Tacotron - Towards end-to-end speech synthesis
Tacotron - Towards end-to-end speech synthesis
- Arxiv 2017
- Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, Quoc Le, Yannis Agiomyrgiannakis, Rob Clark, Rif A. Saurous
Abstract
- 이전 음성합성 모델들은 “텍스트 분석 + 어쿠스틱 모델 + 오디오 합성 모듈”로 구성
- 위 구조 때문에 음성 도메인의 전문지식을 요구하며 불안정한 구조를 갖게 됨
- Tacotron 모델은 글자로부터 바로 음성을 생성시키는 end-to-end 모델
- 결과적으로, MOS점수 3.82점/5점 을 달성!
1. Introduction
- 기존 음성합성은 “텍스트 전처리 + 발화 길이 예측 모델 + 어쿠스틱 모델 + 보코더 모델”로 구성
- 어쿠스틱 모델: 글자로 부터 스펙트로그램 또는 멜스펙트로그램을 생성
- 보코더 모델: 스펙트로그램으로부터 실제 들을 수 있는 음성으로 변환해주는 모델
- *스펙트로그램: 음성신호를 주파수대역으로 펼쳤을 때 어디에 어떤 음이 존재하는지를 나타낸 값
- 위 처럼 여러 모델로 구성된 음성합성은 각 모델에서 발생하는 에러가 모두 더해지므로 큰 에러를 발생시킴
1.1. End-to-end 모델의 장점
- 많은 노력이 들어가는 피처 엔지니어링 과정을 end-to-end 시스템이 담당
