Transformer
Transformer: Attention is all you need
- NIPS 2017
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin
Abstract
기계어 번역과 같은 sequence 변환 task에서 사용되던 모델들은 주로 복잡한 RNN구조나 CNN구조를 기반으로 하고 있었으며 반드시 encoder와 decoder를 필요로 하고 있었다. Transformer 논문이 발표되기 이전, 가장 좋은 성능을 내는 모델이더라도 encoder, decoder, attention mechanism을 적용했었다. 여기서 transformer팀은 encoder와 decoder를 없애고 attention mechanism으로만 대체하는데 성공했고, 그당시 뿐만 아니라 6년이 지난 지금까지도 많은 분야의 SOTA의 기본이 되고 있다.
1. Introduction
기존에는 RNN 구조를 기반으로 한 LSTM과 GRU가 기계번역 또는 sequence를 처리할 때 가장 좋은 성능을 보여주었다. 하지만, 이런 recurrent 모델들은 이전 시점의 입력을 반드시 필요로 하기 때문에 병렬처리에 있어서 제한을 받았고, 아주 긴 seqeunce를 처리하기 힘들다는 문제가 있다.
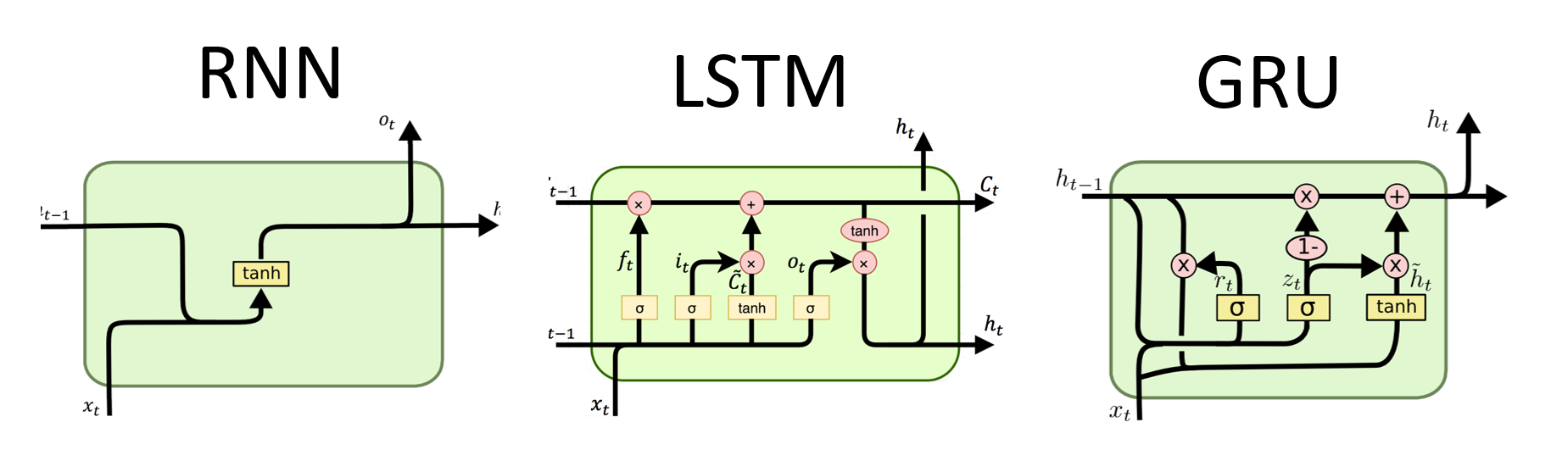
여기서 Google의 transformer팀은 병렬처리를 하기 위해 recurrental 구조를 제거하고 이를 attention mechanism으로 대체한 모델인 Transformer를 발표한다. 발표한 자료에 의하면, 병렬처리 덕분에 P100 GPU 자원으로 12시간 만에 SOTA에 달하는 성능을 보여주었다고 한다.
2. Model Architecture
Transformer 이전에 발표된 sequence to sequence 모델에서는 encoder와 decoder 구조를 띄고 있었으며, encoder 에서는 입력 데이터 $(x_1, x_2, \dots, x_n)$를 잠재공간 $(z_1, z_2, \dots, z_n)$으로 매핑시키고, 다시 decoder에서는 새로운 출력 $(y_1, y_2, \dots, y_n)$을 만들어내게 하였다. 이때 decoder에서는 이전 시점의 추론 결과도 함께 사용하도록 구성되어 있다.
