Transformer TTS - Neural speech synthesis with transformer network
Transformer TTS: Neural speech synthesis with transformer network
- AAAI 2019
- Li, N., Liu, S., Liu, Y., Zhao, S., & Liu, M.
Abstract
이전 timestep의 예측 값을 필요로 하는 자기회귀(auto-regressive) 모델들은 병렬 처리가 불가능하여 학습 및 추론 과정에서 많은 시간이 소요된다는 단점 이 있습니다. 또한, 입력 오디오의 길이가 길 경우 초기 정보를 잃게 되는 장기 의존성(long-term dependency) 문제도 발생하기도 합니다. 연구팀은 Transformer의 인기를 보고 이를 음성 합성 분야에 적용해 보았고, 그 결과 병렬 처리뿐만 아니라 장기 의존성 문제도 일부 해결하는 데 성공했습니다.
1. Transformer TTS
논문에서 앞서 이야기한 내용을 생략하고 바로 Transformer TTS의 구조를 살펴보겠습니다. 음성 합성에 사용되는 데이터셋은 (음성, 대본) 쌍으로 구성되어 있으며, 입력은 텍스트인 대본, 출력은 음성을 생성하기 위한 설계도인 melspectrogram을 만듭니다. Transformer TTS를 구현하면서 초기에는 많은 실패를 경험했는데, 이는 입력 데이터를 잘못된 방법으로 전처리했기 때문입니다. 모델 구조도 중요하지만 데이터 전처리 과정도 정확하게 하는 것이 중요하다고 느꼈습니다.

1.1. Text to phoneme converter
Text to phoneme converter는 입력 데이터 중 하나인 텍스트를 음소 시퀀스로 변환하는 모듈입니다. 영어 알파벳은 주변에 어떤 알파벳이 등장하는지에 따라 다르게 발음될 수 있다는 특징이 있습니다. 이런 특징을 고려하는 방법 중 하나로 텍스트를 음소(phoneme)로 변환하여 발음대로 기호로 바꿔주는 것이 있습니다. 예를 들어 “This”는 DH / IH1 / S로 변환됩니다. 이후 각 음소는 고유한 정수 값으로 인코딩됩니다. 구현 시 Keith Ito님의 text_to_sequence를 활용할 수 있습니다.
1.2. Scaled positional encoding
Transformer 모델의 특징 중 하나는 입력 시퀀스의 순서 정보를 고려하지 못한다는 점입니다. 이를 해결하기 위해 사인 함수(sinusoidal function)를 사용하여 위치 인코딩을 해줍니다. Transformer TTS 모델에서도 마찬가지로 위치 인코딩을 해줍니다. 여기서 중요한 점은 Transformer TTS의 입력과 출력 도메인이 텍스트와 음성으로 다르다 는 것입니다. 따라서 위치 인코딩을 그대로 사용하면 모델 구조에 강한 제약을 주게 되어, 학습 가능한 파라미터 $\alpha$ 를 사용하도록 변형했습니다.
- $pos$ : timestep
- $2i, 2i+1$ : channel index
- $d_{model}$ : 각 frame 벡터의 차원
1.3. Prenet
Prenet 구조는 이전 논문인 Tacotron2에서 제안된 모듈로, 입력 시퀀스에서 더 긴 문맥을 고려하기 위해 고안되었습니다. 특히 Transformer TTS는 Tacotron2에서 많은 모듈을 차용했는데, Prenet도 그중 하나입니다. Transformer에서는 인코더와 디코더 모두 Prenet이 사용됩니다.