- 음성 속에 포함된 감정이나 다양한 속성들에 대한 추가 학습을 허용
- 음성을 제어하는 부분이 모델의 초기에서 진행되기 때문
- 다시 말해, 음성을 제어하는 것이 모델의 여러 컴포넌트에서 이루어지지 않음!
- 하나의 단일 모델만을 사용하기 때문에 에러가 상대적으로 적다
1.2. 음성합성 모델의 어려움
- One-to-many 문제의 발생: 동일한 텍스트이더라도 여러 음성이 생성될 수 있음
- 생각해보면, 동일한 텍스트이더라도 누가 읽는지에 따라 완전히 다른 음성이 발생
- 음성인식 또는 기계 번역 모델과는 다르게 음성합성은 시계열 결과를 보여줘야 하며 그 길이가 매우 길다.
- 위 문제 때문에 음성합성 모델을 구현하는 것이 까다로움
1.3. Tactron 모델의 간략한 설명
- Attention 패러다임에 기반을 둔 end-to-end 음성합성 모델
- 모델은 문자를 입력받아 스펙트로그램을 생성
- 생성된 스펙트로그램은 간단한 waveform 합성 모듈을 거쳐 실제 음성으로 변환
- 학습 데이터로는 <텍스트, 오디오> 쌍으로 구성
- 음소단위로 구성된 alignment가 별도로 필요하지 않아 대규모 데이터셋에 대해 사용할 수 있음
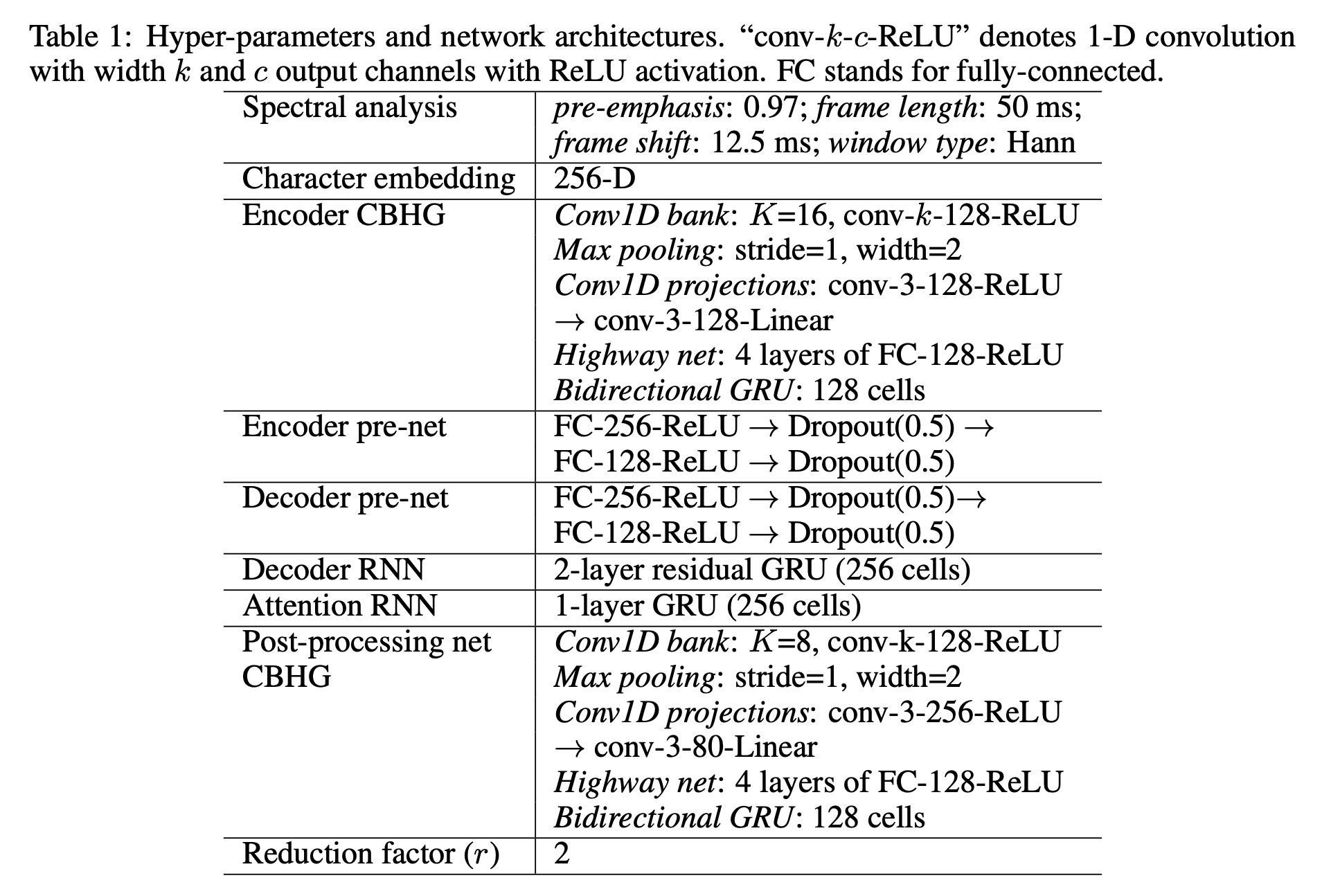
2. Model Architecture
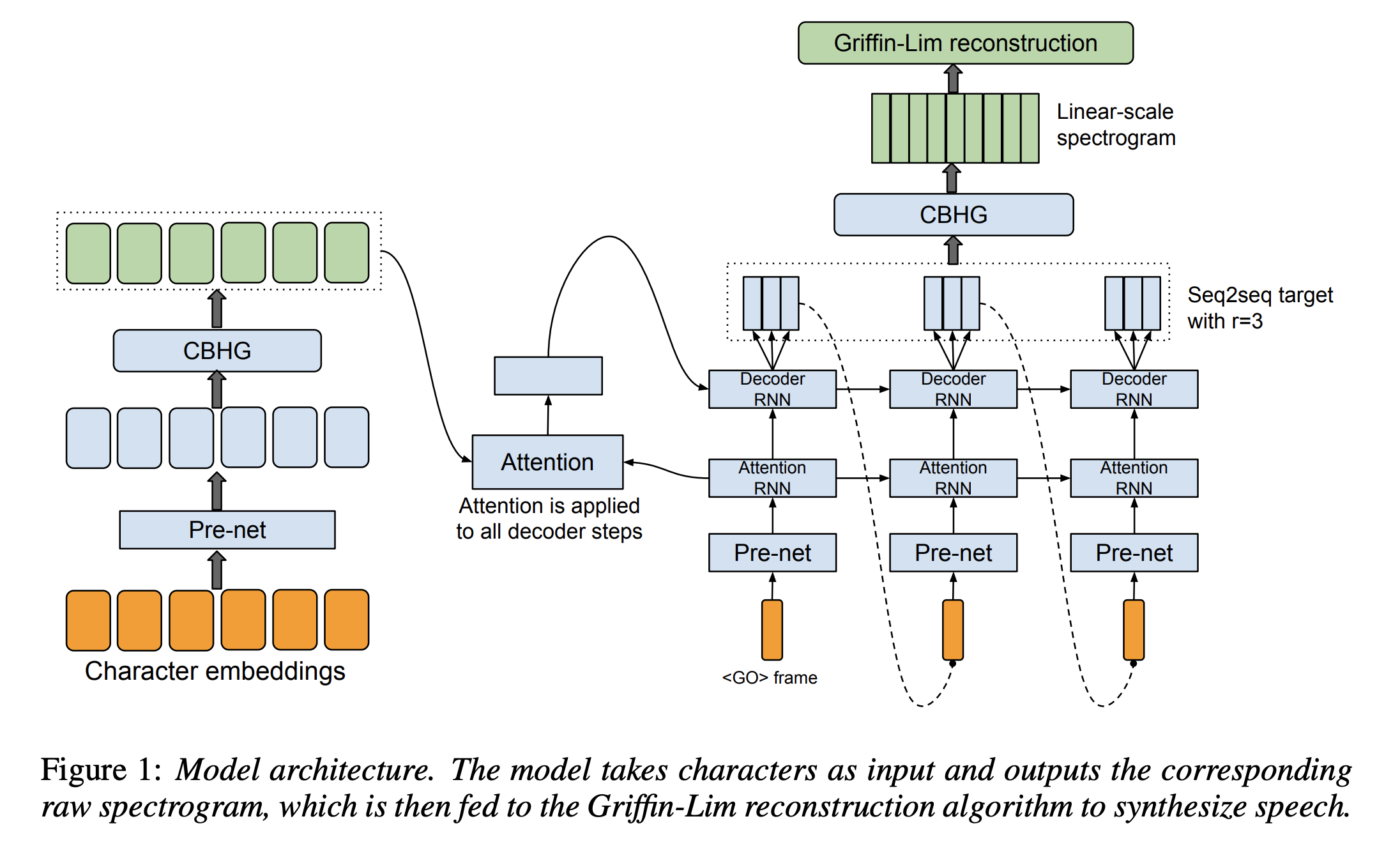
- 인코더
- 디코더 (어텐션 기반)
- 후처리 신경망 (post-processing net)
