임베딩과 아이템의 임베딩을 추출하고, 이들을 바탕으로 특정 랭킹 알고리즘을 적용하여 유저와 후보 아이템들 간의 매칭을 수행한다.
여기서 핵심은 노드들을 벡터로 변환하는 임베딩 과정이다. GNN은 기본적으로 주변 이웃 노드들의 정보를 수집하여 결합하는 aggregator와, 새로운 정보를 주변 이웃 노드에게 전달하는 updater로 구성되어 있다. 한 번의 연산으로는 바로 인접한 이웃 노드의 정보만 활용할 수 있지만, 여러 번 GNN 레이어를 쌓음으로써, $k$-hop 거리에 있는 이웃의 정보도 획득하여 결합할 수 있다. 또한, 주변 이웃 노드를 인지할 수 있는 범위를 GNN의 수용 필드(receptive field)라고 부른다.
3.1. Aggregator
3.1.1. Relation-unaware agg.
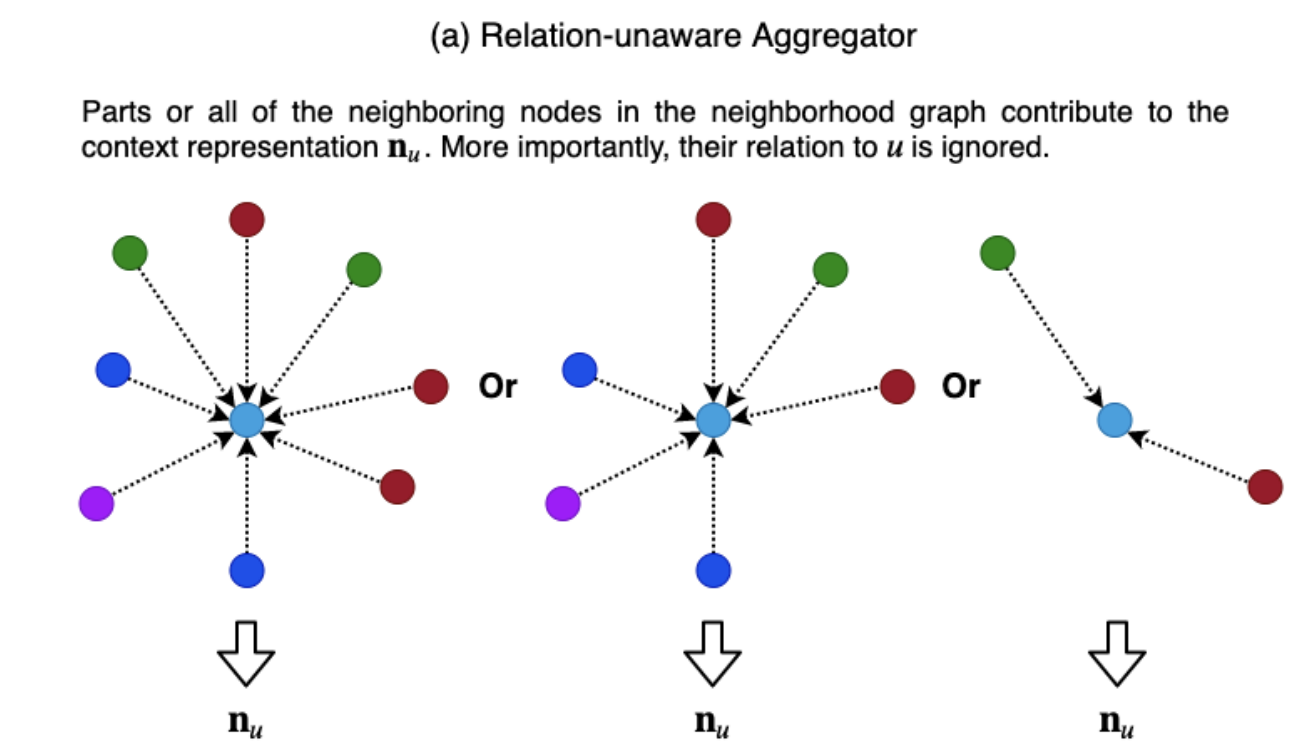
말그대로 relation을 고려하지 않는 aggregator로서, 주변 이웃들과 연결되어 있으면, 해당 이웃들의 정보들을 가져오는 방식이다. Relation의 타입을 전혀 고려하지 않고 주변 노드의 정보들을 모두 가져오거나 일부를 가져와 결합한다.
(1) MEIRec
주변의 이웃들의 정보를 가져와서 결합하되, 그 방식을 target 노드(entity)의 타입에 따라 바뀔 수 있도록 설정한 방법이다.
\[\mathbf{n}_u = g(\{ \mathbf{z}_\mathcal{v} \vert \mathcal{v} \in N(u)\})\]- $\mathbf{n}_u$ : 노드 $u$의 임베딩
- $\mathbf{z}_\mathcal{v}$ : 이웃노드의 임베딩
- $g(\cdot)$ : aggregation function (average / LSTM)
$\phi(u)$가 아이템 노드인 경우, 이웃 노드들의 type은 유저 노드이다. 아이템 노드를 소비한 유저들의 목록들이 있을 때, 그 순서는 중요하지 않기 때문에 순서정보는 고려하지 않는다. 따라서 MEIRec에서는 아이템 노드에 대해서는 average pooling을 적용하였다.
반면 $\phi(u)$가 유저 노드인 경우, 이웃 노드들의 type은 아이템 노드이다. 유저가 어떤 아이템들을 소비했을 때, 그 순서는 현재의 선호도를 모델링하는데 중요한 정보이기 때문에 순서정보를 고려할 수 있는 aggregation 함수를 사용한다. MEIRec에서는 LSTM을 사용해 순서정보까지 모델링하였다.