인코더 Prenet은 입력 시퀀스를 전달받아 위치 인코딩을 하기 전에 적용됩니다. 주요 구조는 아래와 같습니다:
- 각 음소에 해당하는 정수 값은 512차원의 임베딩 벡터로 매핑
- 3계층의 CNN으로 구성된 Prenet에 입력되며, 각 레이어의 출력은 512차원
- 레이어마다 배치 정규화, ReLU 활성화 함수, Dropout이 적용
- 마지막으로 1개의 선형 프로젝션 레이어를 두어 positional embedding이 $[-1, 1]$ 사이에 있도록 유도
디코더 Prenet에서는 CNN 대신 Fully Connected Layer을 사용합니다. 주요 구조는 아래와 같습니다:
- 각 레이어는 256개의 hidden unit을 갖으며 ReLU 활성함수와 dropout을 적용
- 연구팀은 512차원으로도 늘려보았지만, 성능향상폭 보다 연산량이 너무 많아져서 비효율적
1.4. Mel Linear, Stop Linear
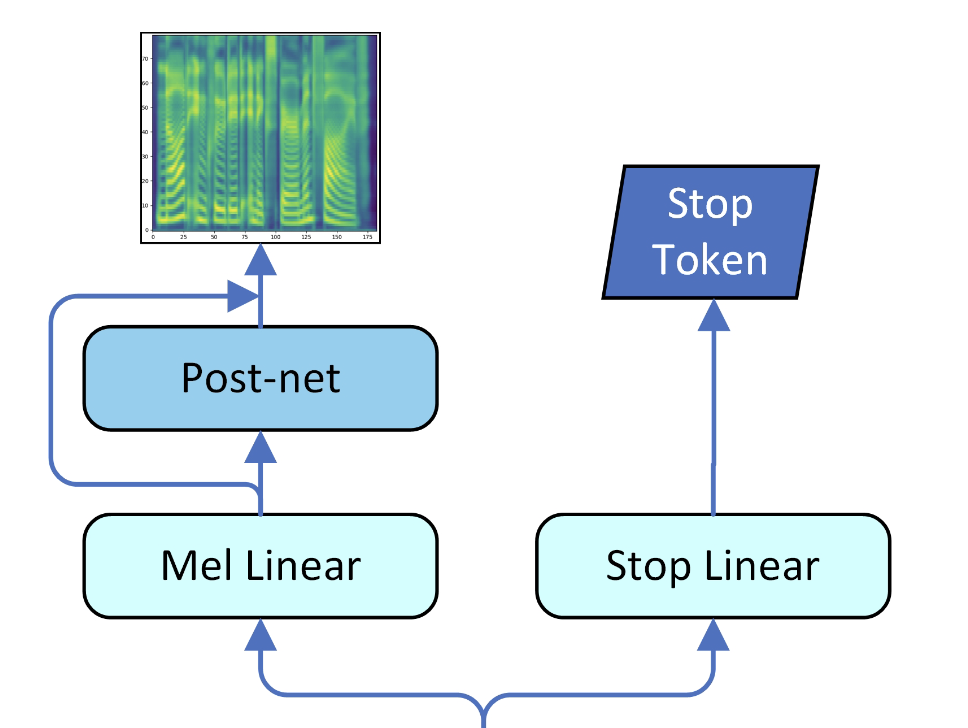
Transformer TTS의 추론 과정은 자기회귀 방식으로 학습됩니다. 따라서 각 시간 스텝마다 mel 프레임을 예측하며 종료 지점인지를 판단 해야 합니다. Tacotron2와 마찬가지로 선형 프로젝션 레이어를 두어 판단합니다. 예측 결과를 mel-scale로 변환해주는 선형 프로젝션 레이어도 존재합니다.
- Linear projection 1: 멜 스펙트로그램을 생성하기 위함 ($d_{model} \rightarrow \text{num mels}$)
- Linear projection 2: stop token을 예측하기 위함
Stop linear에서 종료를 의미하는 토큰은 오직 하나이며, 다른 토큰들은 종료가 아니기 때문에 학습 과정에서 불균형이 발생할 수 있습니다. 따라서 마지막 종료 토큰에 대해 $5.0 \sim 8.0$ 에 해당하는 가중치를 곱하여 BCELoss를 계산합니다.
1
2
3
4
mel_loss = nn.MSELoss(mel_pred, mel_true)
stop_loss = nn.BCELoss(stop_pred, stop_true) * 5.0
loss = mel_loss + stop_loss
1.5. Postnet
위 그림을 보면 mel 선형 레이어 이후 한 번 더 레이어를 거치는데, 이를 Postnet이라고 부릅니다. Postnet의 역할은 예측한 melspectrogram을 한 번 더 정제해주는 것입니다. 구조는 Prenet과 유사하게 5개의 레이어로 이루어진 CNN이며, 결과는 mel 선형 레이어의 결과와 skip connection을 사용해 더해줍니다.