2.2. Encoder 파트를 먼저 읽고 다시 2.1. CBHG를 읽는 것을 권장합니다.
2.1. CBHG 모듈
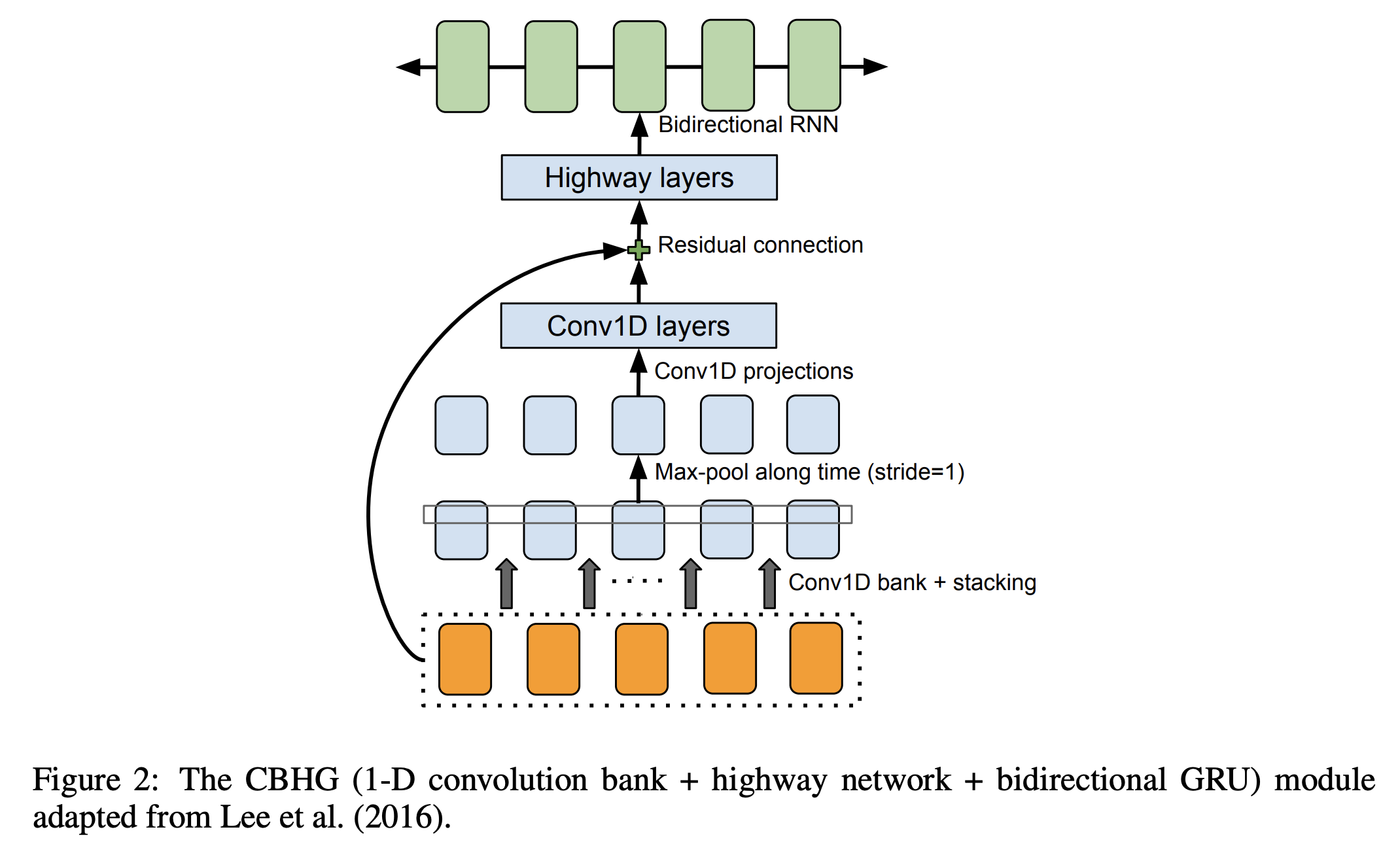
- 인코더에 존재하는 모듈로서 시퀀스에 존재하는 특징들을 추출하는데 탁월
- 모듈의 구성
- Bank of 1D-Convolution filters
- Highway networks
- Bidirectional GRU
2.1.1. Bank of 1D-Convolution filters
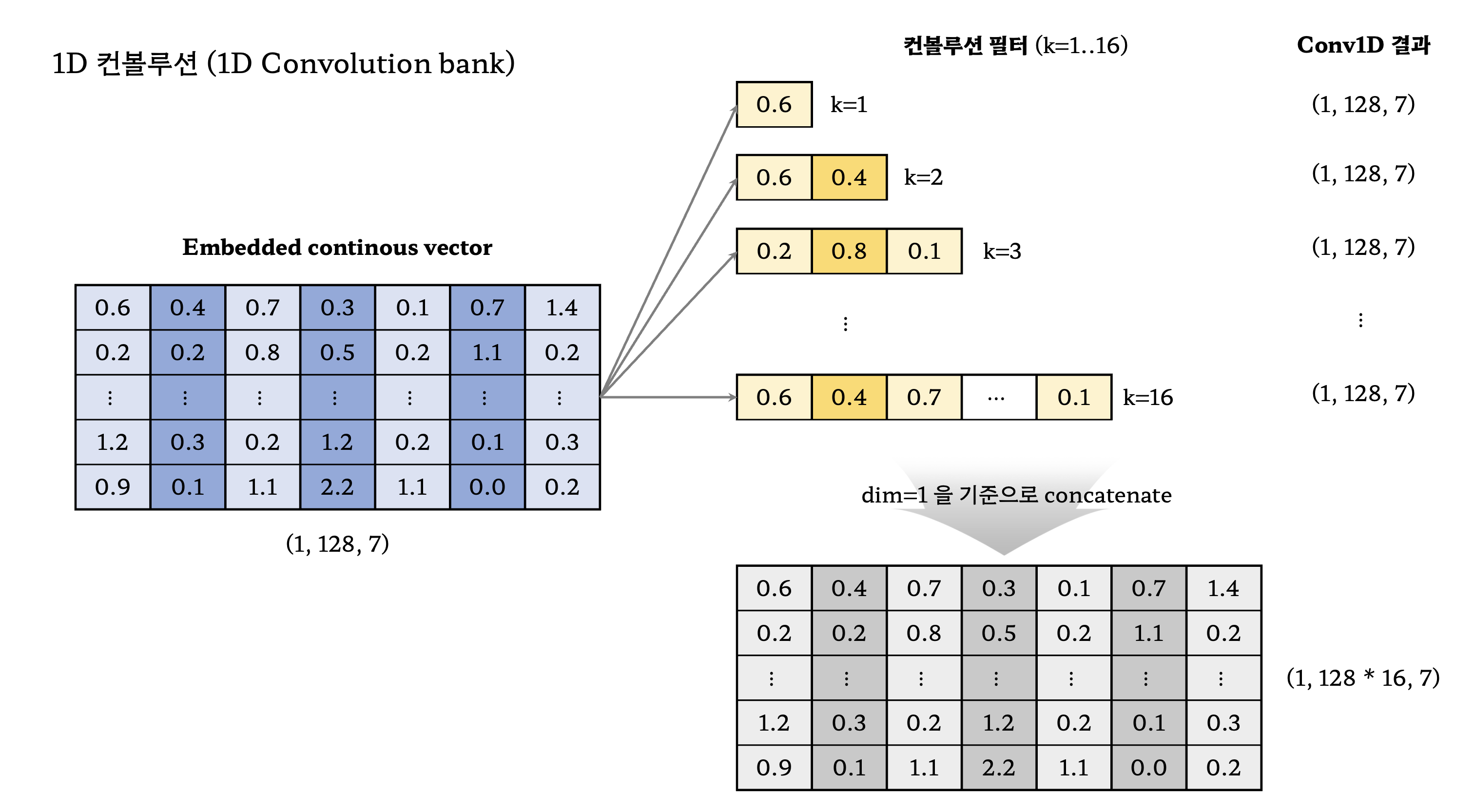
- 1D-Convolution filter를 총 $K$ 개 사용하였으며, 이 때 $k$ 번째 filter의 너비는 $k$ 이다.
- 논문에서는 $K$ 를 16으로 설정하였기 때문에 필터의 너비가 1부터 16까지 하나씩 있음을 의미한다.