(2) PinSage
Pinterest에서 개발하고 배포한 알고리즘인 PinSage는 knowledge graph 위에서 random walk와 GNN을 결합하여 추천을 수행하는 모델이다. PinSage는 가장 먼저 시작점에서 random walk를 수행하여 주변 이웃 노드들을 방문한다. 이 과정에서 자주 방문된 노드는 중요도가 높다는 것을 의미한다. MEIRec과 유사하게 PinSage도 이웃 노드의 정보를 활용하지만, 여기에 더해 중요도 정보를 추가적으로 사용한다는 점에서 차별화된다.
\[\mathbf{n}_u = Avg/Pool(\{ReLU(\mathbf{W}_1\mathbf{z}_u + \mathbf{b}) \vert v \in N(u)\}, \{ \alpha_v \})\]- $\alpha_v$ : $u$의 이웃 노드들의 방문횟수에 대해 $L_1$ 정규화된 값
MEIRec과 다른 점으로 affine transformation이 포함되어 있다는 점을 꼽을 수 있는데 이는 주변 이웃 임베딩의 표현력을 한단계 상승시켜주기 위한 것으로 보여진다.
3.1.2. Relation-aware subgraph agg.
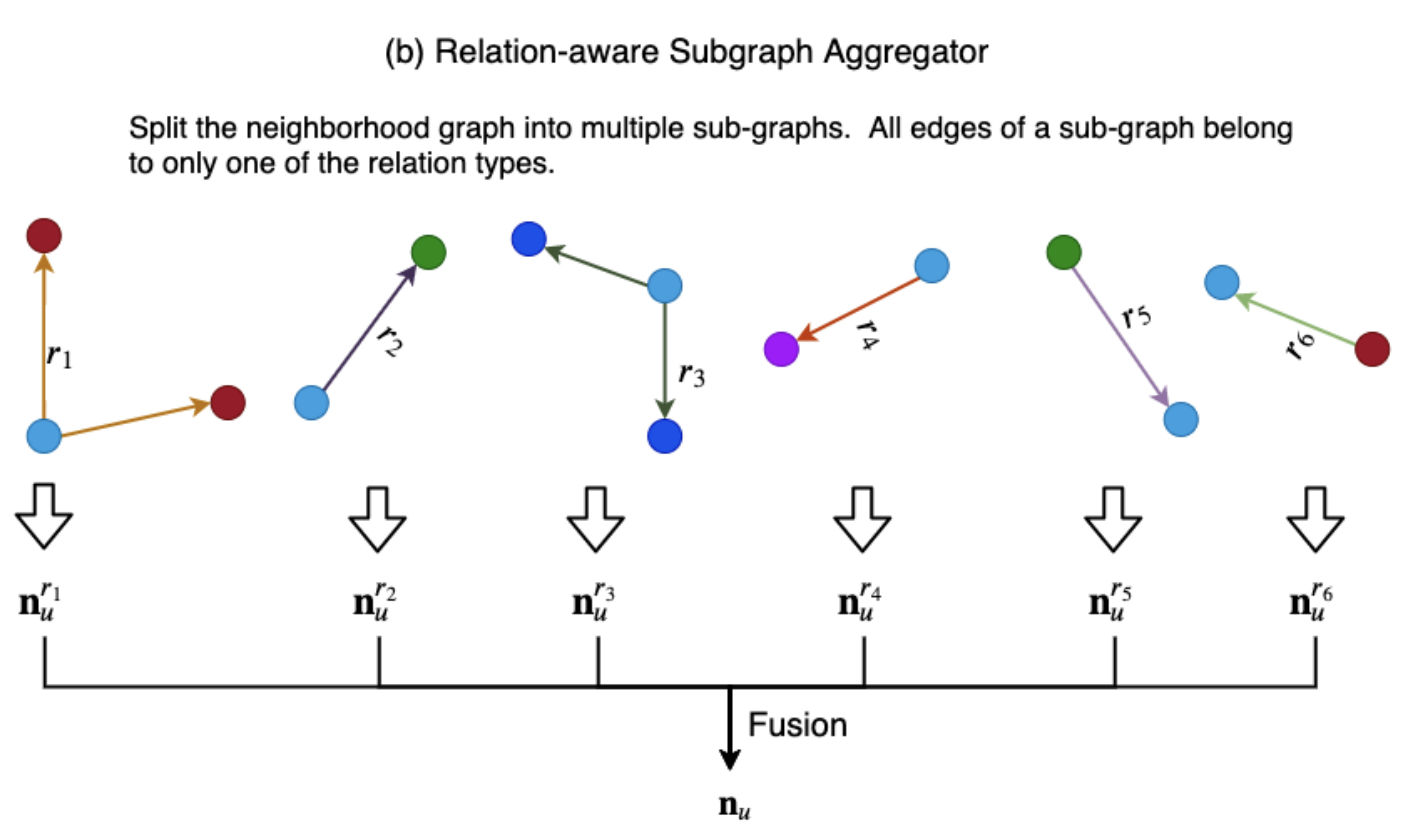
주변 이웃들의 정보를 가져와서 결합하되, 먼저 knowledge graph위에서 이웃들을 relation의 type에 의해 group by하 한다. 각 relation type에서 생성된 임베딩들을 결합하여 최종 임베딩을 생성하는 방법론을 말한다.
(1) RecoGCN
RecoGCN은 knowledge graph 위에 존재하는 다양한 정보를 활용하여 임베딩을 생성할 수 있는 새로운 방법론을 제시하는 모델이다. 이전 모델들과는 달리, RecoGCN은 먼저 relation의 특징별로 정보를 묶은 후 최종 임베딩을 생성한다는 점에서 뚜렷한 차이를 보인다.
