Tacotron 2 (심화)
Tacotron 2는 두 가지 주요 구성 요소로 이루어진 음성 합성 시스템입니다. 바로 인코더(Encoder)와 디코더(Decoder)로 이루어진 특징 예측 네트워크와, 멜 스펙트로그램을 기반으로 최종 음성을 생성하는 WaveNet 보코더입니다. 이 중에서도 인코더와 디코더의 구조가 Tacotron 2의 핵심입니다. 이 섹션에서는 이 두 모델의 동작 방식과 구조를 더 자세히 설명하고, 왜 이들이 음성 합성에서 중요한 역할을 하는지 알아보겠습니다.
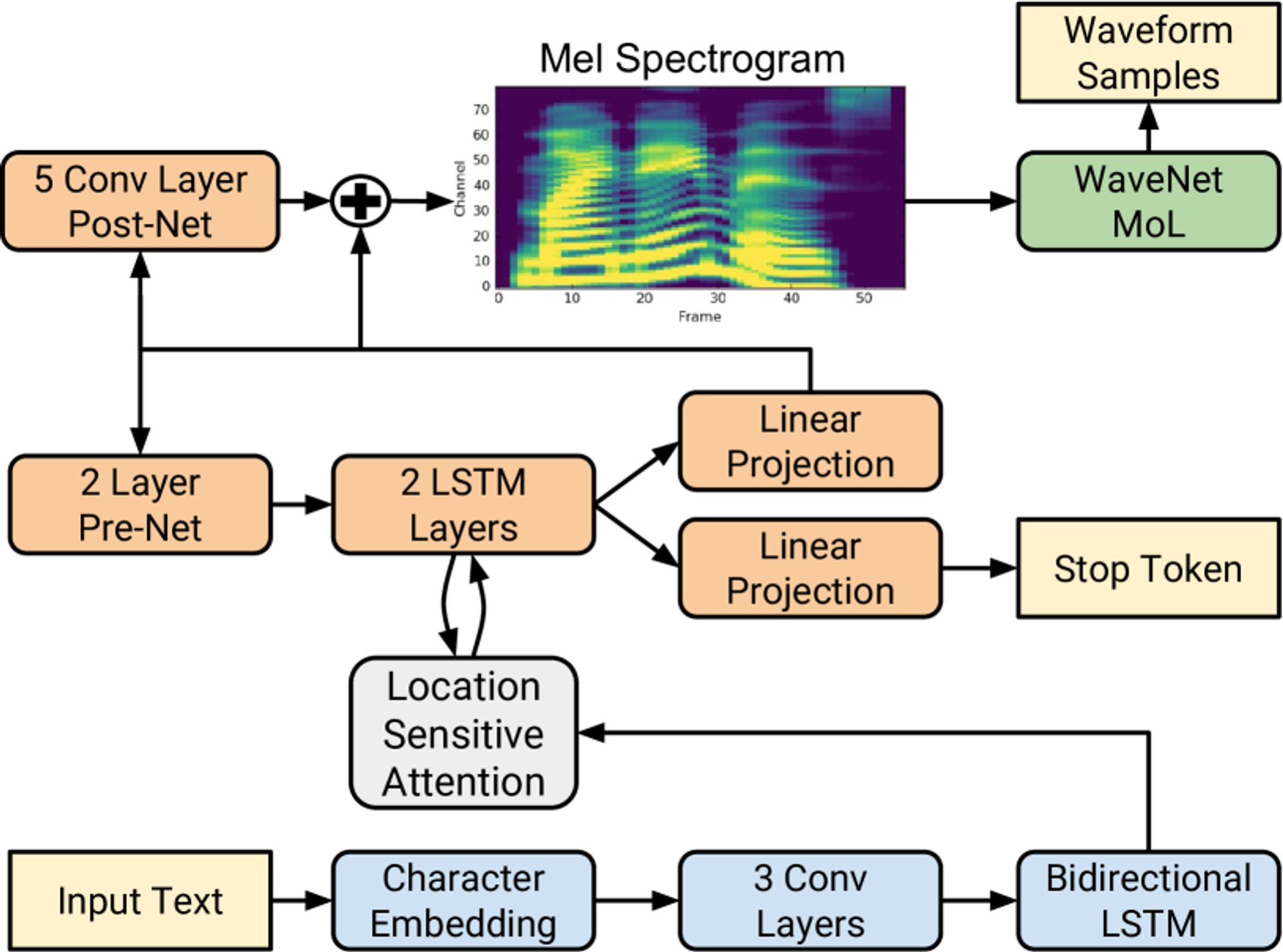
1. 인코더 (Encoder)
인코더는 입력된 텍스트, 즉 문자(character) 시퀀스를 받아 이를 고차원적인 특징 표현(hidden feature representation)으로 변환하는 역할을 합니다. 이 과정은 텍스트를 분석하고, 문맥을 파악한 후, 해당 텍스트가 음성으로 변환되기 위한 적절한 정보를 추출하는 과정입니다. 구체적으로, Tacotron 2의 인코더는 다음과 같은 단계로 구성됩니다:
문자 임베딩 (Character Embedding)
입력된 텍스트는 먼저 512차원 임베딩 벡터로 변환됩니다. 이 벡터는 각 문자의 의미를 숫자로 표현한 것으로, 모델이 텍스트의 패턴을 더 쉽게 파악할 수 있도록 돕습니다. 쉽게 말해, 문자를 바로 처리하기보다는, 그 문자에 대응하는 의미 공간을 사용하여 추상적인 표현으로 변환하는 과정입니다. 예를 들어, ‘a’라는 문자를 512차원 임베딩 벡터로 변환하면, 이 벡터는 문자 ‘a’의 특징을 표현하게 됩니다.3개의 컨볼루션 층 (Convolutional Layers)
문자 임베딩 벡터는 512개의 필터를 가진 3개의 컨볼루션 층을 통과하게 됩니다. 각 컨볼루션 층은 길이 5의 필터를 사용하며, 이는 입력 텍스트에서 5개의 문자씩 묶어서 문맥을 파악하도록 돕습니다. 이 과정은 길이가 긴 문맥을 학습하고, 텍스트에서 나타나는 패턴이나 N-그램과 같은 구조를 더 잘 이해할 수 있게 합니다.양방향 LSTM (Bidirectional LSTM)
컨볼루션 층을 통과한 후, 마지막으로 양방향 LSTM(Long Short-Term Memory) 네트워크가 사용됩니다. LSTM은 순환 신경망(Recurrent Neural Network, RNN)의 일종으로, 긴 시퀀스에서 문맥을 잘 유지하면서 정보를 처리할 수 있습니다. 여기서 양방향 LSTM은 앞으로 가는 정보뿐만 아니라 뒤로 가는 정보도 동시에 학습합니다. 이는 문장 내에서 앞뒤 문맥을 모두 반영한 더 풍부한 특징 표현을 생성하는 데 도움을 줍니다.
2. 디코더 (Decoder)