- 1D Convolution에 대해서 잘 이해가 안가서 바로 아래에 설명을 첨부
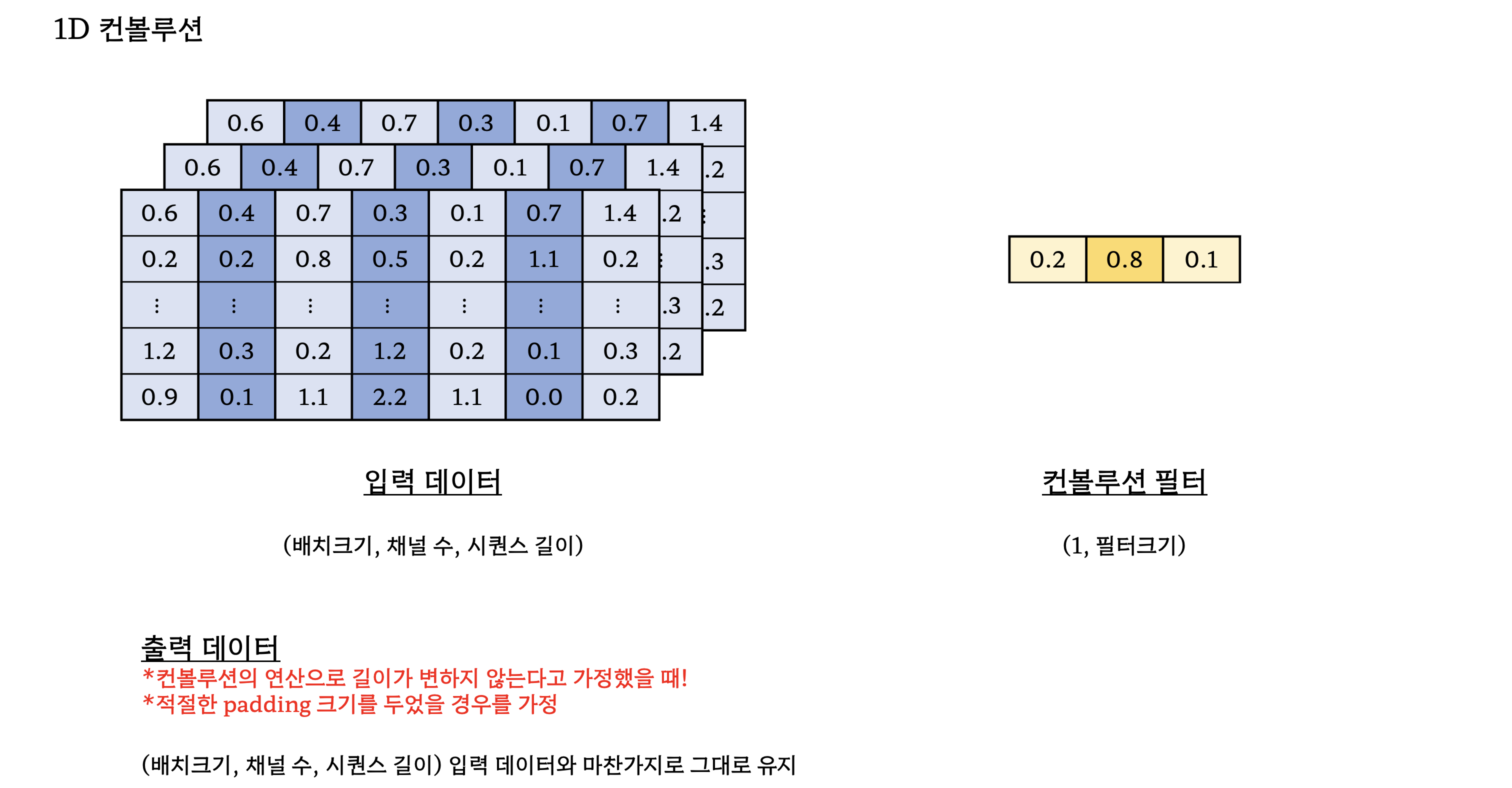
- 위의 그림에 등장하는 모든 1D 컨볼루션 연산에는 ReLU 활성함수와 배치정규화를 적용
- 특히 컨볼루션을 적용해도 차원을 유지시켜주는 것은 원래의 time resoultion을 유지하기 위함
- 1D 컨볼루션 bank를 거친 이후에는 max pooling을 적용 (특징들을 추출하기 위함)
- 더 전문적으로, local invariance를 높여 다양한 변화에서도 특징들을 잘 추출할 수 있도록 한 것
- Max pooling 이후, (1, 128 * 16, 7) 크기의 출력을 다시 (1, 128, 7)로 만들기 위해 2개의 convolution layer를 추가로 도입