- $\mathbf{z}_u$ : 노드$u$의 feature vector
RecoGCN 설명을 읽으면서, $\alpha_{v, u}^r$은 relation type $r$에 대해서 target node $u$와 갖는 중요도를 나타내는 것으로 해석되었다. 각 relation type에 대한 가중치의 합이 1.0이 되는 것은 softmax 함수를 사용함으로써 자연스러운 결과이다. 하지만, 마지막에 각 relation type별 임베딩을 합칠 때 문제가 발생할 수 있다는 생각이 들었다. 특히, 어떤 노드가 다른 노드들에 비해 현저히 많은 relation type과 연결되어 있다면, 해당 노드의 임베딩 원소값들은 커질 수 있기 때문이다.
(2) STAR-GCN
STAR-GCN은 추천 시스템의 성능을 향상시키기 위해 제안된 알고리즘이며, 그래프 convolution 인코더를 도입하였다. 위에서 언급한 RecoGCN과 유사하지만, STAR-GCN은 target 노드와 이웃 노드를 연결하는 간선의 수로 나누는 점에서 차이를 보인다.
(3) IntentGC
IntentGC는 유저의 명시적 선호도와 knowledge graph 위에 존재하는 추가 정보를 포착하여 추천에 활용할 수 있는 알고리즘을 제안한다. Survey 논문에서 제시된 수식과 설명만으로는 모든 내용을 완전히 이해하기 어려웠지만, 다른 알고리즘과 유사하게 relation 별 subgraph의 임베딩을 조합하는 방식을 채택하고 있었다.
IntentGC는 왜 모든 이웃의 정보들을 고려하지 않고 전체 relation의 개수인 $\vert R \vert -2$ 개의 relation type만 고려할까?
이러한 방식으로 subgraph의 결과를 합하는 방법을 채택함으로써, 논문에서는 계산의 효율성 측면에서 이점을 얻을 수 있다고 밝힌다. 실제로 조금만 고민해보면, 작은 규모의 행렬곱셈의 결과를 더하는 것은 큰 두 개의 행렬을 곱하는 것으로도 표현할 수 있으며, 이는 작은 규모의 행렬곱셈의 덧셈으로 접근하는 것이 훨씬 효율적임을 의미한다. $\Rightarrow \mathbf{W} \cdot (\mathbf{n}_u^{r_1} \Vert \mathbf{n}_u^{r_2} \Vert \dots)$
3.1.3. Relation-aware attentive agg.
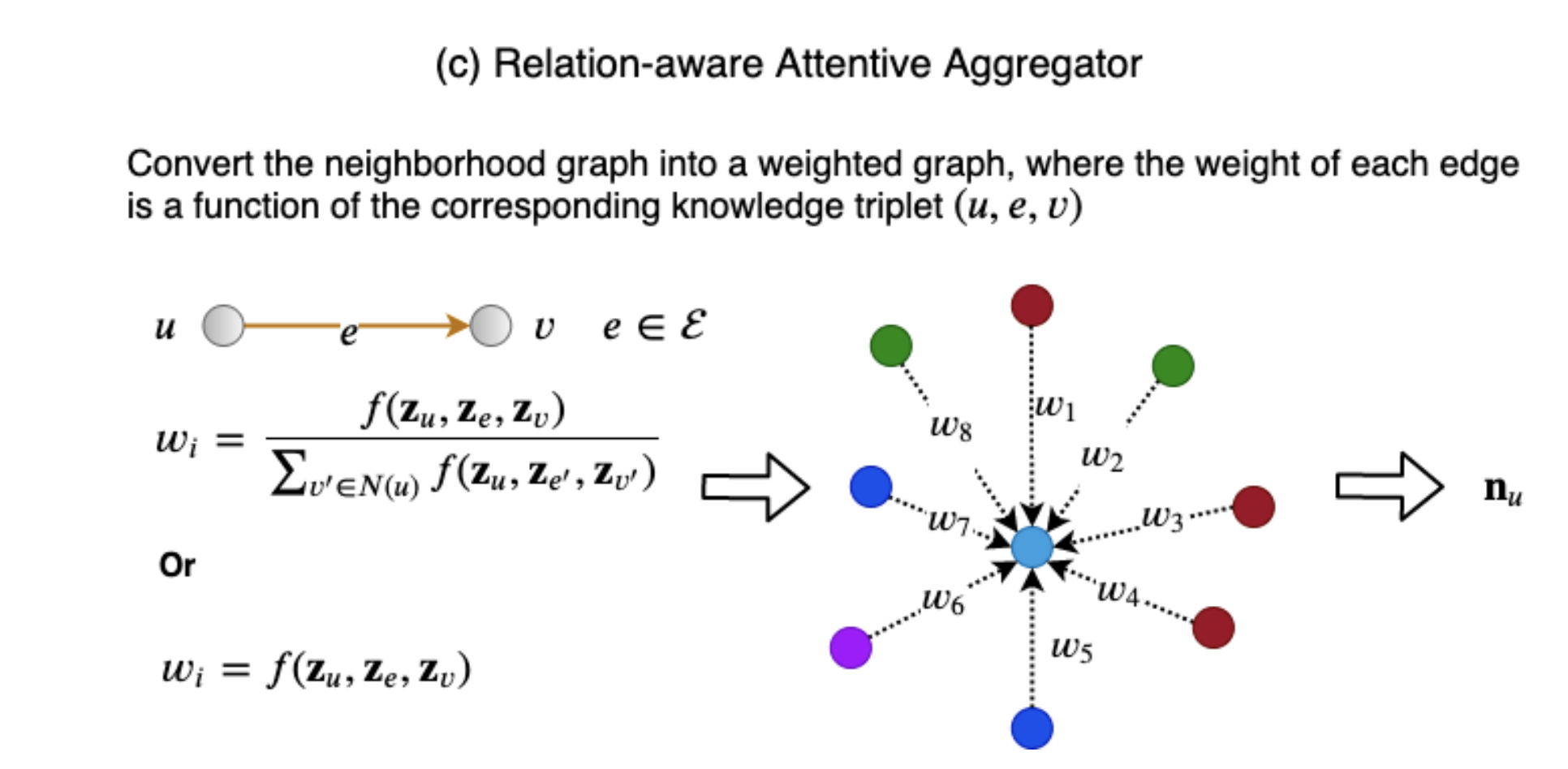
주변 이웃 노드로부터 전달된 정보를 통합하는 이 방법은, relation의 정보뿐만 아니라 주변 이웃 노드 자체의 정보를 활용하여 가중치를 부여한다. 이 가중치를 통해 이웃으로부터 전달되는 정보의 양을 조절할 수 있으며, knowledge graph 내에 존재하는 의미론적 요소들을 충분히 반영할 수 있다는 특징을 가진다.