2. Experiment
2.1. Setup
총 4대의 Nvidia Tesla P100을 사용하여 학습하였고, 데이터셋은 25시간 분량의 음성을 사용했습니다. 병렬 처리 효율을 극대화하기 위해 동적 배치 크기(dynamic batch size)를 적용했습니다. 동적 배치 크기는 배치의 크기를 최대한 채워서 구성하는 것을 의미하며, 이로 인해 배치 내에 존재하는 샘플 수가 다를 수 있습니다.
2.2. Evaluation
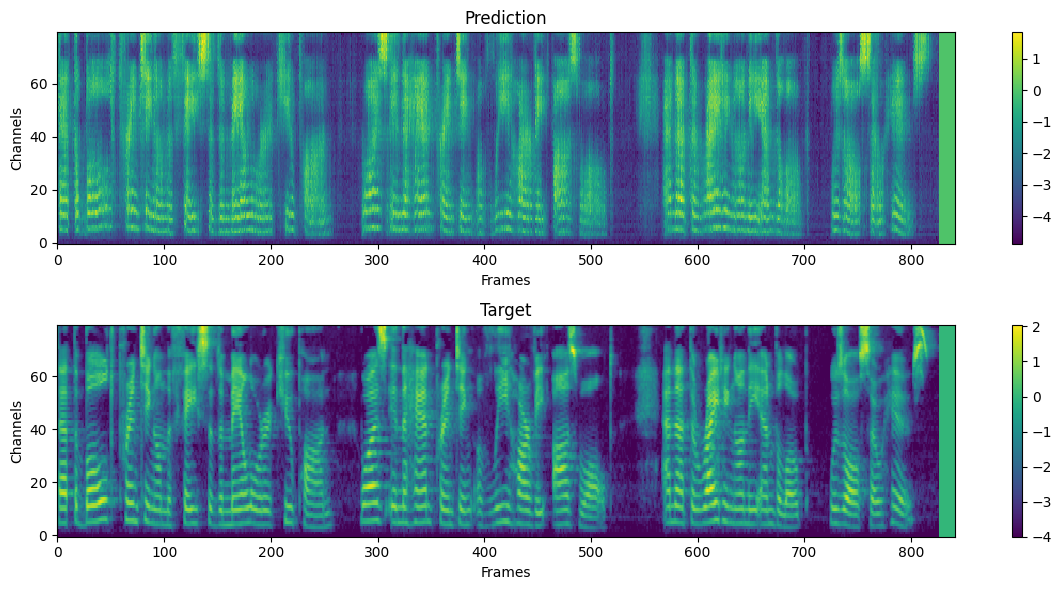
1개 스텝을 학습하는 데 걸리는 시간은 약 0.4초로, 이는 Tacotron2보다 4배 빠른 속도입니다. 평가 지표는 다른 연구와 마찬가지로 MOS(Mean Opinion Score)를 사용했습니다. 생성된 melspectrogram을 시각화해 비교해보면 Tacotron2보다 더 정확하게 세부 사항을 표현했습니다.