- (1, 128 * 16, 7) $\rightarrow$ (1, 128, 7) $\rightarrow$ (1, 128, 7)
2.1.2. Highway networks
- 이후 resnet의 residual connection의 등장을 도와준 개념
- 다음 레이어로 전달할 때, 비선형변환을 한 것과 하지 않은것을 적절히 조합
- 논문에서는 4개의 highway 네트워크를 쌓아올림 (한번 더 고차원의 특징들을 추출하기 위함)
- $x$ : 입력 데이터
- $H$ : 변형 함수 (일반적으로 비선형 변환)
- $T$ : 얼마나 변형을 줄 것인지 (게이트함수, sigmoid를 사용해 0과 1사이의 값으로 조절)
- $\mathbf{W}$ : 각 함수에서 사용되는 가중치
2.1.3. GRU
- 정확히는 bidirectional GRU를 사용
- 양방향을 통해 정방향, 역방향 문맥 구조를 살펴 특징들을 추출하기 위한 용도로 사용
nn.GRU(input_dim=128, hidden_dim=128, num_layers=1, batch_first=True, bidirectional=True)
2.2. 인코더
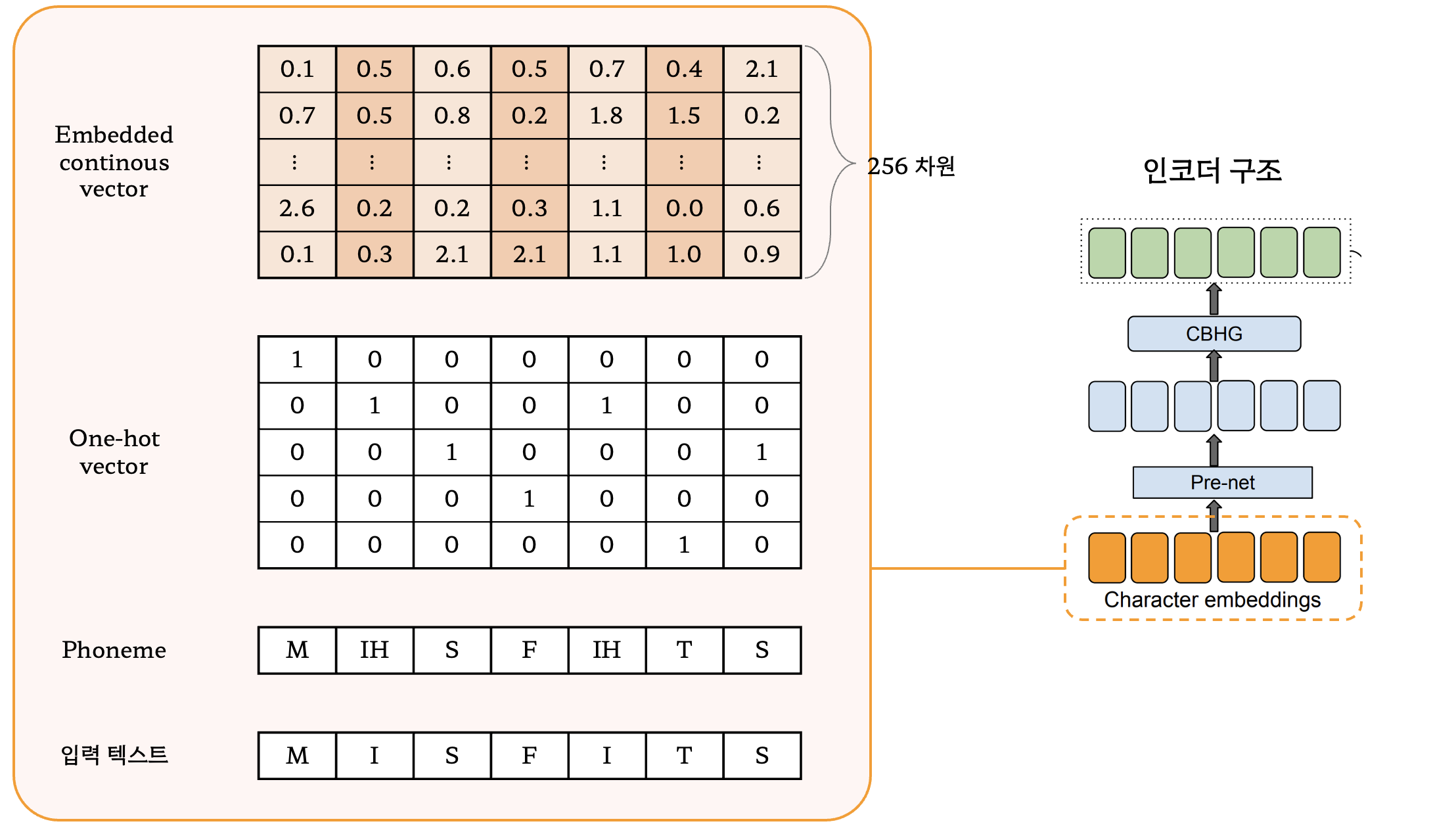
- 입력 문자열을 모두 원핫벡터로 변환
- 원핫벡터들은 다시 임베딩을 거쳐 시퀀스 벡터로 변환 (논문에서는 256차원으로 설정)
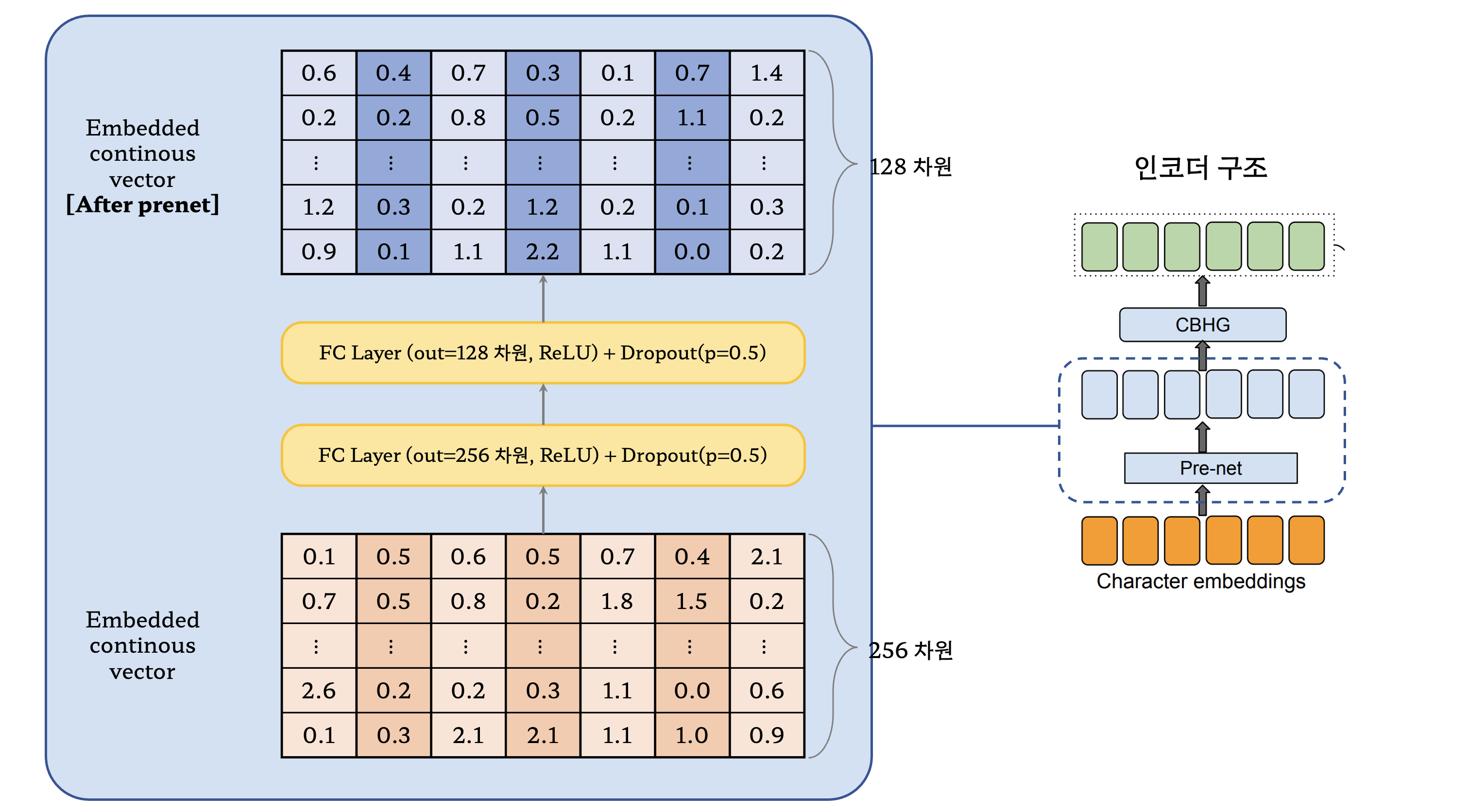
- 2개의 Fully Connected Layer를 거치도록 하고 점점 차원이 축소되는 bottleneck 구조를 활용
- Dropout을 두어 일반화 성능이 좋게 함
- 인코더 구조에 존재하는 Pre-net 덕분에 최적화 과정에서 수렴이 더 잘되도록 만들 수 있음
- 이후 앞서 설명하였던 CBHG 모듈을 거치면 Tacotron 모델의 인코더파트가 완성!