(1) KGNN-LS
KGNN-LS는 knowledge graph 내에 존재하는 다양한 관계의 중요도를 계산하기 위해 학습 가능한 함수를 설정한다. 간단히 말해, 이 함수는 유저가 특정 속성을 선호할지를 판단하는 역할을 한다. 이 함수를 통해 얻은 정보와 라플라시안 행렬을 사용하여, 노드의 임베딩을 새롭게 업데이트할 수 있다.
- $\mathbf{A}_{i, j} = f(\mathbf{z}_{e_{i, j}})$ : entity $i$와 $j$사이의 관련도 점수
- $\mathbf{N}$ : 관련도 점수에 대해 정규화를 한 라플라시안 행렬을 생성하고, 이전에 전파된 정보인 $\mathbf{X}$와 결합한 새로운 결과
(2) GraphRec
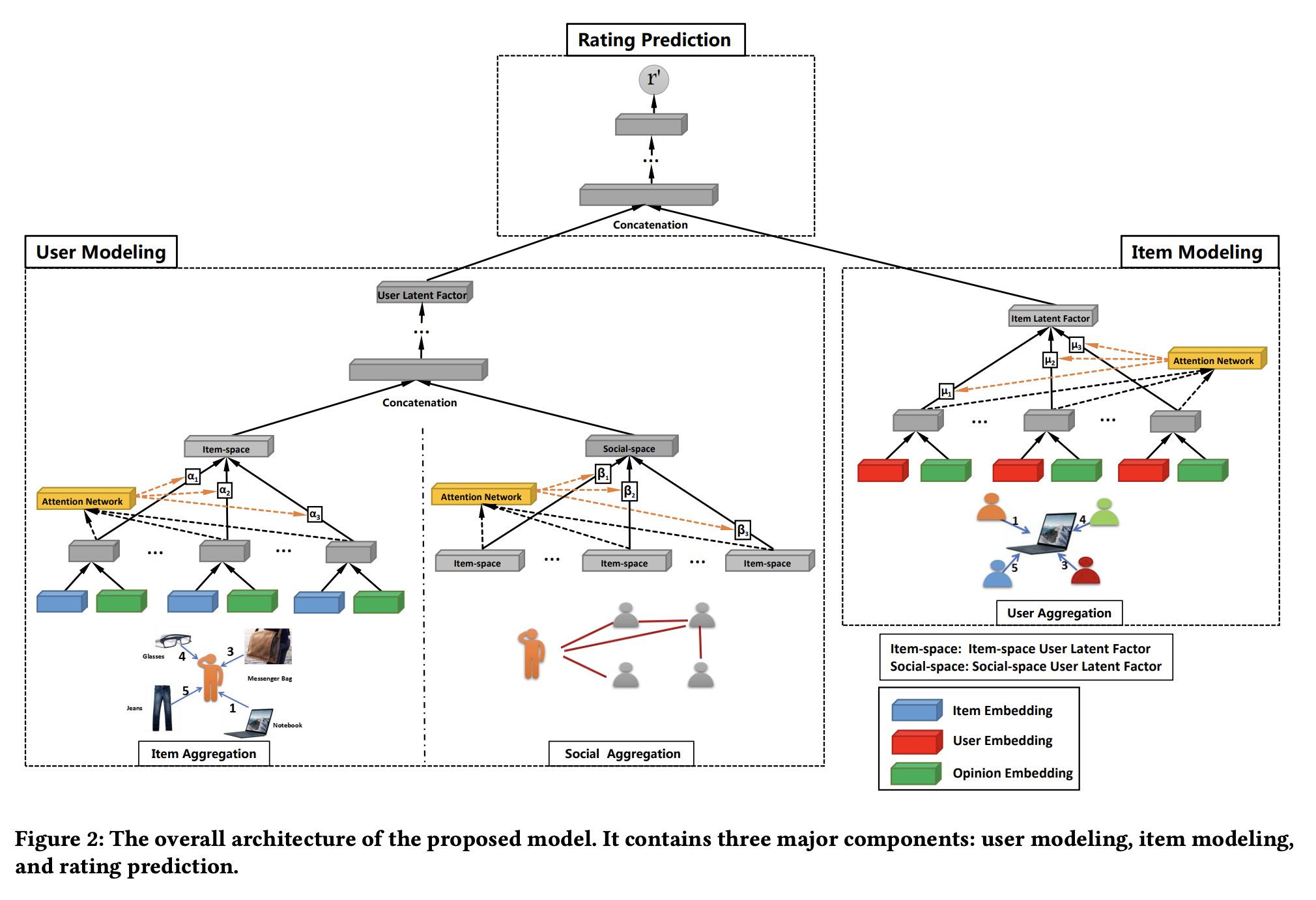
GraphRec은 knowledge graph 내에 존재하는 두 종류의 연결 관계를 추천 문제에 적용하려는 모델이다. 소셜 네트워크 그래프에서는 유저 간의 연결과 유저와 아이템 간의 연결, 두 종류의 관계가 존재한다. GraphRec은 이 두 가지 관계를 모두 모델링하기 위해 세 가지 aggregator를 사용한다: user aggregator, item aggregator, social aggregator. 세 종류의 aggregator가 있음에도 불구하고, 계산 방식은 동일하기 때문에 서베이 논문에서는 item aggregator에 대해 설명한다.