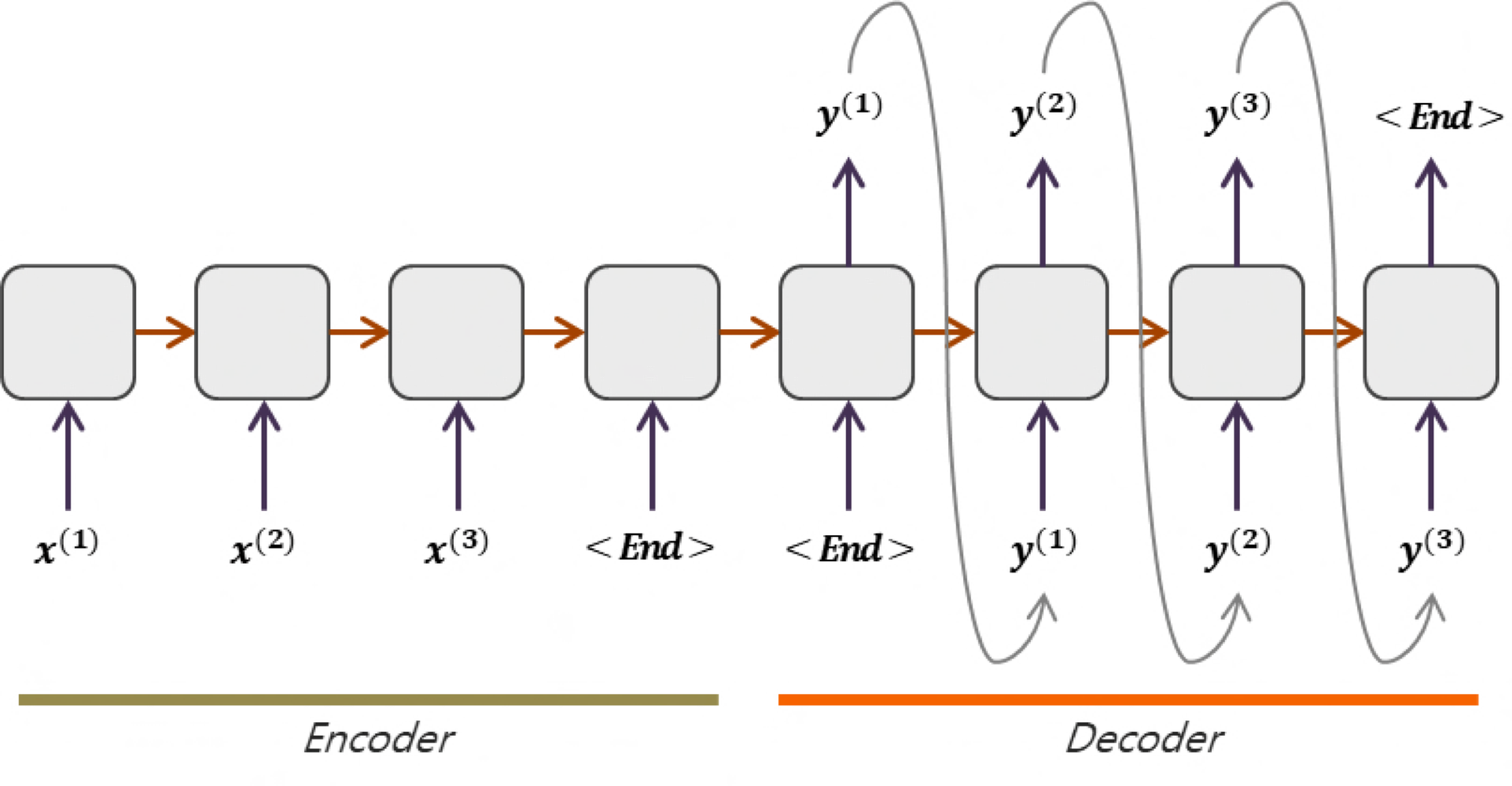
이제 아래에서는 어떻게 transformer가 rnn 구조를 대체할 수 있을만큼 좋은 성능을 보여주었고, attention mechanism이 무엇을 말하는지 하나씩 소개한다. 그전에 transformer 모델의 전체구조는 아래와 같다. 크게 본다면 왼쪽이 transformer의 encoder, 오른쪽이 transformer의 decoder이다. 흔히 사용되는 encoder, decoder와는 다른 기법이 도입되어 있어 혼동되어서는 안된다.