- 인코더의 결과는 이후 attention 메커니즘에 의해 사용될 예정
📖 Tacotron 인코더 정리
- 입력 텍스트를 임베딩 벡터로 변환
- 임베딩 벡터속에 존재하는 특징들을 CBHG 모듈내에서 1D 컨볼루션들의 결합, highway 네트워크, 양방향GRU를 통해 추출
- 추출된 결과는 이후 디코더에서 attention 파트에서 사용될 예정
2.3. 디코더
- Decoder는 auto-regressive한 모습을 띄고 있음
- 주요 모듈로는 attention, GRU 가 존재
- Content-based tanh attention 디코더 사용 (Vinyals et al. (2015))
- 아래의 수식은 해당 attention 디코더에 해당
- 벡터 $v$, 행렬 $W_1^\prime, W_2^\prime$ 은 모델의 파라미터
- 벡터 $u^t$ 는 $T_A$ 의 길이를 갖으며, $u_i^t$ 는 $i$ 번째 인코더 출력 상태인 $h_i$ 에 얼마나 가중치(attention)을 가져야 하는지를 나타냄
- 디코더의 결과인 $d_t^\prime$ 과 $d_t$ 를 concatenate 하여 다음 step의 입력으로 사용 ($d_t = [d_t^\prime ; d_t]$)
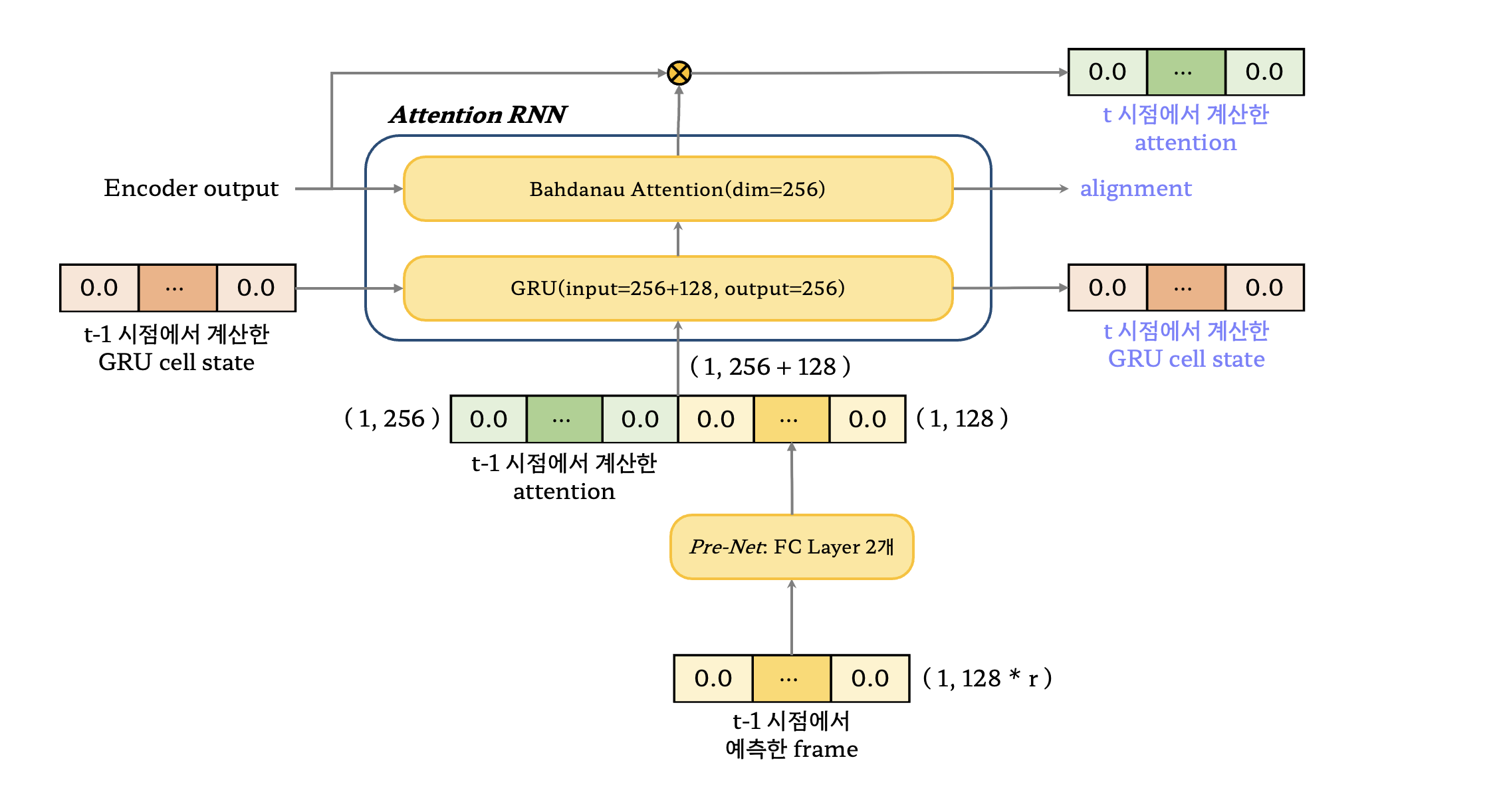
- 먼저 이전 timestep에서 예측한 frame을 디코더의 첫 입력으로 사용
- 만약 첫 번째 timestep인 경우에는 이전 timestep이 없으므로 0으로 채워진 텐서를 사용
- 디코더의 입력을 Pre-Net을 통과하여 한 번의 비선형 변환을 시켜줌
- 이전 시점에서의 attention 연산결과와 pre-net의 결과를 이어붙여 Attention RNN 모듈로 전달
- 마찬가지로 이전 시점이 없는경우, attention 연산결과도 0으로 채워진 텐서를 사용
- Attention RNN모듈은 GRU와 Attention으로 구성