수식 설명에 따르면, 첫 번째 단계에서는 아이템 특징 벡터와 relation 특징 벡터를 결합(concatenate)하여 MLP(다층 퍼셉트론)에 입력한다. 이 과정은 relation과 아이템 사이에 존재하는 관계를 포착하는 단계로 해석할 수 있다. 두 번째 단계에서는 아이템과 relation 사이의 관계를 파악한 결과에 유저 특징 벡터를 결합하여, 두 번의 선형 변환을 수행한다. 이어지는 단계에서는 attention weight(점수)를 계산하게 되며, 이 가중치를 통해 주변 이웃의 정보를 적절한 비율로 가져오게 된다.
(3) KGAT
KGCN이 KG의 고차원적 연결 관계, 구조 정보, 그리고 의미론적 정보를 자동으로 추출할 수 있는 모델을 발표한 것과 유사하게, KGAT는 유저 entity, 아이템 entity, relation의 세 가지 요소를 relation 벡터 공간에서 attention score로 계산한다. 이 각각의 score는 가중치로 활용되어 주변 이웃 정보를 얼마나 반영할지 결정하는 역할을 한다.
- $\mathbf{W}_e$ : entity를 relation(edge) 벡터공간으로 선형 변환하는 행렬
여기서 주목할 점은, 두 종류의 entity들과 relation을 계산할 때 모두 relation 공간 위에서 계산을 수행했다는 것이다. 이외의 점들에 대해서는 다른 relation aware attentive aggregator와 유사하다.
3.2. Updator
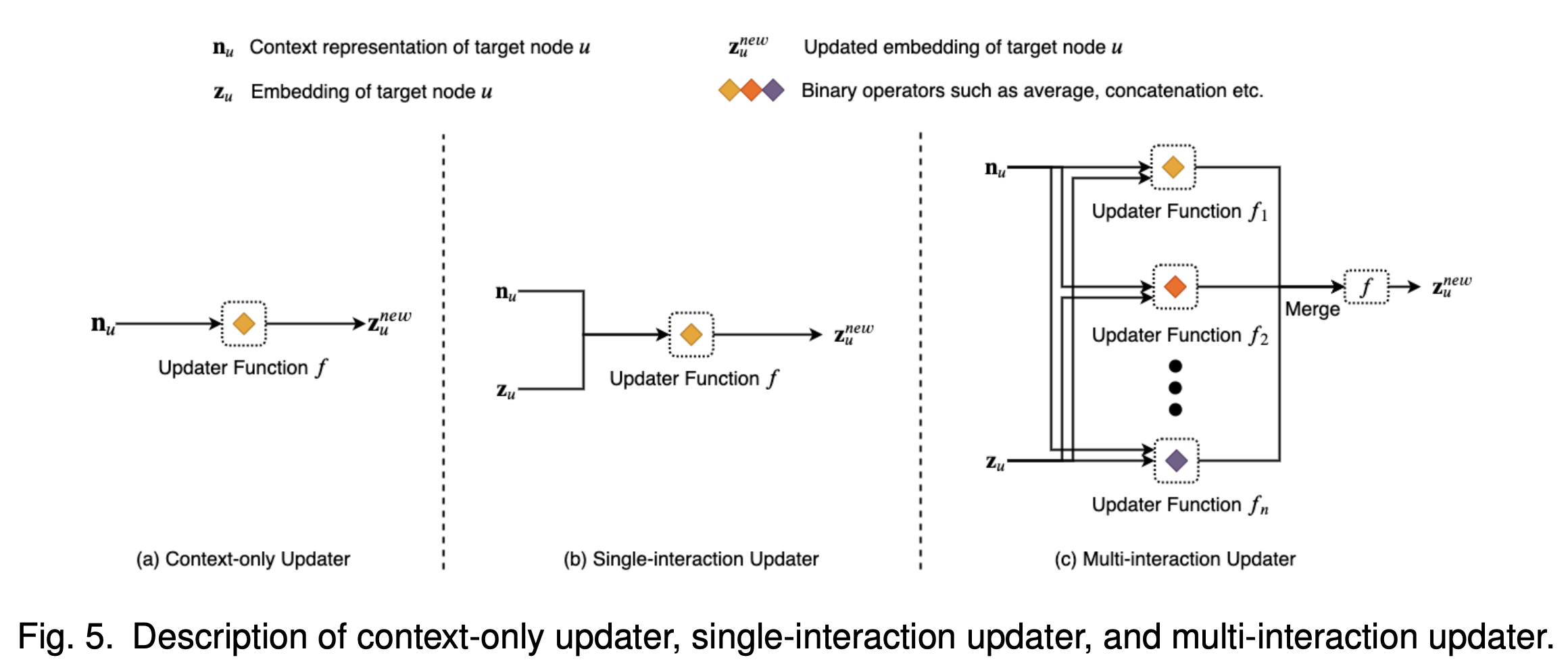
Aggregator에서는 현재 노드 주변의 정보들을 결합하여 새로운 context 벡터 $\mathbf{n}_u$ 를 생성한다. 이어서, updator에서는 주변에서 전달받은 정보와 현재 노드가 가지고 있던 feature 벡터 $\mathbf{z}_u$ 를 결합하는 방법을 소개한다.