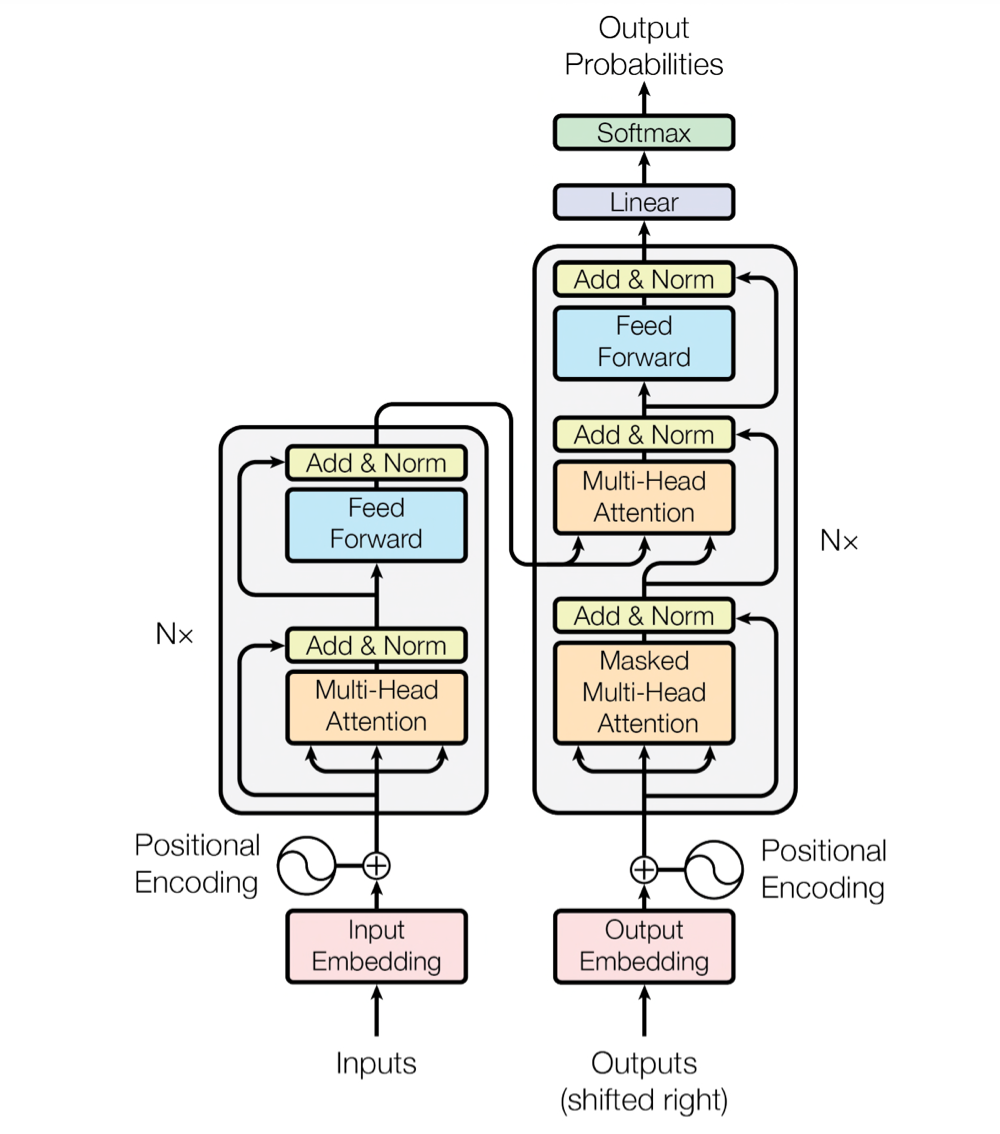
2.1. Encoder and decoder stacks
2.1.1. Encoder
Encoder는 $N=6$개의 동일한 블럭이 쌓인 형태로 구성되어 있다. 하나의 블럭에는 2개의 레이어가 존재하며 첫 번째는 Multi-Head-Attention, 두 번째는 Fully Connected Network이다. 각각의 레이어마다 skip connection이 적용되었으며 동시에 layer normalization도 사용되었다. 여러 개의 블럭이 쌓인 형태로 구성되어 있기 때문에, 입출력 차원을 일치시켜야 하는데 논문에서는 512 차원으로 고정시켰다고 한다.
2.1.2. Decoder
Decoder도 마찬가지로 $N=6$개의 동일한 블럭이 쌓인 형태로 구성되어 있다. 하나의 블럭에는 encoder와 다리 3개의 레이어가 존재하며 첫 번째는 Masekd-Multi-Head-Attention, 두 번째는 Fully Connected Network, 세 번째는 Multi-Head-Attention이다. 마찬가지로 각각의 레이어마다 skip connection과 layer normalization을 사용하였다. Decoder에서는 Multi-Head-Attention이 2번 사용되었는데 그 중 첫 번째 MHA에서 Masking이 들어간 이유는 예측을 할 때 이전 시점의 input들만 활용해서 예측하기 위함이다. Masking을 하지 않으면 실제 정답을 참고해서 언어 번역을 하게 되는 것과 같은 문제를 일으킨다.
2.2. Attention
Attention은 query와 {key, value} 쌍의 데이터를 사용해서 output을 만들어내는 과정이다. 여기서 사용되는 query, key, value는 모두 벡터 형태이며 나중에 여러 개의 단어에 대해서 연산을 수행할 때는 여러개를 묶어 행렬로 표현하기도 한다. Ouput값은 value들의 가중합으로 계산되며, 이때 가중치는 query와 key 사이의 attention score를 사용하게 된다.