디코더는 인코더에서 생성된 고차원 표현을 받아, 이를 음성 특징(즉, 멜 스펙트로그램)으로 변환하는 역할을 합니다. Tacotron 2의 디코더는 자기회귀적(autoregressive) 방식으로 설계되었으며, 한 번에 하나의 프레임씩 음성 특징을 예측합니다. 구체적인 동작 방식은 다음과 같습니다:
프리넷 (Pre-Net)
디코더는 먼저 이전 단계의 예측값을 받아, 이를 256개의 노드를 가진 완전 연결 층(Fully Connected Layer) 두 개를 통과시킵니다. 이를 프리넷(Pre-net)이라고 부르며, 이 단계는 모델이 병목(bottleneck)을 겪도록 만들어, 학습 시 어텐션 메커니즘이 더 효과적으로 작동하도록 돕습니다. (그 이유는 아래에 설명!!)어텐션 메커니즘 (Attention Mechanism)
디코더는 어텐션 메커니즘을 사용하여 인코더에서 생성된 전체 시퀀스를 효과적으로 요약합니다. 이를 통해 디코더는 출력 프레임을 예측할 때 모든 인코더 출력을 참고할 수 있습니다. Tacotron 2는 특히 위치 기반 어텐션(Location-Sensitive Attention)을 사용합니다. 이는 각 디코딩 단계에서, 이전 디코딩 단계의 어텐션 가중치를 누적하여 반영하는 방식입니다. 이 방법은 디코더가 같은 부분을 반복하거나 건너뛰는 문제를 줄여줍니다. 즉, 모델이 일관되게 텍스트를 따라가며 올바른 음성을 생성할 수 있도록 돕습니다.LSTM 층 (LSTM Layers)
프리넷의 출력과 어텐션 컨텍스트 벡터는 연결되어 1024개의 유닛을 가진 두 개의 LSTM 층을 통과합니다. 이 LSTM 층은 주어진 문맥을 바탕으로 음성 프레임을 예측하는 데 중요한 역할을 합니다. LSTM은 긴 시퀀스에서도 이전 정보를 잘 기억하기 때문에, 음성의 자연스러운 흐름을 유지하는 데 필수적입니다.포스트넷 (Post-Net)
디코더에서 예측된 멜 스펙트로그램은 최종적으로 5개의 컨볼루션 층을 통과하는 포스트넷(Post-net)을 거칩니다. 이 포스트넷은 디코더의 예측값에 잔차(residual)를 더해 전체 음성의 재구성을 개선합니다. 이 단계는 음성의 세부적인 특징을 더 정교하게 만들어, 더 높은 품질의 음성을 생성하는 데 도움을 줍니다.정지 토큰 (Stop Token)
Tacotron 2는 추론 중에 출력 시퀀스가 언제 완료되었는지를 예측할 수 있도록 정지 토큰(Stop Token)을 사용합니다. 각 디코딩 단계에서, 디코더는 시그모이드 활성화 함수를 통해 출력 시퀀스가 완료되었을 확률을 예측합니다. 이 확률이 0.5를 넘으면, 모델은 더 이상 음성을 생성하지 않고 종료합니다. 이 방식 덕분에 Tacotron 2는 불필요하게 긴 음성 생성 과정 없이 적절한 시점에서 음성 출력을 마칠 수 있습니다.