3.2.1. Context-only Updater
노드가 가지고 있던 feature vector인 $\mathbf{z}_u$는 무시한채, 주변에서 전달받은 context 정보만을 사용하는 방법이다. 따라서 실제 수식에서도 $\mathbf{z}_u$는 등장하지 않으며, 주로 MLP를 사용해 한 번 전달받은 정보를 정제하여 사용한다.
또 다른 방법으로는 context vector에 대해 선형변환을 적용하기 전, 비선형함수를 한 번 적용하여 update하는 방법도 존재한다. $\Rightarrow \gamma(\mathbf{n}_u)$
3.2.2. Single-interaction Updater
이번에는 context-only updater에서 유저가 가지고 있떤 고유한 feature vector 정보를 결합하여 업데이트 하는 부분이 추가된 방법론이다. 기존에 유저 $u$가 가진 feature vector인 $\mathbf{z}_u$와 aggregator로 전달받은 context vector인 $\mathbf{n}_u$를 결합하는 방법은 여러가지가 있지만 여기서는 간단한 계산들을 사용한다. ex. element-wise product, sum, concatentation
3.2.3. Multi-interaction Updater
Single-interaction updater를 검토하면서, Sum이나 Concatenation을 사용하여 특정 feature의 값을 결합하는 방법의 적절성은 이해가 되었지만, 어떤 operator를 선택해야 할지 결정하는 것이 어려울 것이라는 의문이 들었다. 이에 대응하여, multi-interaction updater에서는 단일 operator만 사용하는 것이 아니라, 여러 operator를 사용하는 방법을 소개한다.
4. Solution to practical recommendation issues
4.1. Cold Start
Cold start 문제는 추천 시스템에서 중요한 문제 중 하나로, 처음 가입한 유저나 처음 등록된 상품에 대한 정보가 부족하여 적절한 추천을 제공하지 못하는 상황을 의미한다. 이 문제를 해결하기 위해 Knowledge Graph에서는 아래의 두 가지 방법을 사용한다고 한다.
4.1.1. Uniform term embedding
MEIRec을 발표한 저자는 아이템 추천에 있어서 현재 아이템의 이름(제목)이나 쿼리를 기반으로 이전 기록과 유사한 항목을 추천하는 방법을 제시한다. 어떤 상품이 등록되었을 때, 해당 제목이나 이름이 있다면, 이를 활용할 수 있는 방법으로 제시하는 것은 제목을 전부 사용하는 것이 아니라, 키워드 몇 개만을 선택하여 임베딩을 생성하는 것이다. 이렇게 단어들로 생성된 임베딩은 새롭게 만들어진 신규 아이템에 대한 정보를 제공하며, 이 정보를 기반으로 사용자들에게 추천을 제공한다.
4.1.2. Masked embedding training with encoder-decoder architecture
Cold start 문제를 해결하는 두 번째 방법으로, encoder-decoder 구조를 knowledge graph에 적용하는 방식을 사용한다. 이 접근법에서는 현재 입력 노드와 knowledge graph의 구조적 정보를 함께 제공한 후, knowledge graph 내 노드들의 임베딩 표현을 학습할 수 있도록 인코더를 설계한다. 디코더는 인코더로부터 얻은 knowledge graph 노드의 압축된 표현을 활용하여, 아직 실제 임베딩 값이 없는 아이템에 대한 노드 임베딩을 생성한다.
4.2. Scalability
Knowledge graph의 크기에 따라 이웃 노드의 수가 매우 커질 수 있다는 점을 고려할 때, 이웃 정보를 결합하여 새로운 context 벡터를 생성하는 aggregator의 계산량은 큰 그래프에서는 부담이 될 수밖에 없다. 이러한 문제를 해결하기 위해 논문에서는 세 가지 방법을 제시하고 있다.
4.2.1. Important node sampling
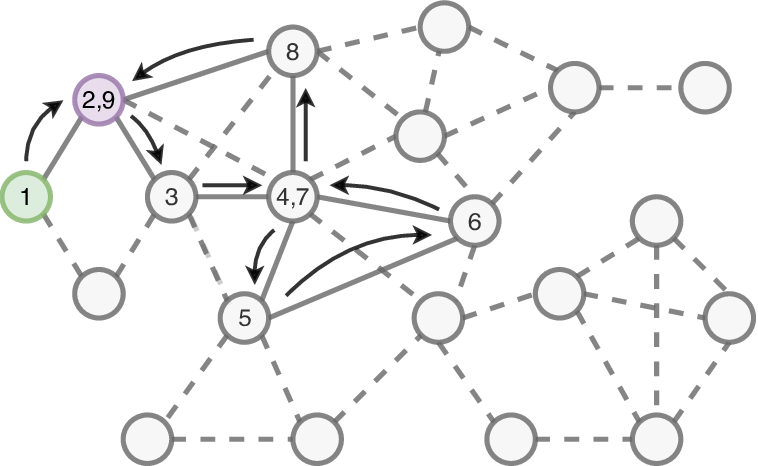
가장 간단한 방법 중 하나는 모든 이웃들의 정보를 사용하는 것이 아니라, 일부만을 사용하는 것이다. 단순히 아무 이웃이나 선택할 수는 없기 때문에, 현재 유저 노드 $u$와 관련성이 높은 이웃을 선택하게 된다. 관련성을 계산하기 위해서는 주로 random walk에 기반한 방법을 적용하며, 최대 $k$-hop까지 random walk를 수행할 수 있도록 설정한다. Random walk를 통해 특정 노드에 빈번히 방문하게 되면, 이는 현재 유저 노드로부터 해당 노드까지의 도달 가능성이 높음을 의미하며, 이를 높은 관련성으로 해석할 수 있다.