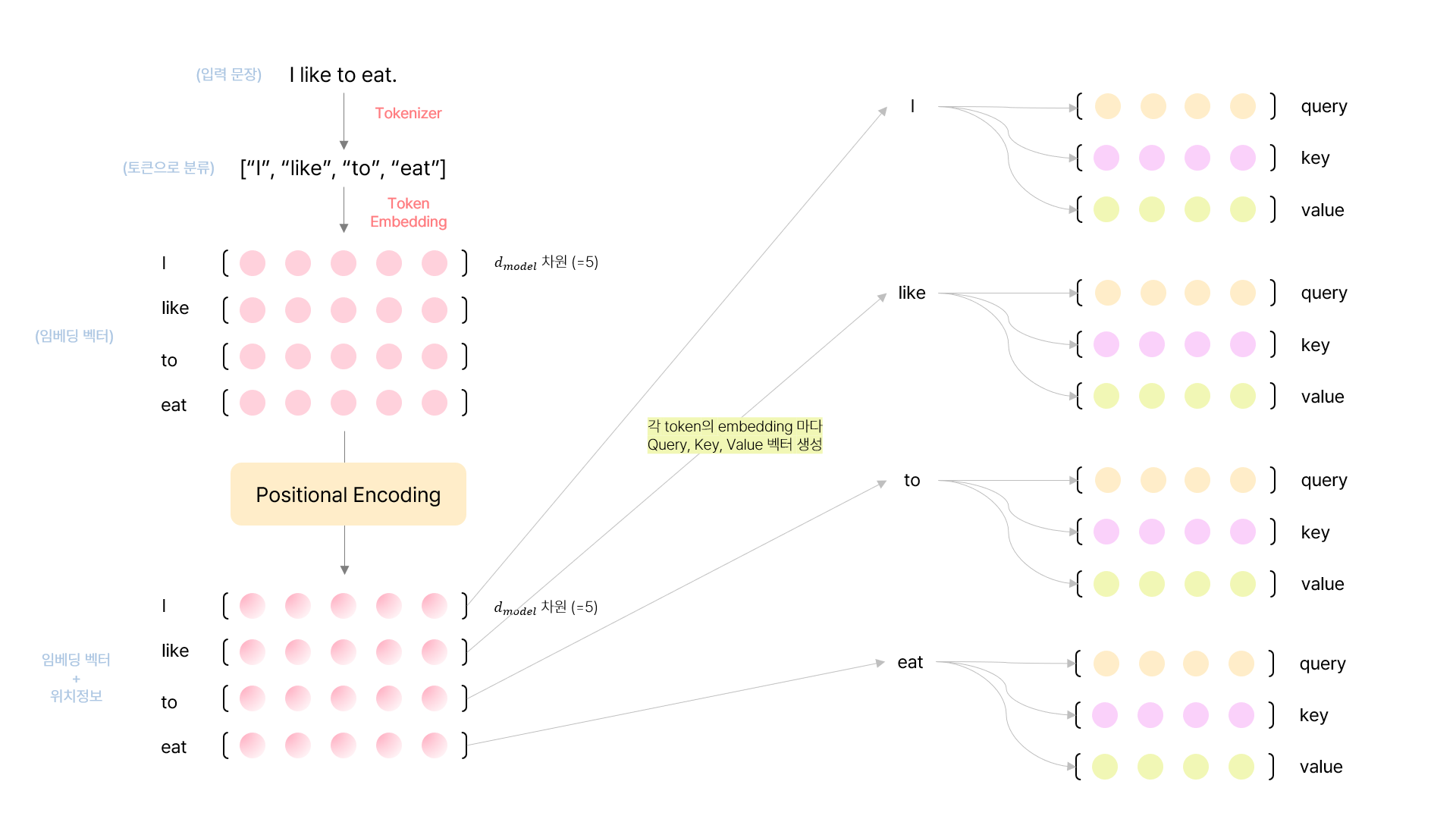
2.2.1. Scaled Dot-Product Attention
Transformer 연구팀은 일반적인 attention을 그대로 사용하지 않고, 특별히 고안한 scaled dot product attention을 사용하였다. 먼저 Scaled dot product attention의 입력은 key 벡터, value 벡터, query 벡터가 있다. 여기서 각각의 벡터들은 $d_k$차원, $d_v$차원 이다. 기존 attention에서는 query와 key 벡터들을 내적한 결과인 유사도 정보만큼을 value에서 뽑아왔다면 scaled dot product는 내적한 결과에 $\sqrt{d_k}$ 로 나누어 주었다고 한다.