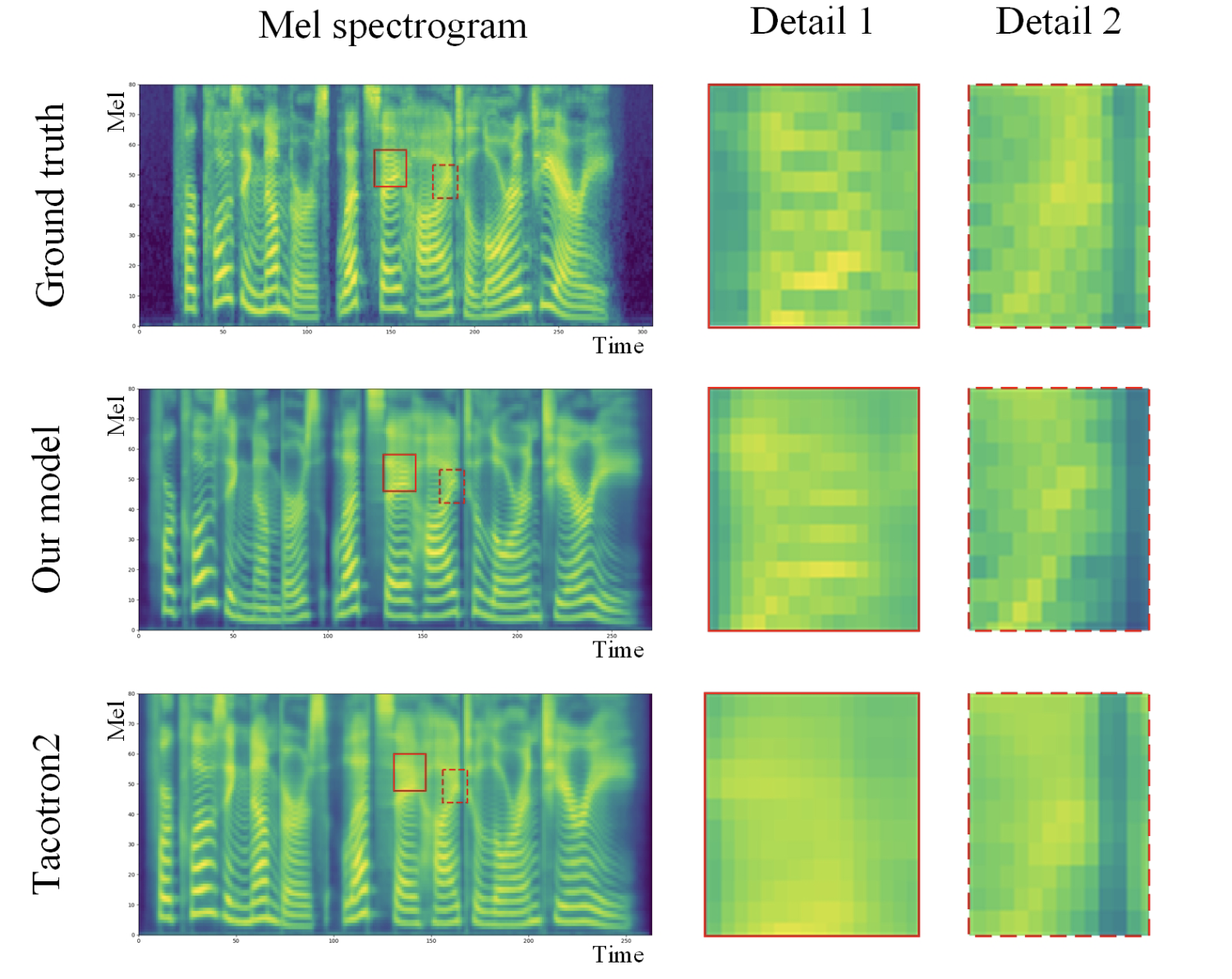
Scaled positional encoding의 성능 평가도 이루어졌는데, 가중치를 곱하지 않았을 때 대비 MOS 점수가 0.03점 상승했다고 발표하였습니다. 연구팀은 이어서 Transformer에 사용되는 헤드의 수, 레이어의 수도 다르게 해보았는데, 레이어는 6개, 헤드의 수는 8개일 때 가장 좋았다고 합니다.
3. Conclusion
전반적으로 Tacotron2와 Transformer 모델을 적절하게 조합한 결과라고 생각됩니다. 그 과정에서 변경 사항도 있었지만, 큰 성능 향상에는 Transformer의 기여가 컸다고 느껴집니다. 개인적으로 Tacotron2의 Prenet이나 Postnet이 음성학적 요소를 더 잘 뽑아내는 데 도움을 주었고, Transformer를 통해 시퀀스 정보를 고려했다고 생각되었습니다. 나름 간단해 보여 구현까지 해보았지만, 쉽지 않은 과정이었으며 데이터셋의 전처리 과정이 상당히 중요하다고 느껴졌으며 아래는 1 epoch만 학습시킨 결과입니다. Google colab 환경에서 실행할 수 있는 노트북은 여기에서 실행해보실 수 있습니다.