4.2.2. Meta-path defined receptive field
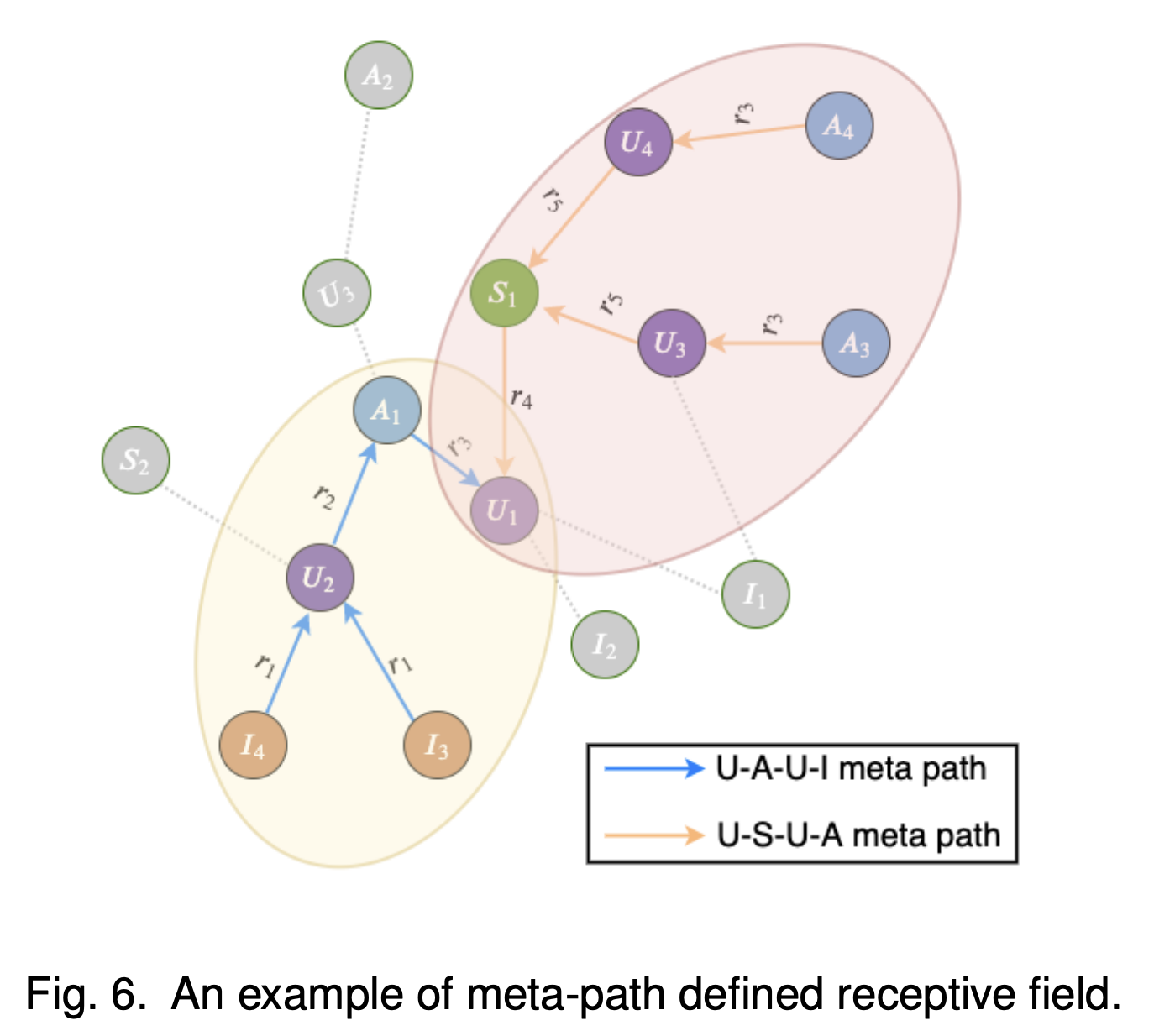
노드를 선택하는 두 번째 방법은 meta-path 기반 선택이다. 이 방법을 채택하면, 특정 의미론적 관점에서 연관된 노드만을 선별하여 사용할 수 있으며, 이를 통해 더욱 정확한 추천을 제공할 수 있다. Meta-path와 receptive field에 대한 정의는 다음과 같다.
Meta-path
Meta-path는 relation type의 sequence를 만족하는 가능한 모든 경로를 의미한다. 예를 들어, ${ r_1, r_2, \cdots, r_l }$ 을 만족하는 meta-path는 $t_1 \overset{r_1}{\rightarrow} t_2 \overset{r_2}{\rightarrow} \cdots \overset{r_l}{\rightarrow} t_{l+1} $ 을 말한다.
Meta-path defined Receptive Field(MRF)
MRF는 주어진 meta-path로 traverse가 가능한 노드들의 집합 또는 그 영역을 말한다. 때로는 MRF의 영역을 키우기 위해 여러 meta-path를 결합하기도 한다.
4.3. Dynamicity
Knowledge graph는 시간이 지나면서 상당히 빠르게 변화하는 그래프이다. 친구 관계가 주어진 소셜 그래프에서조차 following 관계는 계속해서 변화하기 때문에, 이러한 변화하는 정보를 반영할 필요가 있다. 하지만, 모든 정보를 매번 업데이트하는 것은 계산 비용을 크게 증가시키므로, 다른 대안을 모색해야 한다.