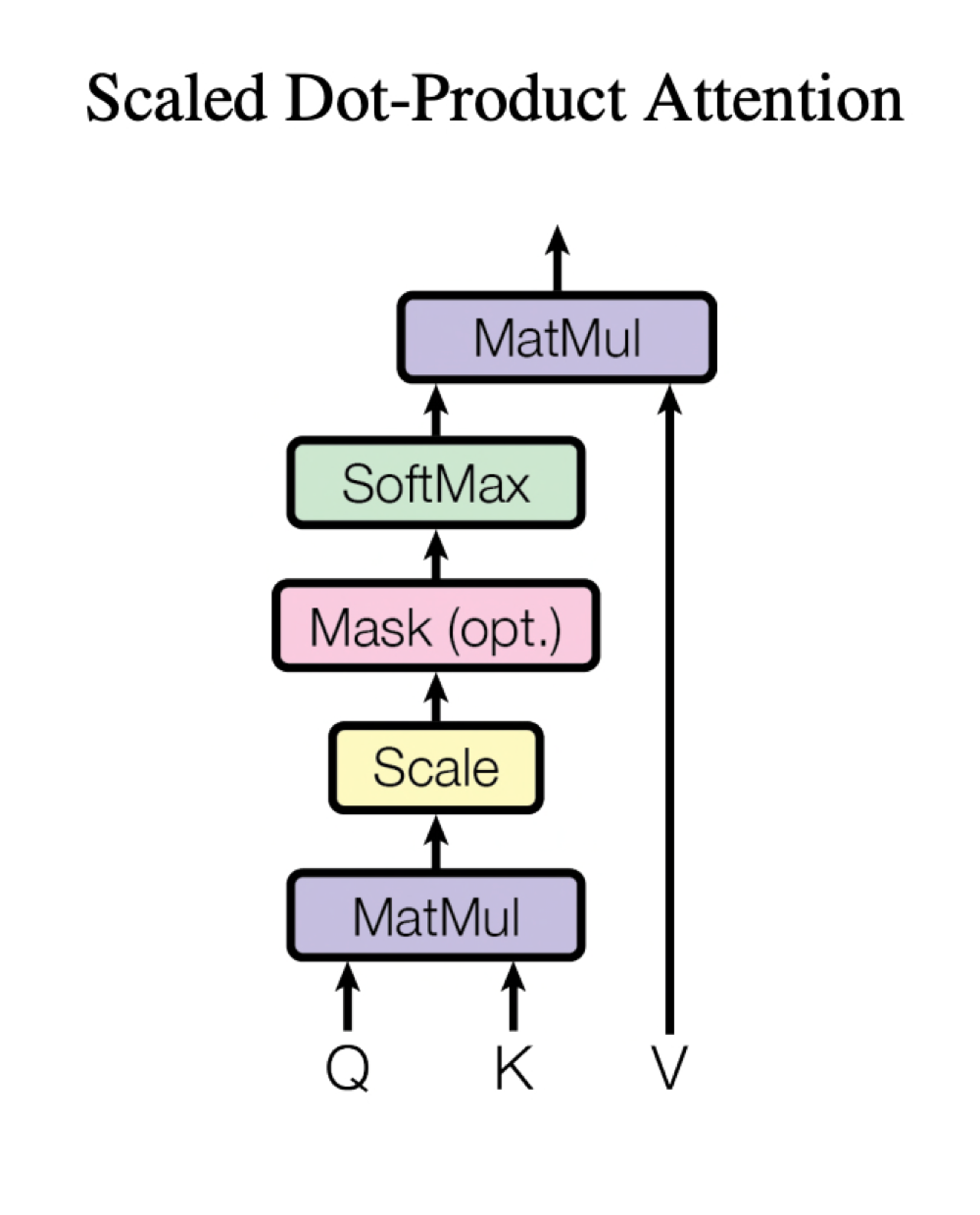
사실 attention을 계산할 때 사용되는 방식은 내적 뿐만 아니라, 더해주는 additive 방식도 존재한다. 하지만, 실제 실행 단계에서 dot product attention이 훨씬 빠르게 작동하고, 적은 메모리 공간을 필요로하기 때문에 저자들이 선택했다고 한다. 기본 attention에 scaling을 해준 것은 작은 $d_k$값에 대해서는 일반 attention과 scaled-dot-attention 모두 유사한 결과값을 보여주지만, 만약 key의 차원 $d_k$가 커진다면 additive attention이 더 좋은 성능을 보여준다. Transformer팀이 의심했던 것은, 내적의 값이 너무 커져 gradient가 0에 가까워져 학습이 제대로 되지 않게 되는 것을 문제삼아 scaling을 해준 것이다.