왜 병목 현상이 Tacotron 2의 Attention 학습에 중요한가?
Tacotron 2에서 프리넷(pre-net)은 병목 현상을 유도해 attention 메커니즘이 더 효과적으로 학습되도록 돕는 핵심 구성 요소입니다. 병목 현상이란, 고차원 정보를 더 낮은 차원으로 압축하여 정보의 흐름을 제한하는 과정인데, 이 과정이 어떻게 attention 학습에 기여하는지 알아보겠습니다.
정보 과부하 방지
병목 현상을 통해 정보가 압축되면, 모델은 중요한 정보에 집중하고 덜 중요한 정보를 배제할 수 있게 됩니다. 만약 디코더가 처리해야 할 정보가 너무 많다면, 모델이 어디에 집중해야 할지 혼란스러워질 수 있습니다. 병목 현상을 통해 필수적인 정보만 남기고 덜 중요한 세부 사항은 제거되므로, attention 메커니즘이 더 핵심적인 문맥에 집중할 수 있게 됩니다.어텐션의 초점 강화
프리넷을 통해 정보를 압축하면 디코더는 더 간결한 정보를 처리하게 됩니다. 이렇게 간소화된 정보는 어텐션 메커니즘의 초점을 더욱 명확하게 만들어 주며, 디코더가 각 시간 단계에서 어디에 집중해야 하는지 쉽게 파악할 수 있게 합니다. 그 결과, 어텐션 가중치가 더욱 효과적으로 학습됩니다.
3. WaveNet 보코더 (WaveNet Vocoder)
Tacotron 2의 마지막 단계는 WaveNet 보코더입니다. 앞서 설명한 디코더에서 생성된 멜 스펙트로그램을 시간 도메인 파형으로 변환하는 역할을 합니다. 여기서 WaveNet은 입력받은 멜 스펙트로그램을 조건으로 삼아, 사람처럼 자연스럽고 부드러운 음성을 생성합니다. Tacotron 2에서 사용하는 WaveNet은 기존 WaveNet보다 간소화된 버전입니다. 30개의 팽창된 컨볼루션 층을 사용하던 기존 WaveNet과 달리, Tacotron 2는 12개의 층만으로도 충분한 성능을 발휘합니다. 이는 멜 스펙트로그램 자체가 이미 음성의 저수준 특징을 잘 반영하고 있기 때문입니다.
또한, Tacotron 2는 WaveNet의 출력을 로지스틱 분포 혼합(Mixture of Logistics) 모델로 처리하여 16비트, 24kHz의 고품질 음성 샘플을 생성합니다. 이 과정에서 손실 함수는 실제 음성과의 로그 가능도 차이를 최소화하는 방향으로 설계되었습니다. 이를 통해 WaveNet은 보다 정교하고 세밀한 음성을 만들어냅니다.
4. 정리
Tacotron 2는 인코더와 디코더, 그리고 WaveNet 보코더를 통해 텍스트를 인간처럼 자연스럽게 말할 수 있는 음성으로 변환합니다. 특히, 어텐션 메커니즘과 프리넷, 포스트넷 같은 구성 요소들은 Tacotron 2가 더 부드럽고, 일관된 음성을 생성하는 데 중요한 역할을 합니다. Tacotron 2의 인코더와 디코더는 긴 문맥을 처리하고, 발음을 정확하게 예측할 수 있게 설계되었습니다. 이 시스템 덕분에 우리는 점점 더 인간과 유사한 음성을 AI로부터 들을 수 있게 되어가는 중입니다 :)