- GRU에서 사용되는 cell state는 이전 timestep의 cell state를 사용하고 입력은 concatenate 시킨 결과를 사용
- 마찬가지로 이전 시점이 없는경우, cell state도 0으로 채워진 텐서를 사용
- GRU에서 새롭게 계산된 cell state는 다음에 사용하게 됨
- Cell state는 다시 attention 계산에서 사용
- Bahdanau attention에서는 cell state와 인코더의 최종 출력에 대해 연산을 수행
- 현재 cell state에 대해 어떤 글자와 매핑이 되는지를 확인하고 alignment를 생성하는 것
- Bahdanau attention 결과의 alignment는 softmax를 씌워 비율로 계산될 수 있게 함
- Alignment는 다시 encoder와 가중합을 취해 현재 시점의 attention 벡터를 구함
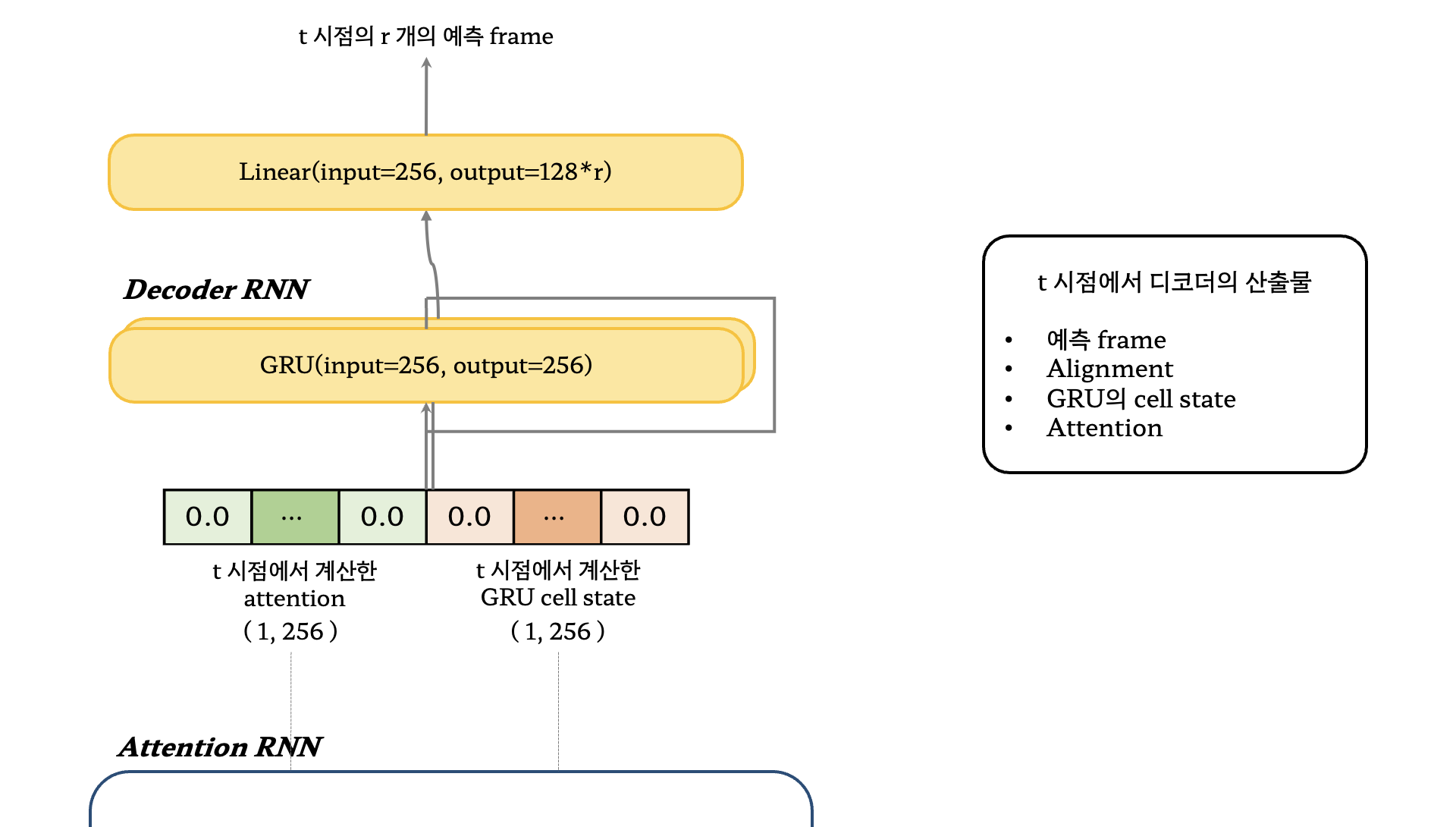
2.4. 후처리와 웨이브폼 합성
- 후처리에서는 모델의 인코더에서 사용된 CBHG 모듈과 함께 선형 레이어를 채택
- CBHG에서 커널의 개수는 16개가 아닌 8개를 사용
- 디코더의 결과를 실제 들을 수 있는 음성으로 변환하는 파트 (seq2seq)
- 음성합성기로 griffin-lim 알고리즘을 사용하였기에 선형 scale에서 어떤 주파수대역의 중요도를 찾아내기만 하면 됨
- 양방향 정보를 모두 사용하기 위해 인코더 파트의 CBHG를 그대로 가져와서 사용
- Griffin-lim 알고리즘은 최대 50 iteration 정도면 충분히 수렴
- 미분가능한 함수이므로, 별도의 가중치를 두어 최적화할 필요없이 바로 최적의 해를 구할 수 있음
- 이번 논문에서 griffin-lim을 선택한 것은 단지 단순했기 때문이며, 앞으로 더 좋은 보코더 모듈을 사용해도 좋음
3. Model Details
4. References
This post is licensed under CC BY 4.0 by the author.