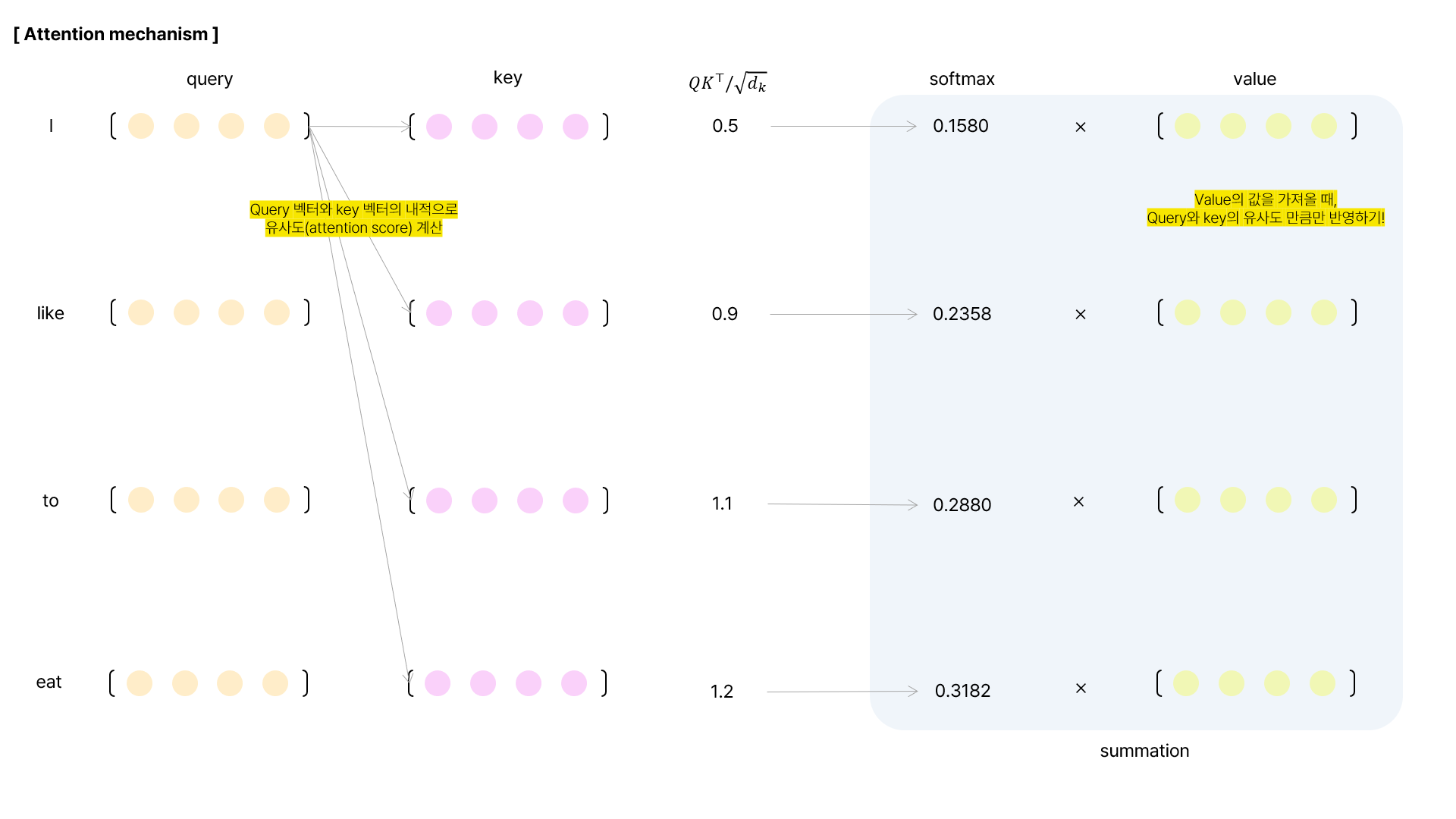
Transformer 논문을 읽으면서 해당 scaled Dot-product-attention에서 2가지 궁금증이 생기게 되었다.
- $d_k$가 아닌, $\sqrt{d_k}$로 scaling 하는 이유?
- Key 뿐만 아니라, Query로 인해서 값이 커질 수도 있는데 왜 Key 벡터에 대해서만 normalize 하는지?
2.2.2. Multi Head Attention
한 번의 단일 attention을 사용하지 않고, 여러 관점에서 문장 사이에 존재하는 관계를 파악하기 위해 여러 번의 attention을 사용하는 것이 multi head attention이다. MHA는 단어들의 관계를 여러 각도에서 바라봐야하기 때문에 기존 Scale dot product attention에서 사용하던 query, key, value를 그대로 사용하지 않고, 1번 linear layer를 거치게 하여 새로운 차원 $d_k’$, $d_q’$, $d_v’$으로 투영시킨다. 모델에서는 투영시킨 횟수를 $h$번이라고 했으며 이는 head의 수를 지칭한다. 각 head에서 나온 결과들은 모두 concatenate하였으며, Transformer 팀은 head의 수로 $h=8$을 사용하였다.
- $W_i^Q$ : $i$ 번째 head의 Query에 대한 projection matrix ($\mathbb{R}^{d_{model} \times d_k}$)
- $W_i^K$ : $i$ 번째 head의 Key에 대한 projection matrix ($\mathbb{R}^{d_{model} \times d_k}$)
- $W_i^V$ : $i$ 번째 head의 Value에 대한 projection matrix ($\mathbb{R}^{d_{model} \times d_v}$)
- $W^O$ : encoder 또는 decoder block의 입출력 차원을 통일 시켜주기 위한 행렬 ($\mathbb{R}^{hd_v \times d_{model}}$)
조금 더 자세하게 사용된 파라미터에 대해서 언급을 하자면, query와 key 벡터의 경우 내적 연산이 이루어져야 하므로, $d_q, d_k$ 차원이 일치해야한다. 또한 논문에서는 각 차원을 512차원으로 설정했고, output 차원은 이전과 같이 64이다.