논문에서는 전체 노드를 업데이트하는 대신, 현재 유저에 관련된 노드만 업데이트를 진행한다고 한다. 이는 자신의 정보가 변경된 부분만 반영하고, 친구들의 정보는 변경하지 않음을 의미한다. 자신의 정보 변경이 전파될 때, 친구들의 정보 역시 새로운 상태로 업데이트될 가능성을 열어둔다. 더욱 세밀한 조정을 위해, 친구별로 다르게 정보를 반영하기 위해 graph attention network(GAT)를 사용하여 attention mechanism을 적용하는 방식도 도입된다.
5. Future direction
GNN을 활용하여 knowledge graph 기반의 추천 시스템에 대한 연구가 등장한 것은 사실상 그리 오래되지 않았다. 이로 인해, 이 분야가 앞으로 상당한 발전을 이룰 것이라는 전망이 있다. 항상 생각해왔던 것은, 우리의 소비 행위나 일상적인 행동들이 그래프로 표현될 수 있다는 점이다. 이에 따라, 충분한 연구와 발전이 이루어진다면, 우리 스스로도 잘 인지하지 못하는 개인의 성향을 정확하게 모델링할 수 있을 것으로 기대된다.
논문 저자가 제안하는 향후 연구 방향은 아직 충분히 발전하지 못했거나 해결되지 않은 문제들에 대한 목록을 포함하고 있다. 이들은 현재의 상황과 비교하여 소개되며, 연구 필드의 발전 가능성과 필요성을 강조한다.
5.1. Scalability Trade-Off
확장성 문제는 지식 그래프의 크기가 커짐에 따라 이웃 노드의 수가 증가하고, 이로 인해 연산량도 동시에 많아지는 현상을 지칭한다. 일반적으로 이 문제를 해결하기 위해 모든 이웃을 고려하는 대신, 소수의 이웃만을 선택하여 계산량을 줄이는 방법이 채택되곤 한다. 그러나 이러한 접근 방식은 중요한 이웃을 놓칠 수 있다는 단점이 있다. 물론, 중요도를 기준으로 이웃을 정렬하고 상위 $k$개의 이웃을 선택하는 방법이 있지만, 이 중요도 지표가 항상 정확하다는 보장은 없다.
5.2. Dynamicity
Knowledge graph의 정보는 지속적으로 변화한다: 새로운 노드가 생성되기도 하고, 기존의 노드가 사라지기도 하며, 관계(relation)의 유형도 변할 수 있다. 이러한 실시간으로 변화하는 지식 그래프를 효과적으로 모델링하기 위해서는 새로운 aggregator와 updater가 필요하다. 논문에서는 이와 관련된 연구가 아직 부족하여, 향후 추가적인 연구가 필요하다는 점을 강조한다.
5.3. Explainability of Recommendation
추천 결과에 대한 설명을 제공하는 것은 항상 중요한 문제로 여겨져 왔다. 추천 시스템에 대한 사용자의 신뢰를 증가시키고, 더 나은 추천을 가능하게 하는 원인 설명은 사용자 경험을 크게 향상시킨다. 이 문제는 오래전부터 연구되어 왔으나, 다양한 유형의 관계를 포함하는 heterogenous knowledge graph를 사용하여 추천 결과의 원인을 정확하게 설명하는 방법은 아직 개발되지 않았다. 따라서 이 분야는 앞으로도 지속적인 연구가 필요한 영역이다.
5.4. Fairness of Recommendation
추천의 결과에 어떠한 편향 정보가 생기는 것을 말한다. 쉬운 예로, 어떤 뉴스기사가 추천될 때, 특정 정치색을 띈 뉴스기사만 추천된다면 이는 편향된 추천이 이루어지고 있음을 말한다. 이는 크게 2가지 원인에 의해서 발생하게 된다.
- observation bias: 모델이 현재 보고있는 뉴스와 유사한 뉴스만을 검색하기 때문에 발생
- bias stemming from imbalance data: 데이터 자체가 편향되어 있어 추천결과도 편향되어 발생
전통적인 추천시스템인 collaborative filtering(CF)에서는 공정한 추천이 이루어지도록 연구가 이루어지고 있지만, knowledge graph를 사용하는 추천시스템에서는 아직 문제를 해결하는 방안이 제시되지 못하였다.
5.5. Cross-Domain Recommendation
추천 시스템의 성능을 향상시키기 위해 여러 지식 그래프를 결합하는 제안은, 하나의 지식 그래프만으로는 모든 정보를 포괄하기 어렵고, 각기 다른 지식 그래프가 가지고 있는 정보의 특성을 통합함으로써 추천 성능을 개선하고자 하는 방안이다. 그러나, 여러 지식 그래프를 통합하는 구체적인 방법론이 확립되어 있지 않다는 점이 문제로 지적된다. 노드의 종류가 서로 다를 수 있고, 관계(relation)의 유형도 다양하여 하나의 통합된 그래프로 관리하기 어렵다는 점이 주요한 도전 과제이다. 이 문제를 해결하기 위한 한 가지 노력으로는 spectral 클러스터링 알고리즘의 적용이 있었다.
6. References
[1] Gao, Yang, et al. “Deep learning on knowledge graph for recommender system: A survey.” arXiv preprint arXiv:2004.00387 (2020).
[2] Fan, Shaohua, et al. “Metapath-guided heterogeneous graph neural network for intent recommendation.” Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. 2019.
[3] Pal, Aditya, et al. “Pinnersage: Multi-modal user embedding framework for recommendations at pinterest.” Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
[4] Xu, Fengli, et al. “Relation-aware graph convolutional networks for agent-initiated social e-commerce recommendation.” Proceedings of the 28th ACM international conference on information and knowledge management. 2019.
[5] Zhao, Jun, et al. “Intentgc: a scalable graph convolution framework fusing heterogeneous information for recommendation.” Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019.