2.2.3. Applications of Attention in our model
Encoder의 출력과 decoder의 출력을 모두 사용하는 attention의 경우, decoder에 들어가는 attention 입력은 이전 레이어에서 출력으로 내보낸 단어이며, encoder에서 들어가는 입력은 각각 key와 value이다. 이렇게 함으로써, 모든 decoder의 출력이 encoder의 모든 {key, value}들과 한번 씩 대응되면서 비교할 수 있도록 만들어졌다. 이는 기존 RNN구조를 사용한 sequence to sequence 모델의 개념과 일치한다.
2.3. Position-wise Feed-Forward-Networks
Encoder와 decoder 블럭은 각각 Fully Connected Network를 두었고, 이 FFN은 2가지 선형변환과 활성함수를 가지고 있다. FFN은 sequence의 position마다 적용시켰고, 모두 동일한 선형 변환을 거치도록 만들었다. 하지만 총 6개의 블럭에 존재하는 FFN끼리는 다른 가중치를 갖도록 하였다.
\[FFN(x) = \max(0, xW_1 + b_1)W_2 + b_2\]FFN의 필요성은, 모델에 비선형성을 추가해주게 되며 attention 이후에 얻어낸 각 token 간의 정보를 통합하고 특성을 추출하기 위함이다. 덕분에 token들로 부터 모델이 스스로 특성들을 추출하게 되며, 이를 바탕으로 neural machine translation을 하게 된다. 그래도 무엇보다 중요한 것은 활성함수를 통한 비선형성의 추가이다.
2.4. Embedding and Softmax
임베딩과 softmax는 각각 모델의 첫 입력부분과 마지막 출력부분에서 사용된다. 임베딩은 입력 단어 [“I”, “like”, “eating”] 과 같은 글자들을 수치형 데이터로 바꿔주는 역할을 하는데, 논문에서는 이미 pretrained된 파라미터를 가져와서 변환시킨다. 모델의 구조를 다시 보면, 단어 임베딩은 encoder와 decoder의 입력부분에서 모두 사용이 되는 것을 알 수 있는데, 2가지 임베딩은 동일한 가중치를 공유한다고 한다. Decoder 블럭 이후 등장하는 선형변환과 softmax는 실제로 예측할 단어들 중, 어떤 것이 가장 높은 확률 값을 가지고 있는지 해석하기 위해서 사용된다.
Embedding 레이어에서 저자는 사용되는 임베딩 가중치를 $\sqrt{d_{model}}$ 만큼 곱해주었는데, 어떤 것을 목적으로 하여 곱해주었는지 의문이 든다.
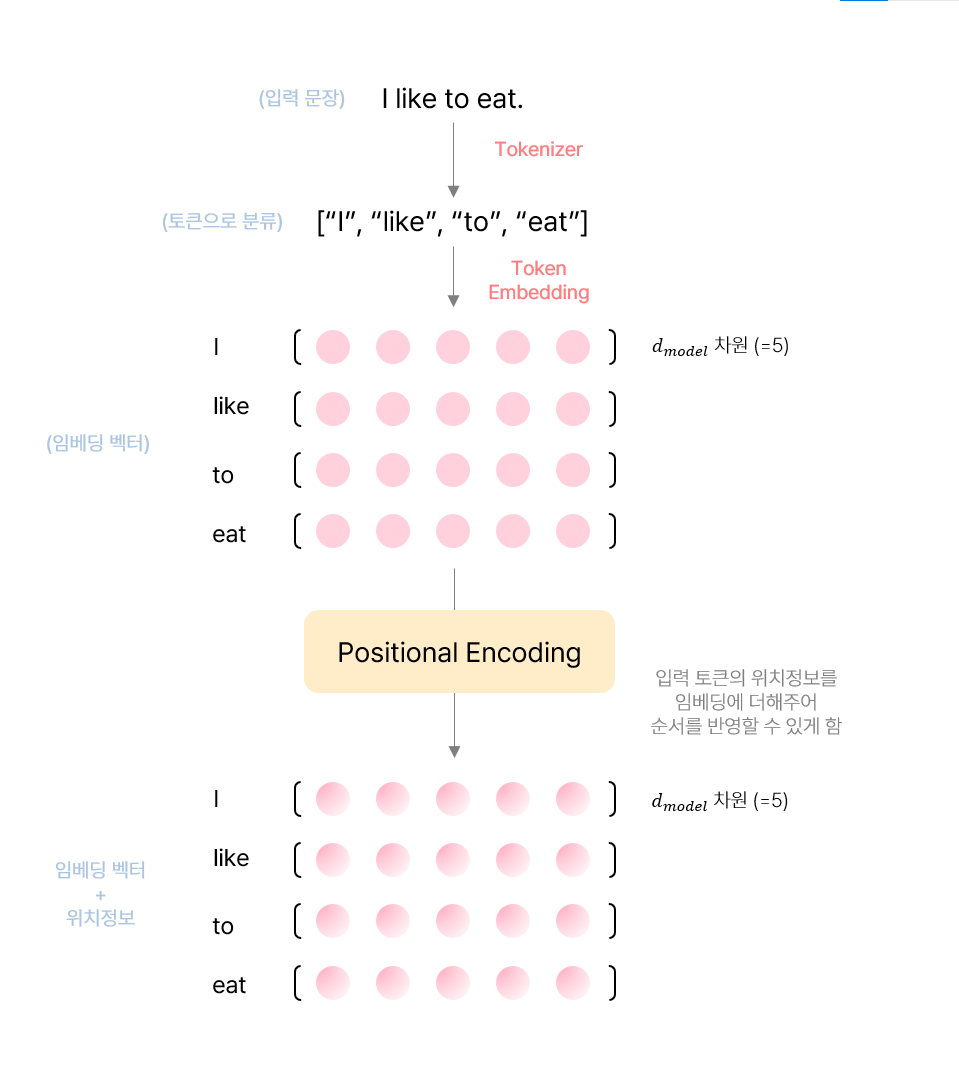
2.5. Positional Encoding
Transformer 모델 구조에는 RNN이나 CNN과 같은 구조를 갖지 않기 때문에 입력 token간의 순서 정보를 고려하지 못한다. 예를 들자면, [“I”, “like”, “eating”]과 [“eating”, “I”, “like”]를 동일하게 해석해버리는 문제가 발생하는 것이다. 그렇기 때문에 인위적으로 순서정보를 모델에 포함시켜줘야 하고, 그 역할을 하는 것이 positional encoding이다.
Positional encoding은 embedding vector에 더해줘서 사용하며, positional vector의 차원은 $d_{model}$로 임베딩 벡터의 차원과 동일하다. Positional encoding에 사용될 수 있는 방법들은 상당히 많이 존재하지만, 논문에서는 서로 다른 주기를 갖는 $\cos, \sin$함수를 사용한 encoding을 하였다.
- $pos$ : 위치 (몇 번째 token인지)
- $i$ : 임베딩의 차원
토큰 임베딩의 차원마다 주기를 갖는 함수가 존재한다고 생각하면 되는데 나는 여기서 1가지 의문점이 들었다. “그냥 직접 단어마다 [1, 2, 3, 4, 5]와 같은 숫자를 부여해 위치를 나태낼 수 도 있을텐데 굳이 주기함수를 사용해 위치정보를 사용하려는 이유는?”. 여기에 대한 답변을 논문에서 해주었다. 저자들도 마찬가지로 위치 임베딩을 별도로 학습하여 부여해보았는데 실제 결과적인 측면에서 거의 동일하였다고 한다. 그럼에도 불구하고 sin함수를 사용한 것은 입력 토큰의 길이가 길어졌을 때도 학습이 원활하게 되는 것을 기대했기 때문이라고 한다.
Positional encoding에 대해서 더 자세히 알아보자면, 서로 다른 위치를 갖는 token은 서로 다른 위치정보를 가지고 있어야한다. 하지만, sine함수는 주기성을 띄기 때문에 동일한 값이 다시 등장할 수 있는 문제점이 발생한다. 이를 해결하기 위해 각 차원에 대해 서로 다른 주기성을 갖는 함수를 사용하였고, sine과 cosine함수를 번갈아가면서 사용하여 모두 다 다른 위치를 encoding할 수 있다.
3. Why self-attention
이번 파트에서는 저자들이 왜 RNN 이나 CNN 대신 self-attention 구조를 사용했는지에 대해 말한다. RNN과 CNN에 비해 self-attention이 갖는 3가지는 간단하게 요약하자면 다음과 같다.
- 레이어마다 요구하는 계산 복잡도가 self-attention이 적다.
- 병렬처리 할 수 있는 계산량이 self-attention이 좋다.
- 긴 입력 sequence에 대해서도 효과적으로 모델링할 수 있다.

Self-attention은 모든 token의 위치들과 비교할 때, 상수시간 $\mathcal{O}(1)$만에 비교가 가능한 반면 RNN구조를 활용하게 되면 $\mathcal{O}(n)$만큼의 연산을 필요로 하게 된다. 특히 이는 $n$을 입력 token의 길이, $d$를 임베딩 벡터의 차원이라고 한다면 $n < d$일 때 더 큰 차이를 보여주는데, 이는 대부분의 machine translation 모델들에 해당된다. 만약 문장의 길이가 너무 길다면 self-attention은 오직 주변 $r$의 단어들만 참고하도록 만들어주어 계산 복잡도를 크게 낮추는것도 가능하다.
4. References
[1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
[2] Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780.
[3] Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. Advances in neural information processing systems, 27.
[4] dProgrammer lopez, RNN LSTM GRU, http://dprogrammer.org/rnn-lstm-gru